







2.1 输入¶
h(w)=w1x1+w2x2+w3x3+,⋯,+b
逻辑回归的输入就是一个线性方程
2.2 激活函数¶
sigmoid函数
g(wT,x)=11+e−h(w)=11+e−wTx
判断标准
- 回归的结果输入到sigmoid函数当中
- 输出结果:[0, 1]区间中的一个概率值,默认为0.5为阈值
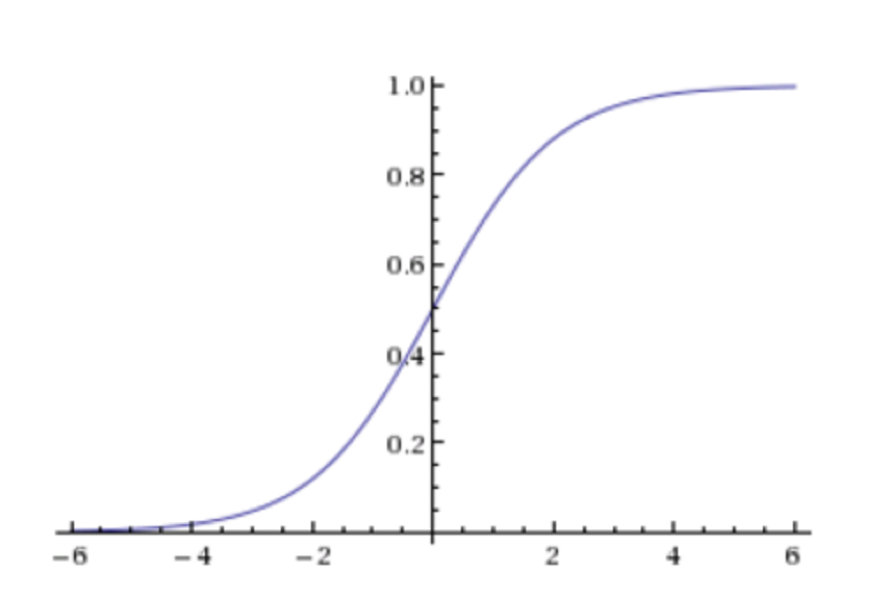
逻辑回归最终的分类是通过属于某个类别的概率值来判断是否属于某个类别,并且这个类别默认标记为1(正例),另外的一个类别会标记为0(反例)。(方便损失计算)
输出结果解释(重要):假设有两个类别A,B,并且假设我们的概率值为属于A(1)这个类别的概率值。现在有一个样本的输入到逻辑回归输出结果0.55,那么这个概率值超过0.5,意味着我们训练或者预测的结果就是A(1)类别。那么反之,如果得出结果为0.3那么,训练或者预测结果就为B(0)类别。
关于 逻辑回归的阈值是可以进行改变的 ,比如上面举例中,如果你把阈值设置为0.6,那么输出的结果0.55,就属于B类。
在之前,我们用均方误差来衡量线性回归的损失
在逻辑回归中,当预测结果不对的时候,我们该怎么衡量其损失呢?
我们来看下图(下图中,设置阈值为0.6),
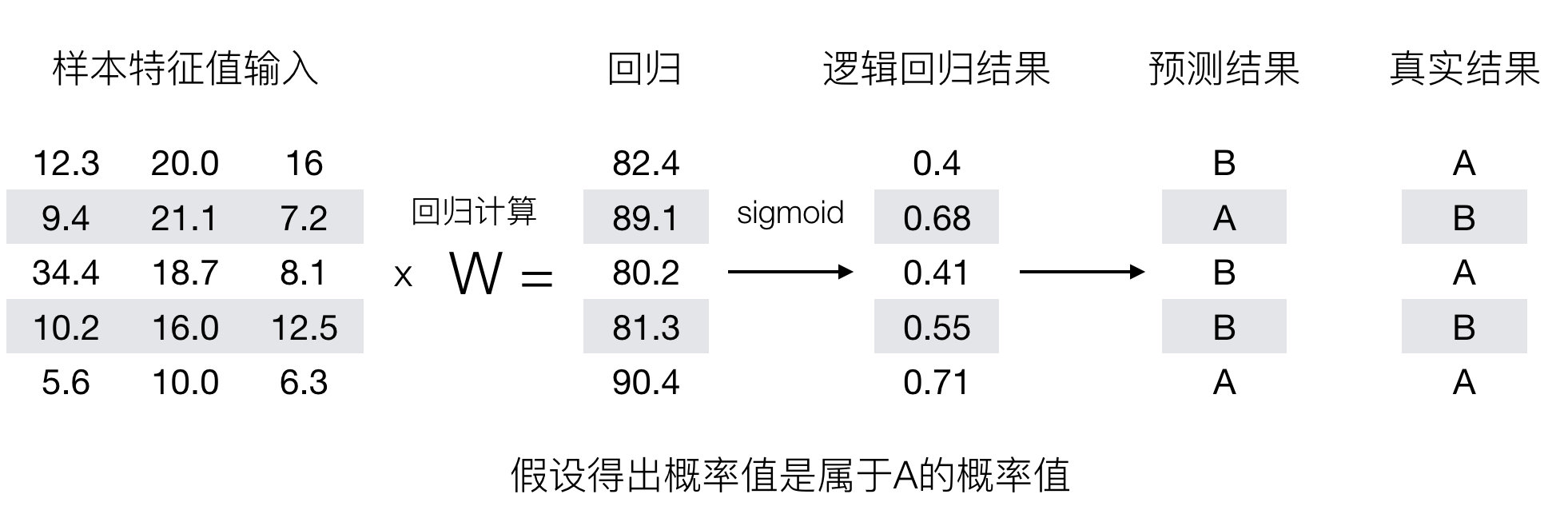
那么如何去衡量逻辑回归的预测结果与真实结果的差异呢?
3 损失以及优化¶
3.1 损失¶
逻辑回归的损失,称之为 对数似然损失 ,公式如下:
分开类别:
cost(hθ(x),y)={−log(hθ(x)),if y=1 −log(1−hθ(x)),if y=0
其中y为真实值,hθ(x)为预测值
怎么理解单个的式子呢?这个要根据log的函数图像来理解

无论何时,我们都希望 损失函数值,越小越好
分情况讨论,对应的损失函数值:
- 当y=1时,我们希望hθ(x)值越大越好;
-
当y=0时,我们希望hθ(x)值越小越好
-
综合完整损失函数
cost(hθ(x),y)=∑i=1m−yilog(hθ(x))−(1−yi)log(1−hθ(x))
接下来我们呢就带入上面那个例子来计算一遍,就能理解意义了。

我们已经知道,-log(P), P值越大,结果越小,所以我们可以对着这个损失的式子去分析
3.2 优化¶
同样使用梯度下降优化算法,去减少损失函数的值。这样去更新逻辑回归前面对应算法的权重参数,提升原本属于1类别的概率,降低原本是0类别的概率。















 792
792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









