









文件系统调用
本文接着上文系统调用,也是接着 x v 6 xv6 xv6 文件系统的最后一层,讲述各种具体的文件系统调用是怎么实现的,文件描述符, i n o d e inode inode,文件之间到底有什么关系,创建打开关闭删除文件到底是何意义,文件删除之后数据就不存在了吗,链接又作何解释等等问题,看完本文相信你能找到答案。
基本数据结构
前面的文章捋一捋文件系统中曾提到过, L i n u x Linux Linux 里会为每一个打开的文件维护两张表,一个是系统级的打开文件表,简称为文件表。还维护了一张进程级的打开文件表,且称为文件描述符表。
每一个打开的文件都使用一种数据结构:文件结构体( s t r u c t f i l e struct file structfile)来表示,打开一个文件就会在文件表中创建/分配一个文件结构体。文件描述符表就是一个指针数组,其元素指向文件表中的文件结构体,而这个数组的索引就是常说的文件描述符。
来看这些数据结构的定义:
文件结构体
struct file {
enum { FD_NONE, FD_PIPE, FD_INODE } type; //文件类型
int ref; // reference count //引用数
char readable; //可读?
char writable; //可写?
struct pipe *pipe; //该文件是个管道
struct inode *ip; //该文件是个“inode”型文件
uint off; //读写文件时记录的偏移量
};
这就是文件结构体的定义,它主要记录了对文件操作方面的信息,比如读写权限,读写时的偏移量等等。具体的字段意义我们放在后面需要,这里先把几个基本的文件数据结构过一遍。
文件表
struct {
struct spinlock lock;
struct file file[NFILE];
} ftable;
#define NFILE 100 // open files per system
文件结构体集合在一起就是文件表,它是系统的全局数据,整个系统只有一张文件表,所有进程都可以访问,所以配了一把锁避免竞争条件。根据定义,可以看出 x v 6 xv6 xv6 这个系统最多支持打开 100 100 100 个文件。
分配文件结构体
struct file* filealloc(void) //分配一个文件结构体
{
struct file *f;
acquire(&ftable.lock);
for(f = ftable.file; f < ftable.file + NFILE; f++){
if(f->ref == 0){ //如果该文件结构体的引用数为0则说明空闲可分配
f->ref = 1; //新分配的,引用数为1
release(&ftable.lock);
return f; //返回文件结构体的指针
}
}
release(&ftable.lock);
return 0;
}
这是分配文件结构体的函数,很简单,先加锁,然后从前置后依此寻找空闲的文件结构体。判断文件结构体是否空闲就是看这个文件结构体的引用数是否为 0。为 0 表示空闲可以分配出去,反之不能继续向后找空闲的文件结构体。找到之后释放锁然后返回该空闲文件结构体的指针,反之没找到的话就释放锁返回 0。引用数表示该文件结构体被引用的次数,具体含义见后面属性字段辨析。
文件描述符表、文件描述符
struct proc {
uint sz; // Size of process memory (bytes)
pde_t* pgdir; // Page table
char *kstack; // Bottom of kernel stack for this process
enum procstate state; // Process state
int pid; // Process ID
struct proc *parent; // Parent process
struct trapframe *tf; // Trap frame for current syscall
struct context *context; // swtch() here to run process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
};
文件描述符表是每个进程有一张,既然是为每个进程都会维护一个文件描述符表,那么这个数据结构便应该定义在进程控制块里面。虽然进程咱们还没说,但是经过前面的中断,文件系统等铺垫,这个进程控制块的元素多多少少我们都见过了。
文件描述符表的定义就是:
struct file *ofile[NOFILE]; // Open files
#define NOFILE 16 // open files per process
可以看出文件描述符表就是一个指针数组,其索引就是文件描述符,所以文件描述符就是一个整数,其元素就是个地址,指向的文件表中的文件结构体。每个进程最多支持打开 16 16 16 个文件,每打开一个文件就会在文件表中分配一个文件结构体,然后文件描述符表中同样的分配一个描述符,该位置上填写的刚分配的文件结构体的地址。
分配文件描述符
static int
fdalloc(struct file *f)
{
int fd;
struct proc *curproc = myproc(); //当前进程控制块的地址
for(fd = 0; fd < NOFILE; fd++){
if(curproc->ofile[fd] == 0){ //如果该描述符对应的元素为0则空闲可分配
curproc->ofile[fd] = f; //填写文件结构体地址
return fd; //返回文件描述符
}
}
return -1;
}
分配文件描述符的方式与分配文件结构体的方式类似,就是从前置后地寻找空闲的文件描述符,判断是否空闲就是看该位置上的元素是否为 0。因为文件描述符表就是个指针数组,为 0 就表示指向为空,所以空闲可以分配出去。
这个函数里面实现了文件描述符、文件结构体之间的绑定,就是将文件结构体的地址写到文件描述符这个位置上。
这也说明了,为什么每次分配的文件描述符相对于当前来说都是最小的,就是因为分配的文件描述符的方式是从前往后的依次寻找空闲可用的描述符。
值得一提的是对比分配文件结构体和文件描述符会发现,分配文件描述符并没有加锁,这是因为文件表是所有进程共享的资源,而文件描述符表是进程私有的。
属性字段辨析
这里来解决前文遗留的一些问题,在前文@@@@@@@@@@@@我们聊过 i n o d e inode inode 的一些属性字段,当时有些地方只是简单提了几句,说是后面详述。后面就是指本文了,这里我们将 i n o d e inode inode 和文件结构体结合在一起看,再贴一次 i n o d e inode inode 结构体定义:
struct inode {
uint dev; // Device number
uint inum; // Inode number
int ref; // Reference count
struct sleeplock lock; // protects everything below here
int valid; // inode has been read from disk?
short type; // copy of disk inode
short major;
short minor;
short nlink;
uint size;
uint addrs[NDIRECT+1];
};
文件类型
i n o d e inode inode 与文件一一对应,记录的是文件的一些元信息,比如文件的大小链接数等等。而文件结构体是打开文件时创造的,更倾向于记录对文件操作的一些信息,比如读写权限,读写时的偏移量等等。
两种数据结构中有些属性名称上有重复,它们是否为同一个东西呢?答案不是,比如文件结构体中的文件类型,定义了 F D _ N O N E FD\_NONE FD_NONE, F D _ I N O D E FD\_INODE FD_INODE, F D _ P I P E FD\_PIPE FD_PIPE 三种类型,分别表示 无, i n o d e inode inode 型,管道型的文件, x v 6 xv6 xv6 里会根据文件结构体里面的文件类型来使用不同的操作方法。后面可以看到对于 i n o d e inode inode 类型的文件会通过 i n o d e inode inode 的方法来对文件进行操作,而 p i p e pipe pipe 类型的文件通过其特有的管道方法对一块内存区域进行操作。
在 i n o d e inode inode 中也定义的有文件类型: T _ D I R T\_DIR T_DIR, T _ F I L E T\_FILE T_FILE, T _ D E V T\_DEV T_DEV,分别表示目录文件,普通文件,设备文件。 x v 6 xv6 xv6 里这几种文件都可以使用 i n o d e inode inode 的方法对文件进行操作,比如读写数据等等。
在 L i n u x Linux Linux 里,共有 7 种类型的文件:普通文件,目录文件,块设备文件,字符设备文件,套接字文件,管道文件,链接文件。对这 7 种类型文件没有分开表示,在 i n o d e inode inode 里有 m o d e mode mode 字段专门来表示文件的类型和权限。而且有关文件的几个重要的数据结构都有自己的方法字段 o p op op,根据不同的操作对象来调用不同的操作方法。
文件计数
文件的 i n o d e inode inode 中维护了两个计数值,一个是链接数 n l i n k nlink nlink,一个是引用数 r e f ref ref。 n l i n k nlink nlink 可以看作是磁盘级关于文件的计数,其本质是有多少个目录项指向该文件。 r e f ref ref 可以看作是内存级关于文件的计数,引用数就是说某个地方在使用该文件的 i n o d e inode inode,一般来说普通文件的引用数也是可以当作文件的打开次数。
这两个计数值任意一个值不为 0 时,我们认为该文件存在,当两者都为 0 的时候,我们则认为该文件不存在了,可以回收该文件所占用的资源,如 i n o d e inode inode 和数据块,也就是删除该文件。所以删除文件的条件为 r e f = = 0 & & n l i n k = = 0 ref == 0\ \&\&\ nlink == 0 ref==0 && nlink==0,这在后面的函数中会具体讲解。
而文件结构体中也有一个引用数属性,这与 i n o d inod inode 中的引用数是否为同一个东西呢?不是的,两种不同数据结构的引用次数含义当然不一样, f i l e → r e f file \rightarrow ref file→ref 表示引用该文件结构体的次数,主要包括两部分。一是引用该文件结构体的进程数,通常因为 f o r k fork fork 系统调用, f o r k fork fork 会复制父进程的文件描述符表,其元素指向文件结构体,所以 f o r k fork fork 之后,父进程涉及到的文件结构体引用数增加。二是同一个进程的不同文件描述符也可能指向相同的文件结构体使其引用数增加,这通常是通过 d u p dup dup 系统调用实现的。
文件系统调用
关于文件的数据结构和其属性就说那么多,大都应该都比较好理解,一些比较晦涩的我们在实际的函数中来理解。有关文件的一些基本操作比如获取释放 i n o d e inode inode,路径解析在前文@@@@@@@@@@@@@已经讲过,本文不再赘述,本文在这之上接着前文 系统调用 @@@@@@@@@@@@@@@@讲述一些常见的文件系统调用是如何实现的。
这里简单的再过一下系统调用,
x
v
6
xv6
xv6 的系统调用使用 INT 64 指令来实现的,触发一个
64
64
64 号中断陷入内核,根据向量号
64
64
64 去获取执行中断服务程序。在执行系统调用之前传入了系统调用号,在中断服务程序中根据系统调用号获取执行内核功能函数。
执行内核功能函数需要取参数, x v 6 xv6 xv6 系统调用的参数传递方法是压栈,压的是用户栈,所以要去用户栈去参数,关于取参设计了下面三个函数
int argint(int n, int *ip);
从用户栈中获取第 n n n 个参数( i n t int int 型变量),存在 ∗ i p *ip ∗ip 里
int argptr(int n, char **pp, int size);
从用户栈中获取第 n n n 个参数指针,放在 ∗ p p *pp ∗pp 中, s i z e size size 用来条件检查的,这里为什么使用二级指针请看前文系统调用如何实现@@@@@@@@@@
int argstr(int n, char **pp);
从用户栈中获取第 n n n 个参数字符串(地址值),放在 ∗ p p *pp ∗pp 里,为什么使用二级指针同样看前文。
上面就是对前文系统调用的简述,省去了很多细节,有了这些了解之后来具体看看文件系统调用也就是上面所说的内核功能函数如何实现的。
l i n k link link
本来打算先说创建打开文件的,但是需要用到链接数的概念,所以就先把 l i n k link link 系统调用说了吧,后面讲述这些函数也就不按照什么正常的逻辑顺序了,根据实现涉及的概念先后多少来吧。
①函数原型:
int link(const char *oldname, const char *newname);
o l d n a m e 、 n e w n a m e oldname、newname oldname、newname 都是路径, l i n k link link 系统调用创建一个硬链接, l n ln ln 命令创建硬链接就是使用 l i n k link link 系统调用实现的,它使得 n e w n a m e newname newname 文件名链接到 o l d n a m e oldname oldname 指向的文件。主要做两件事:
- 新路径下增加一个目录项指向旧路径下的文件
- 文件的链接数加 1
②函数实现:
int sys_link(void)
{
char name[DIRSIZ], *new, *old;
struct inode *dp, *ip;
/***函数太长分开叙述***/
}
什么是链接?一个文件一个 i n o d e inode inode,两者一一对应,但是没有规定文件名和 i n o d e inode inode 一一对应吧。所以链接其实就是多个文件名指向同一个文件,使用同一个 i n o d e inode inode。 i n o d e inode inode 中没有文件名属性,文件名属性在目录项中,所以从实现的本质上来讲一个文件的链接数就是有多少个目录项指向该文件。
来看看 x v 6 xv6 xv6 中具体是如何实现的:
if(argstr(0, &old) < 0 || argstr(1, &new) < 0) //取参数文件名
return -1;
l i n k link link 系统调用需要两个参数路径,这两个参数在执行系统调用之前被压倒了用户栈,所以在这 s y s _ l i n k sys\_link sys_link 函数里需要先去把参数给取过来。这里就是两个路径 o l d 、 n e w old、 new old、new,路径的末尾就是要链接在一起的文件名。
begin_op();
if((ip = namei(old)) == 0){ //获取old文件的inode,如果不存在返回
end_op();
return -1;
}
ilock(ip); //锁上该inode,顺便使其数据有效
if(ip->type == T_DIR){ //如果类型是目录返回
iunlockput(ip);
end_op();
return -1;
}
调用
n
a
m
e
i
namei
namei 路径解析
n
e
w
new
new,返回其表示的文件
i
n
o
d
e
i
p
inode\ \ ip
inode ip,如果不存在 return -1,如果是个目录文件 return -1。使用
l
i
n
k
link
link 来链接的文件应该是普通文件,目录文件在创建目录的时候创建链接,这个后面会说到。
文件系统调用前后使用日志来保证原子性,对 i n o d e inode inode 上锁使用,使数据有效,情况不对解锁并释放掉。对于 i n o d e inode inode 的操作都是如此, i g e t iget iget 与 i p u t iput iput , l o c k lock lock 与 u n l o c k unlock unlock ,都需要配套使用,虽然一般的文件系统调用里面没有体现 i g e t iget iget,但要使用一个 i n o d e inode inode,肯定得先 g e t get get 到对吧,这个步骤一般是在路径解析函数最后返回 i n o d e inode inode 时进行,具体就是在 f s . c / n a m e x fs.c/namex fs.c/namex 函数中。关于 x v 6 xv6 xv6 的文章讲了这么多篇了,这种种关于 i n o d e inode inode 的操作到现在应该算是基操了,后面关于 i n o d e inode inode 的获取释放上锁解锁不再赘述。不太清楚的可以翻看前面关于 x v 6 xv6 xv6 文件系统方面的文章@@@@@@@@@@@
ip->nlink++; //old文件链接数加1
iupdate(ip); //更新inode,写到磁盘(日志区)
iunlock(ip);
这里将要链接的文件的链接数加 1,链接一个文件,当然要将该文件的链接数加 1。目前只是内存中的 i n o d e inode inode 链接数加了 1,需要同步到磁盘上去,当然不是直接写到磁盘对应位置,而是写到日志区,当然也不是马上就写到日志区,还要等待提交,等待磁盘请求。这些也算是基操了不再多言,有疑惑翻看前面的文章。
“更新完毕” 之后解锁,只解锁不释放该 i n o d e inode inode,是因为后续还要使用该 i n o d e inode inode,只是不会再修改其数据,我们接着来看:
if((dp = nameiparent(new, name)) == 0) //寻找新文件的父目录inode
goto bad;
ilock(dp);
if(dp->dev != ip->dev || dirlink(dp, name, ip->inum) < 0){ //在父目录下填写new的名字,old的inode编号,
iunlockput(dp); //两者链接在一起了使用同一个inode表同一个文件
goto bad;
}
iunlockput(dp);
iput(ip);
end_op();
bad: //中途出错的情况
ilock(ip); //上锁
ip->nlink--; //前面nlink加了1,出了错减1
iupdate(ip); //更新
iunlockput(ip);//解锁释放
end_op(); //日志end
return -1;
}
链接一个文件,就是增加一个目录指向该文件,这部分就是在新路径
n
e
w
new
new 下增加一个目录项。首先路径解析
n
e
w
new
new,返回新文件名的父目录
i
n
o
d
e
d
p
inode\ \ dp
inode dp,上锁之后在
d
p
dp
dp 目录下填写目录项,内容为(新文件名,inode 编号),最为重要的就是这儿,填写的
i
n
o
d
e
inode
inode 编号是根据
o
l
d
old
old 解析出来的
i
n
o
d
e
inode
inode 编号,使得两文件名使用同一个
i
n
o
d
e
inode
inode,表示同一个文件。
剩余的部分又是对 i n o d e inode inode 的处理,基本操作,应该能明白就不解释了。
u n l i n k unlink unlink
①函数原型:
int unlink(const char *pathname);
u n l i n k unlink unlink 使 p a t h n a m e pathname pathname 指向的文件链接数减 1,实质上是将 p a t h n a m e pathname pathname 指向的文件父目录下 关于该文件的目录项移除。如果该文件的链接数减到 0 且该文件没有被打开,也就是说引用数也为 0,那么就会删除该文件。
所以总的来说 u n l i n k unlink unlink 做的事情也就两件:
- 删除 p a t h n a m e pathname pathname 目录项
- 文件链接数减 1
②函数实现:
int sys_unlink(void)
{
struct inode *ip, *dp;
struct dirent de;
char name[DIRSIZ], *path;
uint off;
/***函数太长分开叙述***/
}
u n l i n k unlink unlink 大致上是 l i n k link link 的逆操作,但还是有些不同,来具体看看,同样的函数有些长,分开来说
if(argstr(0, &path) < 0) //取得参数路径
return -1;
同样的先去用户栈取得参数:路径
begin_op(); //日志开始
if((dp = nameiparent(path, name)) == 0){ //返回最后一个文件的父目录的inode
end_op();
return -1;
}
ilock(dp);
解析该路径末尾的文件名赋给 n a m e name name,返回其父目录 i n o d e inode inode 赋给 d p dp dp
if(namecmp(name, ".") == 0 || namecmp(name, "..") == 0) //unlink的文件是 . 或 ..
goto bad;
每个目录下都有目录项指向当前目录.和父目录 .. ,这两个目录项不应该被擦除掉。如果要
u
n
l
i
n
k
unlink
unlink 删除某个目录,那么参数位置应该直接设置该目录的路径,也就是说如果现在要
u
n
l
i
n
k
/
a
/
b
/
c
unlink\ \ /a/b/c
unlink /a/b/c,
a
,
b
,
c
a,b,c
a,b,c 都是目录,不应该写成
u
n
l
i
n
k
/
a
/
b
/
c
/
.
unlink\ \ /a/b/c/.
unlink /a/b/c/. 之类的,而
L
i
n
u
x
Linux
Linux 下是无法
u
n
l
i
n
k
unlink
unlink 一个目录的。
if((ip = dirlookup(dp, name, &off)) == 0) //在dp指向的目录下查找name文件
goto bad;
ilock(ip);
这一部分在父目录下查找 n a m e name name 文件,如果找到将目录项的偏移量记录在 o f f off off 中,并返回该文件的 i n o d e i p inode\ \ ip inode ip
if(ip->nlink < 1)
panic("unlink: nlink < 1");
if(ip->type == T_DIR && !isdirempty(ip)){ //如果该文件是个目录文件且为空目录,则unlockput
iunlockput(ip);
goto bad;
}
static int isdirempty(struct inode *dp) //是否是空目录
{
int off;
struct dirent de;
for(off=2*sizeof(de); off<dp->size; off+=sizeof(de)){ //跳过. ..
if(readi(dp, (char*)&de, off, sizeof(de)) != sizeof(de))
panic("isdirempty: readi");
if(de.inum != 0)
return 0;
}
return 1;
}
如果该文件的的链接数已经小于 1 1 1 了,则不应该出现再次 u n l i n k unlink unlink 的情况,定是某个地方出错,所以 p a n i c panic panic
如果该文件是一个目录文件,但不是空目录,则不应该
u
n
l
i
n
k
unlink
unlink 该目录。空目录是指目录项只包括 . 和 .. 的目录,也就是说如果某个目录下面有除开 . 和 .. 的目录项的话,则不应该
u
n
l
i
n
k
unlink
unlink 掉。至于原因和
u
n
l
i
n
k
unlink
unlink 空目录的情况往下看。
memset(&de, 0, sizeof(de));
if(writei(dp, (char*)&de, off, sizeof(de)) != sizeof(de))
panic("unlink: writei");
链接数与目录项有关, u n l i n k unlink unlink 某文件就是将该文件父目录下相应的目录项给清零(删掉),目录项中记录的有 i n o d e inode inode 编号,该目录项被擦除之后相应的 i n o d e inode inode 的链接数就减 1。
所以上述 u n l i n unlin unlink 非空目录的话,就是在其父目录下将这个非空目录的目录项给清除掉,这清除之后那就没办法获取该非空目录下的文件了。因为查找文件路径解析就是通过目录的目录项一层层的找,现下目录项没了,那当然就没法寻到后续的文件,就好比路断了怎么过去。而 L i n u x Linux Linux 下更为严格,不能使用 u n l i n k unlink unlink 一个目录,空目录也不行,经测试, x v 6 xv6 xv6 中是可以使用 u n l i n k unlink unlink 来删除一个空目录的,而 L i n u x Linux Linux 中不行, L i n u x Linux Linux 中有专门的函数 s y s _ r m d i r sys\_rmdir sys_rmdir 来删除目录。
if(ip->type == T_DIR){ //如果unlink目录文件
dp->nlink--;
iupdate(dp);
}
iunlockput(dp);
如果该文件是个目录文件,且是空目录,前面将其父目录下的目录项给清除了,这里还要将其父目录的链接数减 1。因为这个空目录目录下有一个 .. 目录项指向父目录。这里再次看出目录项与链接数息息相关,有多少个目录项,目录项表示的文件链接数就是多少。
ip->nlink--; //链接数减1
iupdate(ip);
iunlockput(ip); //解锁释放inode,如果ref nlink都变为0,则删除该文件
end_op();
指向该文件的目录项被清除了一个,所以该文件的链接数减 1,剩余部分和 b a d bad bad 部分又是对该文件的 i n o d e inode inode 和父目录的 i n o d e inode inode 的后续处理,不再赘述。
c r e a t e create create
①函数原型:
static struct inode* create(char *path, short type, short major, short minor);
这个函数是创建新文件(包括目录、设备文件)的核心函数,在路径 p a t h path path 下创建一个类型为 t y p e type type 的文件, m a j o r major major 和 m i n o r minor minor 分别为主次设备号, m a j o r major major 表示一类设备, m i n o r minor minor 来表示这一类中具体的某设备。 x v 6 xv6 xv6 支持的设备很少,所以对于设备号用的也很少,目前使用的也就是磁盘上的文件,用(0,0)表示,终端用(1,1) 表示。
创建新文件步骤主要就两步:
- 分配 i n o d e inode inode
- 安装目录项
②函数实现:
if((dp = nameiparent(path, name)) == 0) //要创建文件的父目录inode
return 0;
ilock(dp);
if((ip = dirlookup(dp, name, 0)) != 0){ //如果该文件在目录中存在
iunlockput(dp);
ilock(ip);
if(type == T_FILE && ip->type == T_FILE) //如果类型是普通文件
return ip;
iunlockput(ip);
return 0;
}
这部分主要获取 i n o d e inode inode,首先解析路径获取要创建的文件父目录 i n o d e inode inode, 赋给 d p dp dp,然后在父目录下查找是否已存在该文件。如果要创建的文件已经存在,直接返回。
if((ip = ialloc(dp->dev, type)) == 0) //如果该文件不存在,分配一个inode
panic("create: ialloc");
ilock(ip);
ip->major = major;
ip->minor = minor;
ip->nlink = 1; //只有父目录下一个目录项指向该文件
iupdate(ip);
如果要创建的文件不存在,则创建该文件。主要就是分配一个 i n o d e inode inode,该 i n o d e inode inode 的设备号与其目录 i n o d e inode inode 设备号相同。其实这里不应该叫设备号,在 L i n u x Linux Linux 里确实有个 d e v dev dev 属性表设备号,是一个 32 32 32 位的整数,高 12 12 12 位表示主设备号,低 20 20 20 位表示次设备号。但是在 x v 6 xv6 xv6 里面这个 d e v dev dev 其实就是来区分磁盘的主盘和从盘的。为 0 表示主盘,为 1 表示从盘。
后面的 m a j o r m i n o r major\ \ minor major minor 主次设备号前面说过了,这两个值参数给出,磁盘上的文件,用(0,0)表示,终端用(1,1) 表示。
新创建的普通文件链接数为 1,因为只有父目录下有个目录项指向新创建的文件
if(type == T_DIR){ // Create . and .. entries. //如果是创建目录文件,那么必须创建父目录和当前目录的目录项
dp->nlink++; // for ".." 关于父目录的目录项,父目录的链接加1
iupdate(dp);
// No ip->nlink++ for ".": avoid cyclic ref count.
if(dirlink(ip, ".", ip->inum) < 0 || dirlink(ip, "..", dp->inum) < 0) //填写目录项
panic("create dots");
}
如果创建的文件是个目录文件,则其父目录的链接数需要加 1,因为该目录文件下有 .. 目录项指向父目录。虽然也有 . 自己,但是自身的链接数并未加 1,这里注释表示是为了不能循环引用计数?对此表示怀疑,在
L
i
n
u
x
Linux
Linux 下新目录的链接数为 2,而
x
v
6
xv6
xv6 只为 1。对此我认为
x
v
6
xv6
xv6 是为了简化操作,去看了
L
i
n
u
x
0.11
Linux\ \ 0.11
Linux 0.11 的源码,创建新目录和删除一个目录的时候都是以链接数为 2 来判断的,而且修改
i
n
o
d
e
→
n
l
i
n
k
inode \rightarrow nlink
inode→nlink 使用的是直接赋值而不是递增递减来操作,
x
v
6
xv6
xv6 可能为了简化统一吧,只使用
u
n
l
i
n
k
unlink
unlink 和
i
p
u
t
iput
iput 两函数实现对文件的删除,只是这样的话对于
x
v
6
xv6
xv6 来说链接数就与目录项个数不是一一对应的了。
if(dirlink(dp, name, ip->inum) < 0) //在父目录下添加当前文件的目录项
panic("create: dirlink");
iunlockput(dp);
创建一个新文件需要在其父目录下填写当前文件的目录项,这样后续路径解析查找文件时该文件才能被找到。调用 d i r l i n k dirlink dirlink 在 d p dp dp 目录下创建一个新目录项 ( n a m e , i p → n u m ) (name, ip \rightarrow num) (name,ip→num)
o p e n open open
①函数原型:
int open(const char *pathname, int omode);
o p e n open open 函数应该是见的很多了,也用的很多,它来以 o m o d e omode omode 的方式打开一个 位于 p a t h n a m e pathname pathname 的文件,如果没有该文件的话,就先创建再打开。
主要做了以下几件事:
- 去用户栈中取参数
- 如果打开方式为创建,则先调用 c r e a t e create create 创建一个新文件
- 分配文件结构体,分配文件描述符
- 文件描述符指向分配的文件结构体,根据参数设置文件结构体的属性
②函数实现:
if(argstr(0, &path) < 0 || argint(1, &omode) < 0) //获取参数路径和模式
return -1;
这是个系统调用,同样的,先去用户栈取参数:路径 p a t h path path 和模式 o m o d e omode omode,所谓模式就是以什么方式打开这个文件:
#define O_RDONLY 0x000 //只读
#define O_WRONLY 0x001 //只写
#define O_RDWR 0x002 //读写
#define O_CREATE 0x200 //创建
x v 6 xv6 xv6 定义了上述 4 种文件打开模式,只读只写可读可写和创建。
if(omode & O_CREATE){ //如果是创建一个文件
ip = create(path, T_FILE, 0, 0);
if(ip == 0){
end_op();
return -1;
}
如果是创建文件的话,就调用 c r e a t e create create 函数先创建一个文件。参数 p a t h path path 表路径, T _ F I L E T\_FILE T_FILE 表创建一个普通文件,主次设备号都为 0,在 x v 6 xv6 xv6 里面就表示磁盘上的文件。
else { //如果该文件存在
if((ip = namei(path)) == 0){ //解析路径,获取文件inode
end_op();
return -1;
}
ilock(ip); //上锁,(使得inode数据有效)
if(ip->type == T_DIR && omode != O_RDONLY){ //如果文件类型是目录且打开方式不是只读
iunlockput(ip);
end_op();
return -1;
}
}
如果该文件存在,就直接调用 n a m e i ( p a t h ) namei(path) namei(path) 解析该路径,取得该路径表示的文件 i n o d e inode inode,这里判断该文件类型如果是目录,且不是以只读的方式打开的,释放该 i n o d e inode inode,返回 -1 表出错,也就是说目录文件只能以只读的方式打开。
if((f = filealloc()) == 0 || (fd = fdalloc(f)) < 0){ //分配一个文件结构体和文件描述符
if(f)
fileclose(f);
iunlockput(ip);
end_op();
return -1;
}
iunlock(ip);
end_op();
f->type = FD_INODE;
f->ip = ip;
f->off = 0;
f->readable = !(omode & O_WRONLY);
f->writable = (omode & O_WRONLY) || (omode & O_RDWR);
return fd;
这里就说明了打开一个文件就会在文件表中分配一个文件结构体,随后分配一个文件描述符指向刚分配的文件结构体。如果文件结构体和文件描述符正常分配,则 i f if if 分支是不会进去的,如果出错的话怎么处理自己看下不难理解。
如果正常分配的话,就根据参数初始化文件结构体的信息。类型应为 F D _ I N O D E FD\_INODE FD_INODE ,表示可以使用 i n o d e inode inode 的方法来操作文件,包括磁盘上的文件和设备文件。管道类型的文件不是使用这个函数来创建打开的,而是有专门的 p i p e pipe pipe 系统调用。文件刚创建,所以读写的偏移量 o f f off off 初始化为 0,最后再根据 o m o d e omode omode 参数设置该文件的读写权限。
c l o s e close close
①函数原型:
int close(int fd);
c l o s e close close 用来关闭文件描述符 f d fd fd 指向的文件。
②函数实现:
int sys_close(void)
{
int fd;
struct file *f;
if(argfd(0, &fd, &f) < 0) //获取参数
return -1;
myproc()->ofile[fd] = 0; //将文件描述符表中记录的文件指针记0
fileclose(f); //调用fileclose完成关闭文件的剩下操作
return 0;
}
void
fileclose(struct file *f)
{
struct file ff;
acquire(&ftable.lock);
if(f->ref < 1)
panic("fileclose");
if(--f->ref > 0){ //引用数减1
release(&ftable.lock);
return;
}
//如果引用数减为0了,回收文件结构体
ff = *f;
f->ref = 0;
f->type = FD_NONE;
release(&ftable.lock);
if(ff.type == FD_PIPE) //如果该文件是个管道,调用pipeclose来关闭
pipeclose(ff.pipe, ff.writable);
else if(ff.type == FD_INODE){ //如果类型为FD_INODE
begin_op();
iput(ff.ip); //释放该inode
end_op();
}
}
对 o p e n open open 有了解之后, c l o s e close close 应该是很好理解的,所以代码就一次性的全贴上了。主要做了以下几件事:
- 回收文件描述符,就是将打开文件描述表的第 f d fd fd 项置 0。
- 文件结构体中的引用数减 1,表示引用该文件结构体的数量少 1
- 如果引用数减到 0,回收文件结构体
- 根据文件结构体中的类型调用来完成文件关闭的收尾工作,如果是管道文件调用管道的方法来关闭管道。如果是 F D _ I N O D E FD\_INODE FD_INODE 类型的文件,则调用 i n o d e inode inode 的方法 i p u t iput iput 回收 i n o d e inode inode 来收尾,就是将该文件的引用数减 1,并判断链接数和引用数是否都为 0 ,如果都为 0,回收 i n o d e inode inode,回收文件占用的空间,删除该文件。
d u p dup dup
①函数原型:
int dup(int oldfd);
d u p dup dup 这个函数的参数是文件描述符(且称为 o l d f d oldfd oldfd),返回值也是文件描述符(且称为 n e w f d newfd newfd),它的作用就是分配一个 n e w f d newfd newfd ,使其指向的文件结构体与 o l d f d oldfd oldfd 一样,也就是 n e w f d newfd newfd 和 o l d f d oldfd oldfd 这两个下标对应的数组元素是一样的。
②函数实现:
int sys_dup(void)
{
struct file *f;
int fd;
if(argfd(0, 0, &f) < 0) //根据参数文件描述符获取文件指针
return -1;
if((fd=fdalloc(f)) < 0) //分配文件描述符,使分配的描述符指向文件结构体f
return -1;
filedup(f); //文件结构体引用数加 1
return fd; //返回分配的文件描述符
}
struct file* filedup(struct file *f) //增加文件结构体的引用数
{
acquire(&ftable.lock);
if(f->ref < 1)
panic("filedup");
f->ref++; //文件结构体引用数加1
release(&ftable.lock);
return f;
}
static int argfd(int n, int *pfd, struct file **pf) //根据参数位置获取参数文件描述符,再根据文件描述符获取文件指针
{
int fd;
struct file *f;
if(argint(n, &fd) < 0) //取参数文件描述符
return -1;
if(fd < 0 || fd >= NOFILE || (f=myproc()->ofile[fd]) == 0) //取文件指针
return -1;
if(pfd)
*pfd = fd;
if(pf)
*pf = f;
return 0;
}
用户态下调用 d u p ( o l d f d ) dup(oldfd) dup(oldfd), 在调用之前将 o l d f d oldfd oldfd 压在用户栈的,内核态下调用 a r g i n t ( ) argint() argint() 将 o l d f d oldfd oldfd 这个整数从用户栈中取回来。
取回来之后根据进程控制块中的文件描述符表获取相应的文件指针: f = m y p r o c ( ) → o f i l e [ o l d f d ] f = myproc() \rightarrow ofile[oldfd] f=myproc()→ofile[oldfd]
有了旧文件描述符 o l d f d oldfd oldfd,文件指针 f f f,调用 f d a l l o c ( f ) fdalloc(f) fdalloc(f) 分配返回新的文件描述符 n e w f d newfd newfd,新旧描述符的指向相同,也就是 o f i l e [ n e w f d ] = o f i l e [ o l d f d ] ofile[newfd] = ofile[oldfd] ofile[newfd]=ofile[oldfd]
因为多了一个文件描述符表示相应的文件结构体,文件结构体的引用数加 1 1 1,调用 f i l e d u p ( f ) filedup(f) filedup(f) 使其引用数加 1 1 1。
这就是 d u p dup dup 系统调用,用图来说就是:
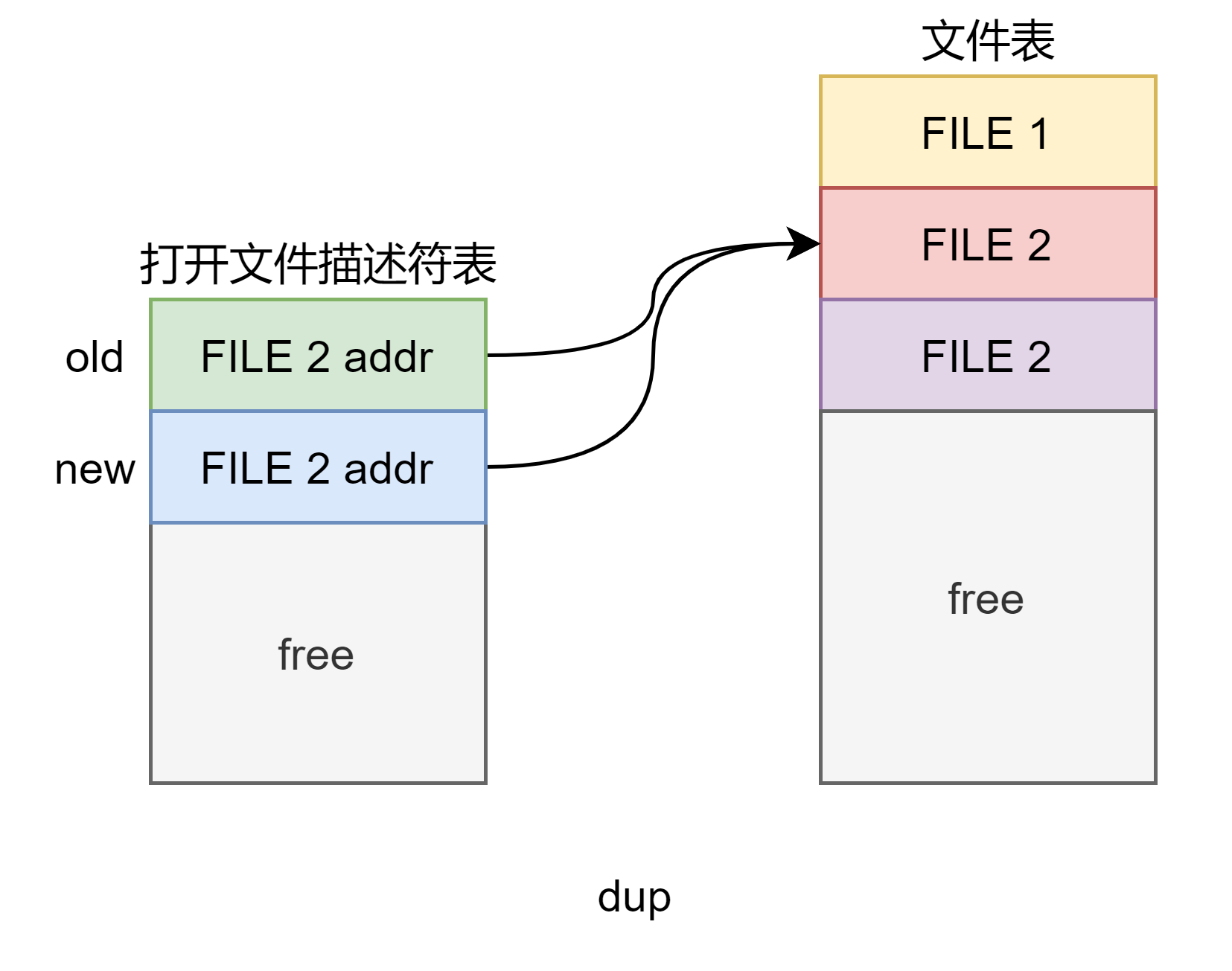
这里就表明了同一个进程中不同的文件描述符是可以引用相同的文件结构体的,通过 d u p dup dup 系统调用就可以实现。
与 d u p dup dup 相关的函数还有个 d u p 2 dup2 dup2,函数原型如下:
int dup2(int oldfd, int newfd);
该函数的功能与 d u p dup dup 相似,只是可以自己决定返回的文件描述符,而不是返回最小可用的文件描述符。
- 当 n e w f d newfd newfd 是空闲的或者等于 o l d f d oldfd oldfd 的时候,返回 n e w f d newfd newfd。
- 当 n e w f d newfd newfd 不空闲指向某个文件时,先关闭那个文件再返回 n e w f d newfd newfd。
r e a d 、 w r i t e read、write read、write
①函数原型:
int read(int fd, void *buf, int size);
int write(int fd, const void *buf, int size)
r e a d read read 就是从文件描述符 f d fd fd 表示的文件中读取 s i z e size size 个字节数据到 b u f buf buf 中去。若读取数据成功则返回读取的字节数,反之返回 − 1 -1 −1。 w r i t e write write 从 b u f buf buf 中写 s i z e size size 个字节数据到 f d fd fd 表示的文件中去。
②函数实现:
int sys_read(void)
{
struct file *f;
int n;
char *p;
if(argfd(0, 0, &f) < 0 || argint(2, &n) < 0 || argptr(1, &p, n) < 0) //获取参数
return -1;
return fileread(f, p, n); //调用fileread进行真正的读取操作
}
int fileread(struct file *f, char *addr, int n)
{
int r;
if(f->readable == 0) //如果该文件不可读
return -1;
if(f->type == FD_PIPE) //如果该文件是管道
return piperead(f->pipe, addr, n); //调用管道读的方法
if(f->type == FD_INODE){ //如果是inode类型的文件
ilock(f->ip);
if((r = readi(f->ip, addr, f->off, n)) > 0) //调用readi方法
f->off += r;
iunlock(f->ip);
return r;
}
panic("fileread");
}
上述两个关于读取文件的脉络应该还是很清晰的,先是获取用户栈中的参数文件描述符,根据文件描述符获取文件指针(文件结构体)。文件结构体中记录的有该文件的信息,比如类型, i n o d e inode inode , p i p e pipe pipe 等等。
如果是管道,调用管道特有的读取方式,如果是 F D _ I N O D E FD\_INODE FD_INODE 类型的文件,调用 i n o d e inode inode 方法 r e a d i readi readi 来读取数据,注意这里不只是读取磁盘上的文件,一些设备文件也是通过 r e a d i readi readi 来读取的,具体可以去看一下 r e a d i readi readi 函数,这在前文@@@@@@@ 有讲述。而管道文件咱们后面再说。
关于 w r i t e write write 写文件,基本上是读取文件的逆操作,就不贴代码赘述了,注意一点就行,关于写磁盘操作为了保证原子性,都是将数据先写到日志区,提交之后再同步到磁盘相应的正确位置。日志区的大小有限,写操作涉及的块可能比较多,所以规定了每次写操作的最大字节数,如果超出则分多次写。
f s t a t fstat fstat
①函数原型:
int fstat(int fd, struct stat*);
f s t a t fstat fstat 用来获取文件信息,也就是 i n o d e inode inode 中记录的文件属性,类似的函数还有 s t a t stat stat, l s t a t lstat lstat,三者功能都差不多,都是列出文件的一些信息。区别就是后两个的参数是文件的全路径而不是文件描述符,再者就是当文件是一个符号连接的时候, l s t a t lstat lstat 会列出符号链接本身的信息,而 s t a t stat stat 会列出该链接指向的文件的信息。三者都用到了一个结构体 s t r u c t s t a t struct\ stat struct stat:
struct stat {
short type; // Type of file
int dev; // File system's disk device
uint ino; // Inode number
short nlink; // Number of links to file
uint size; // Size of file in bytes
};
这就是把 i n o d e inode inode 的属性字段给搬过来了,没什么好说的,直接来看函数实现:
②函数实现:
int sys_fstat(void)
{
struct file *f;
struct stat *st;
if(argfd(0, 0, &f) < 0 || argptr(1, (void*)&st, sizeof(*st)) < 0) //获取参数
return -1;
return filestat(f, st); //调用filestat填充stat结构体
}
int filestat(struct file *f, struct stat *st)
{
if(f->type == FD_INODE){
ilock(f->ip);
stati(f->ip, st); //将inode中记录的信息搬到stat结构体中
iunlock(f->ip);
return 0;
}
return -1;
}
void stati(struct inode *ip, struct stat *st) //将inode中记录的信息搬到stat结构体中
{
st->dev = ip->dev;
st->ino = ip->inum;
st->type = ip->type;
st->nlink = ip->nlink;
st->size = ip->size;
}
f s t a t fstat fstat 函数先取参数文件描述符 f d fd fd,根据 f d fd fd 拿到文件指针,根据文件指针拿到 i n o d e inode inode, i n o d e inode inode 里面就存放着文件的元信息,最后将这些信息放到 s t a t stat stat 结构体中。 s t a t stat stat 命令和 l s ls ls 命令就是靠 s t a t stat stat 系统调用实现的。
m k d i r mkdir mkdir
①函数原型:
int mkdir(const char *pathname);
m k d i r mkdir mkdir 用来在路径 p a t h n a m e pathname pathname 下创建一个目录
②函数实现:
int sys_mkdir(void)
{
char *path;
struct inode *ip;
begin_op();
if(argstr(0, &path) < 0 || (ip = create(path, T_DIR, 0, 0)) == 0){ //获取参数路径,调用create创建目录
end_op();
return -1;
}
iunlockput(ip);
end_op();
return 0;
}
这个函数就是 c r e a t e create create 函数的封装,将类型参数设置为 T _ D I R T\_DIR T_DIR,主次设备号设置为(0,0)就好
c h d i r chdir chdir
①函数原型:
int chdir(const char *pathname);
c h d i r chdir chdir 用来改变当前工作目录
②函数实现:
int sys_chdir(void)
{
char *path;
struct inode *ip;
struct proc *curproc = myproc();
begin_op();
if(argstr(0, &path) < 0 || (ip = namei(path)) == 0){ //获取参数路径,以及路径中最后一个文件的inode
end_op();
return -1;
}
ilock(ip);
if(ip->type != T_DIR){ //如果类型不是目录文件
iunlockput(ip);
end_op();
return -1;
}
iunlock(ip);
iput(curproc->cwd); //“放下”进程原路径的inode
end_op();
curproc->cwd = ip; //进程的路径换为当前新路径
return 0;
}
这个函数看起有点长,主要就做两件事:
- 获取 p a t h n a m e pathname pathname 表示的目录文件的 i n o d e inode inode
- 将该 i n o d e inode inode 赋给当前进程 P C B PCB PCB 的属性 c w d cwd cwd
进程 P C B PCB PCB 的 c w d cwd cwd 就是个 i n o d e inode inode 指针,将 p a t h n a m e pathname pathname 表示的目录 i n o d e inode inode 赋给 c w d cwd cwd 就表示切换目录了,是不是很简单。其实还跟一个函数间接相关,那就是路径解析函数,这个函数在@@@@@@@@@一文中讲过,函数解析的时候会先判断该路径是绝对路径还是相对路径,如果是相对路径的话,这个相对的“参考系”就从进程 P C B PCB PCB 的 c w d cwd cwd 中获取。两者结合使得相对路径得以实现。
总结
有关具体的文件系统调用如何实现的本文就说这么多,基本上也把 xv6 文件系统调用部分说完了,只差一个管道没有叙述,管道内容还是有些多的,留待后面吧。
这里对上述的文件系统调用再总结一番,open、close 用来打开和关闭文件,主要就是文件结构体和文件描述符的分配与回收。
l i n k link link、 u n l i n k unlink unlink 来添加和删除目录项使得文件链接数增减。
c r e a t e create create 在 x v 6 xv6 xv6 里没有实现成系统调用,它来创建一个文件,普通文件和设备文件都有 c r e a t e create create 来创建,主要就是分配 i n o d e inode inode 和在对应位置安装目录项。
m k d i r mkdir mkdir 用来创建一个目录,封装 c r e a t e create create 函数实现
c h d i r chdir chdir 用来改变当前工作目录,就是修改进程控制块的当前工作目录这个属性,是个目录文件的 i n o d e inode inode,更改工作路径就是换个目录的 i n o d e inode inode
r e a d read read、 w r i t e write write 用来读写文件,通过文件结构体中记录的文件类型来调用不同的读写方法,读写之后修改 $off 变 量 记 录 文 件 读 写 偏 移 量 。 变量记录文件读写偏移量。 变量记录文件读写偏移量。xv6$ 没有实现 l s e e k lseek lseek 系统调用, l s e e k lseek lseek 用来定位文件位置,就是通过修改 o f f off off 来实现的。
d u p dup dup 用来复制文件描述符,使得不同的文件描述符指向相同的文件结构体,就是分配一个最小可用的文件描述符,使其对应的元素为文件结构体的地址。
s t a t stat stat 用来打印文件的信息,就是把 i n o d e inode inode 的一些属性给搬过来
删除文件
创建打开关闭文件都说了,最后再来聊聊删除文件。前面说过,系统为每一个文件维护了两个计数值,一个是 n l i n k nlink nlink,可以看作是磁盘级对于文件的计数,本质上是有多少个目录项指向该文件。
r e f ref ref,文件引用数,也就是文件的 i n o d e inode inode 正在被使用的次数,当调用 i g e t iget iget 获取一个 i n o d e inode inode 时,就会将其引用数 r e f ref ref 加 1,调用 i p u t iput iput 又会使引用数减 1,很多地方都会使用这两个函数,并且与 l o c k 、 u n l o c k lock、unlock lock、unlock 配套使用。很多函数中对某个 i n o d e inode inode 使用了 i g e t iget iget ( i g e t iget iget 隐藏在其他函数中)通常又会在同一个函数中 i p u t iput iput,特别是目录文件的 i n o d e inode inode ,所以其实很多函数中引用数增增减减但最终并未变化。
但是在 o p e n open open 函数如果正常执行的话,获取( i g e t iget iget)文件的 i n o d e inode inode 之后并没有释放( i p u t iput iput),而是在 c l o s e close close 中释放。所以这个 i n o d e inode inode 的 r e f ref ref 属性,文件的引用数,对于普通文件来说其实可以看作文件当前的打开数。
那具体是如何删除文件的呢?删除文件的必要条件是 n l i n k = = 0 & & r e f = = 0 nlink == 0\ \&\&\ ref == 0 nlink==0 && ref==0
具体删除文件的函数就是 i p u t iput iput,在 L i n u x 0.11 Linux\ 0.11 Linux 0.11 里面也是同名的函数。回过头去看 i p u t iput iput 函数, i p u t iput iput 会检查 n l i n k nlink nlink 和 r e f ref ref 两个值是否都为 0,如果都为 0 的话就代表既没有目录项指向它,内存里面有没有引用该文件(打开该文件),那么这个文件其实就是个“孤魂野鬼”,完全可以回收掉它占用的 i n o d e inode inode,占用的磁盘空间,也就是将文件给删除掉了。这些事情是 i p u t iput iput 调用函数 i t r u n c itrunc itrunc 来做的。
网上很多说是 u n l i n k unlink unlink 删除文件,其实不然, u n l i n k unlink unlink 只是将目录项给抹除了,将链接数减 1,但最终还是调用的 i p u t iput iput 来执行是否要删除文件的检查。如果引用数不为 0,就算是 u n l i n k unlink unlink 之后链接数为 0 也无济于事。
我做了一个简单的测试:
int main(){
int fd;
fd = open("unlink_test.txt", O_RDWR|O_CREAT); //打开创建一个文件
char *buf1 = "unlink test";
char *buf2;
sleep(10); //睡眠10s,去另开一个终端删除该文件
write(fd, buf1, sizeof(buf1)); //写该文件
read(fd, buf2, sizeof(buf1)); //读该文件
printf("%s\n", buf1);
struct stat s;
fstat(fd, &s); //获取stat信息
printf("%ld\n", s.st_nlink); //链接数
close(fd); //关闭该文件
if(fd = open("unlink_test", O_RDWR) < 0){ //文件已删除,不能打开
printf("file not exist\n");
}
}
先创建打开一个文件,接着睡眠 10 s 10s 10s,在这 10 s 10s 10s 内我另开一个终端使用 r m rm rm 或者直接使用 u n l i n k unlink unlink “删除”该文件, 10 s 10s 10s 之后程序照样可以对该文件进行读写只是链接数变为 0 了。文件关闭之后再次打开文件就失败了。测试截图如下:

这说明文件处于打开状态时, r m / u n l i n k rm/unlink rm/unlink 该文件,该文件其实并没有被删除,只是这个文件在其父目录下的目录项被删了,链接数减了 1。但是该进程还拥有该文件的文件描述符,文件结构体, i n o d e inode inode,依然能够找到该文件的数据块位置,对其进行读写等操作。
但是 c l o s e close close 之后,进程中不会再留存该文件的文件描述符,文件结构体, i n o d e inode inode 等结构,而磁盘上相应的目录项已经被删除了,文件名和 i n o d e inode inode 的关联已经被切断,不能再通过任何正常的方式获取到该文件的 i n o d e inode inode,链接数和引用数都为 0,回收该文件的资源,这时就认为文件已被删除。
关于文件删除再多说两句,一般的我们删除文件并不是直接删除,而是放到回收站了,也就是相当于将该文件移动到回收站那个目录下面去了。使用 r m / u n l i n k rm/unlink rm/unlink 这种就是彻底删除文件了。但其实也不能说是彻底,因为根据上面的函数实现来看会发现,它只是断开了文件与 i n o d e inode inode 的联系,回收了文件占用的资源,但是文件实际在磁盘上的数据是没有改动的,所以文件实际还在磁盘上,但是我们用正常的方式得不到而已。使用一些文件恢复工具就可以恢复文件,要想真正地彻底删除一个文件就只有在存储设备的相应位置覆写无效数据,或者直接格式化存储设备。据说,就算覆写了数据格式化了设备,通过一些黑科技物理手段也是能够找回数据的。
好啦,本文就到这里吧, x v 6 xv6 xv6 文件系统这个部分差不多结尾了,还剩下设备文件,管道,安装文件系统没有讲述,还有一些关于文件的命令,后面再慢慢聊吧。关于本文有什么错误还请批评指正,也欢迎大家来同我讨论交流学习进步,如果对您有所帮助还请点个赞与再看,在此拜谢。














 1225
1225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









