






- 模型评估与选择
错误率与精确率 训练误差与泛化误差 训练误差低≠泛化误差低⟹ 欠拟合(训练的不够)与过拟合(训练的太好NP≠P)
- 评估方法:通过与训练集数据不同的验证集来进行评估
1)留出法: 直接将数据集分割为训练集和验证集,常选用2/3~4/5作为训练集
2)交叉验证法:将数据集分成k个互斥的子集,每次选取其中一个作为验证集,其他的作为训练集,最终取k个分组的测试结果的平均值
3)自助法:每次从数据集D中随机抽取一个样本放入D1 中,然后放回数据集D,如此重复m次,数据集样本中始终不会被取到的概率是1/e。
2.性能度量 衡量模型泛化能力的标准
回归任务中最常用的就是均方误差:
E(f;D)=
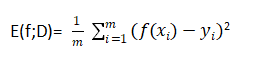
2
1)分类任务常用的是错误率和精确率:

2)(需求:比如信息检索领域,检测有多少比例的信息是用户感兴趣的)

| 真实 预测 | 正例 | 负例 |
| 正例 | TP | FP |
| 负例 | FN | TN |
PR曲线说明,查准率与查全率往往是矛盾的,不能兼得。如果一条曲线包裹中另外一条则该曲线对应的学习器优于另一个(比如A,B优于C)。对于相交的曲线可以用平衡点(BEP)来衡量,如图A优于B

BEP比较简单,往往不能满足需求,还有F1,F1一般化Fβ(对于查准率与查全率的偏重不同)。
多分类问题:n个二分类混淆矩阵中衡量查准率、查全率、F1
宏查准率(分别求每个混淆矩阵P然后求平均值):![]()
宏查全率(分别求每个混淆矩阵R然后求平均值):![]()
微查准率(对混淆矩阵的每个对应元素求平均,然后算P):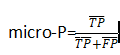
微查全率(对混淆矩阵的每个对应元素求平均,然后算R):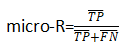
- ROC与AUC (排序质量的好坏反映了学习器对于一般情况下泛化性能的好坏,ROC从该角度出发)
 点(0,1)为理想模型,对角线为随机模型。如果要衡量两条相加曲线学习器优劣,可以计算阴影面积AUC。
点(0,1)为理想模型,对角线为随机模型。如果要衡量两条相加曲线学习器优劣,可以计算阴影面积AUC。

AUC计算公式:
![]()
排序损失定义(曲线上方面积):

4)代价敏感错误率与代价敏感曲线(不同类型预测错误产生后果不同)

在非均等代价下,ROC曲线不能反映出学习器好坏,但是代价曲线可以实现。
横轴为正例概率代价(p是样例为正例的概率):
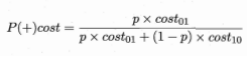
纵轴为归一化代价(FNR=1-TPR):

代价曲线:
















 993
993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









