







开篇
为什么我会在自己的个人技术博客里发表一些有关雷达通信一体化技术的文章?
因为博主本人是东南大学在读研究生,导师确定下来的研究课题方向就是雷达通信一体化,所以希望能够将自己平时看到的有关雷达通信一体化技术的知识,通过博客的形式向大家展现出来。一方面是为了记录总结自己科研生活的过程,另一方面也是想让更多的人通过我的文章了解到这一领域的发展状态。
雷达通信一体化概述
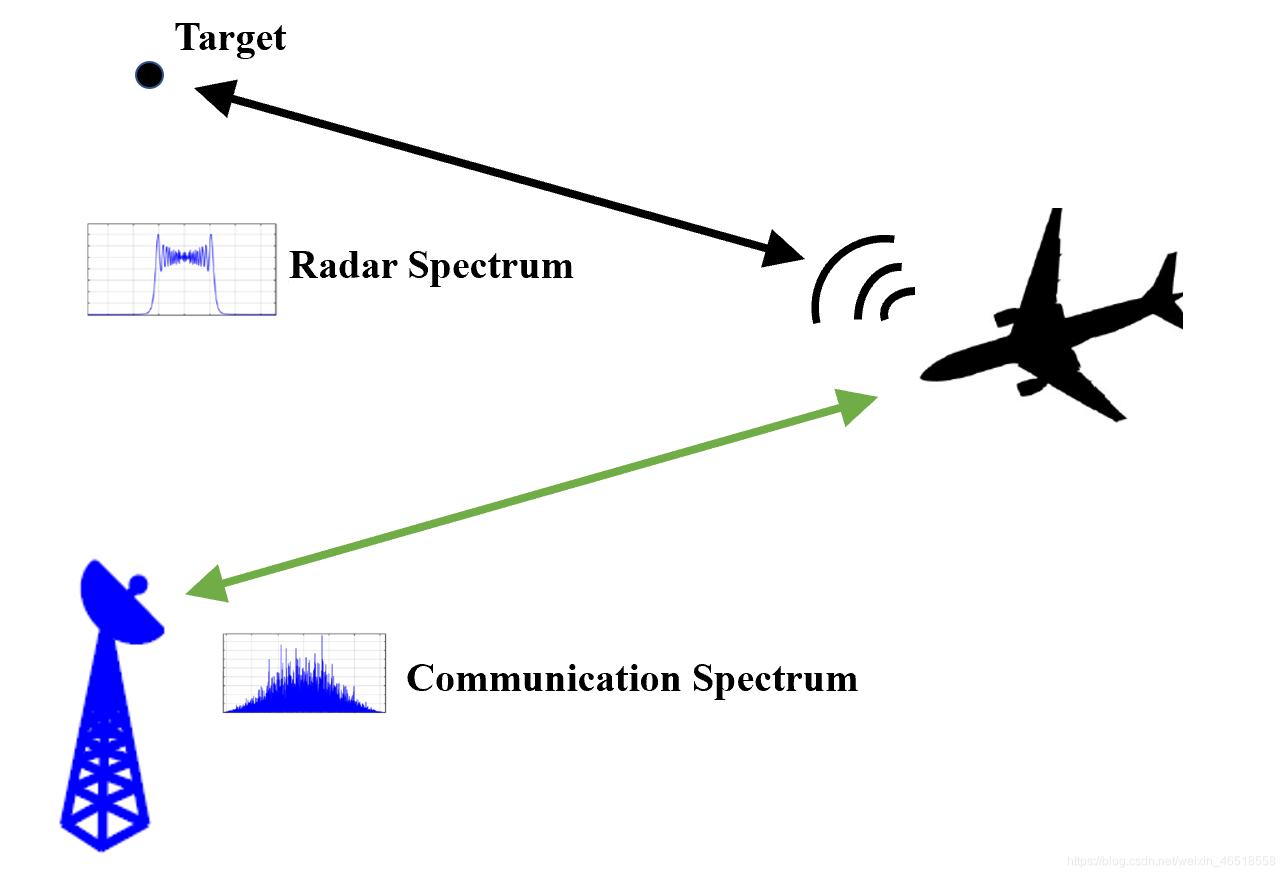
雷达通信一体化,顾名思义就是雷达与通信二者结合的技术,其目的就是把雷达和通信系统通过一定的科学方式集成在一个平台上。在无线电的发展历史上,雷达和通信一直以来是作为两个独立的系统进行开发和研究的。二者一个负责远距离目标的探测,一个负责信息数据的传输。之所以会有融合的需求,我个人觉得有两点原因:
- 当今社会对于小型化,集成化,多功能化产品的追求。
- 无线通信的数据速率越来越快,迫使通信的频段不断被提高。
第1点原因很好理解,因为不仅对雷达与通信而言是这样,日常生活中的手机,电脑等都是一个道理,人们都希望能够在一个简单的平台上实现多样化的功能。第2点原因,伴随着信息时代的发展,不管是军用还是民用领域,数据传输速率越来越高是必然的趋势,所以无线通信要求的带宽也就越来越高。传统上,雷达的工作频段是远高于通信的,但是因为高通信速率导致的通信系统的频段抬高,二者在频域上出现了交叉的现象。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1460
1460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









