






一、实验目的
在pycharm平台上,采用SVM分类器实现人脸识别。在实验过程中:
- 学习应用主成成分分析对特征向量进行提取,并讨论选取前n个成分对识别准确性的影响。
- 增加对SVM的理解,通过调节SVM具有的参数具体分析对识别效果的影响。
- 人脸识别的成功精确度达到90%以上。
二、实验方法
1、从网上下载人脸数据集,并按照不同人脸图片进行分类存储。
2、读取图片并进行主成成分分析,调节选择前n维主成成分,分析各成分方差占比。
3、采用SVM分类器进行分类,调整其中参数,(包括:核函数,惩罚系数,多分类方法等)分析对结果的影响。
三、实验结果
- 下载Olivetti Faces人脸数据集得到一张包含20*20张人脸图片,如下:

- 2、进行图像分割后按不同人物将图片分别存入不同文件夹中,效果如下:(具体实现请看另一篇:https://blog.csdn.net/weixin_46579610/article/details/120967783)

- 3、读取图片进行主成成分分析
蓝点是各成分方差的占比,红线是各成分方差占比的积累。
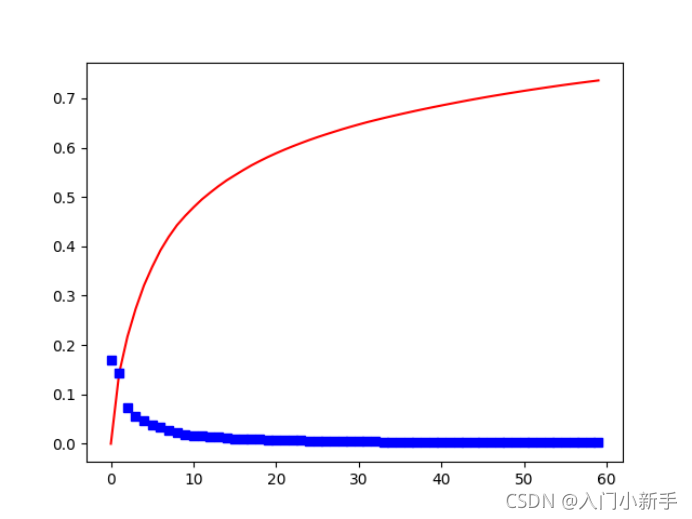
从图中可以看出,各成分方差占比不断下降,当达到n=32左右后方差占比趋近于0,另外,n=32时,方差的积累已经达到了70%左右,其后增加的也很缓慢,所以对PCA的参数n可以在n=30以内调整分析即可。
- 在相同的SVM模型下(惩罚系数C=0.1,核函数=Linear,多分类方法=ovo),设置不同的PCA(主成成分分析方法)的参数n,对比训练和测试准确度。
| n | 训练准确度(train_rate) | 测试准确度(test_rate) | 前n维方差占比 |
| 3 | 0.94 | 0.67 | 0.217 |
| 5 | 1.00 | 0.91 | 0.323 |
| 8 | 1.00 | 1.00 | 0.420 |
| 20 | 1.00 | 1.00 | 0.587 |
从上表可以看出,在此问题下,只需要使用特征向量较少的信息量(方差占比)就可以实现较好的分类效果,n=8时,训练和测试的准确度已经达到100%。
- 在相同的PCA的参数n(n=5)条件下,调整SVM的参数:
| 惩罚系数C | 核函数 | 多分类方法 | 训练准确度 | 测试准确度 |
| 0.1 | linear | ovo | 1.00 | 0.916 |
| 1.0 | linear | ovo | 1.00 | 0.917 |
| 2.0 | Linear | ovo | 1.00 | 0.917 |
| 0.1 | poly | ovo | 0.386 | 0.267 |
| 0.1 | rbf | ovo | 0.178 | 0.083 |
| 0.1 | linear | ovr | 1.00 | 0.916 |
从上表可以看出,惩罚系数C和多分类方法在此问题下对实验结果影响不大;而核函数的选取很重要,使用线性核函数可以达到很好效果,而此问题不适合使用多项式和径向基核函数。
-
结果讨论
1、本实验证明了SVM方法可以很好的解决样本数量较少的分类问题,在这次实验中,用到的全部数据集只有20*10张图片,即有20个人物,每个人物只有10张图片,但SVM仍然很好地完成了分类任务,甚至可以达到100%的训练和测试成功率。其中原因和SVM的理论有关,因为在SVM中,只有位于分类边缘的特征向量(即支持向量)对分类面有影响,所以SVM不需要特别多的数据。
2、本实验证明了特征提取的必要性,训练和测试的特征不是越多越好,更多的特征不仅增加了计算量而且会降低分类的质量。通过特征提取可以将关键的信息提取出来,更有利于进行分类。在本实验中通过主成成分分析可视化的看到各个分量所含的信息占比,并且使用较少的信息(n=8时占比为0.42)就可以达到很好的效果,相比于将原图的特征向量直接传入SVM,极大的减小了运算量。
3、对SVM方法,核函数的选取极其重要,并不是越复杂的核函数效果越好,需要具体问题具体尝试后选取最佳。在本实验中,使用最简单的线性核函数反而可以实现更好的效果。
-
结论
对实际问题要具体分析,不要因为目前神经网络很热门就认为神经网络可以解决所有问题而忽视了其他机器学习方法。相比于神经网络,SVM有其无法比拟的优点:实现简单,计算量小,需要数据量少,调参简单,优秀的泛化能力等。
具体代码如下
# 导入模块
import cv2 # openCV 模块 用于图像处理
import numpy as np
from sklearn.model_selection import train_test_split # 用于切分训练集和测试集
from sklearn.decomposition import PCA # PCA降维
from sklearn.svm import SVC # 支持向量机
import matplotlib.pyplot as plt
data = [] # 存放图像数据
label = [] # 存放标签
# 读取20*10张图片
for i in range(1, 21):
for j in range(1, 11):
path = 'img' + '/' + str(i) + '/' + str(j) + '.jpg'
img = cv2.imread(path, -1)
h, w = img.shape
# 将图片转化成列表
img_col = img.reshape(h * w)
data.append(img_col)
label.append(i)
# 将图片列表转化成矩阵类型
C_data = np.array(data)
C_label = np.array(label)
# 切分训练集和测试集,参数test_size为测试集占全部数据的占比
x_train, x_test, y_train, y_test = train_test_split(C_data, C_label, test_size=0.3, random_state=256)
# 主成成分分析,参数n_components为取前n维最大成分
n = 5
pca = PCA(n_components=n, svd_solver='auto').fit(x_train)
# 形象化展示各个成分的方差占比,即主成成分分析的本征图谱和累积量
a = pca.explained_variance_ratio_
b = np.zeros(n)
k = 0
for i in range(1, n):
k = k + a[i]
b[i] = k
# 作图
plt.plot(b, 'r')
plt.plot(a, 'bs')
plt.show()
# 将训练和测试样本都进行降维
x_train_pca = pca.transform(x_train)
x_test_pca = pca.transform(x_test)
# 使用SVM模型进行分类,
svc = SVC(C=0.1, kernel='linear', decision_function_shape='ovr')
svc.fit(x_train_pca, y_train)
# 获得训练精确度
print('训练准确度:')
print('%.5f' % svc.score(x_train_pca, y_train))
# 获得测试精确度
print('测试准确度:')
print('%.5f' % svc.score(x_test_pca, y_test))













 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









