







文章目录
引言
以下代码使用到的数据集
百度网盘提取码:1234
一、简介

二、线性可分支持向量机
1.函数间隔、几何间隔

2.目标函数推导—凸二次最优化问题

3.目标函数求解

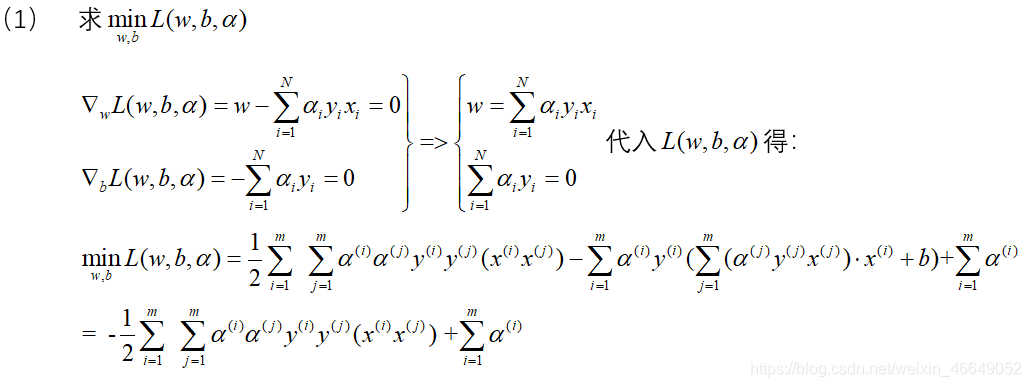


4.线性可分支持向量机算法

三、线性支持向量机

1.目标函数的求解

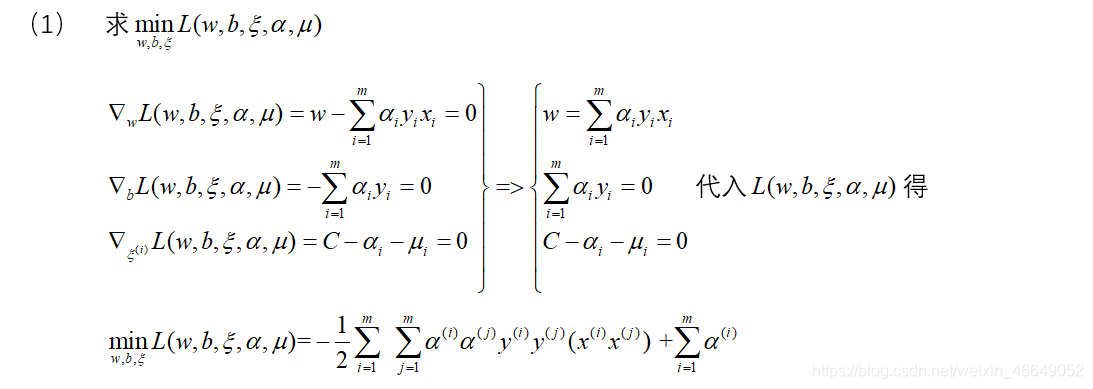


2.线性支持向量机算法


四、非线性支持向量机与核函数
1.核技巧(核函数)
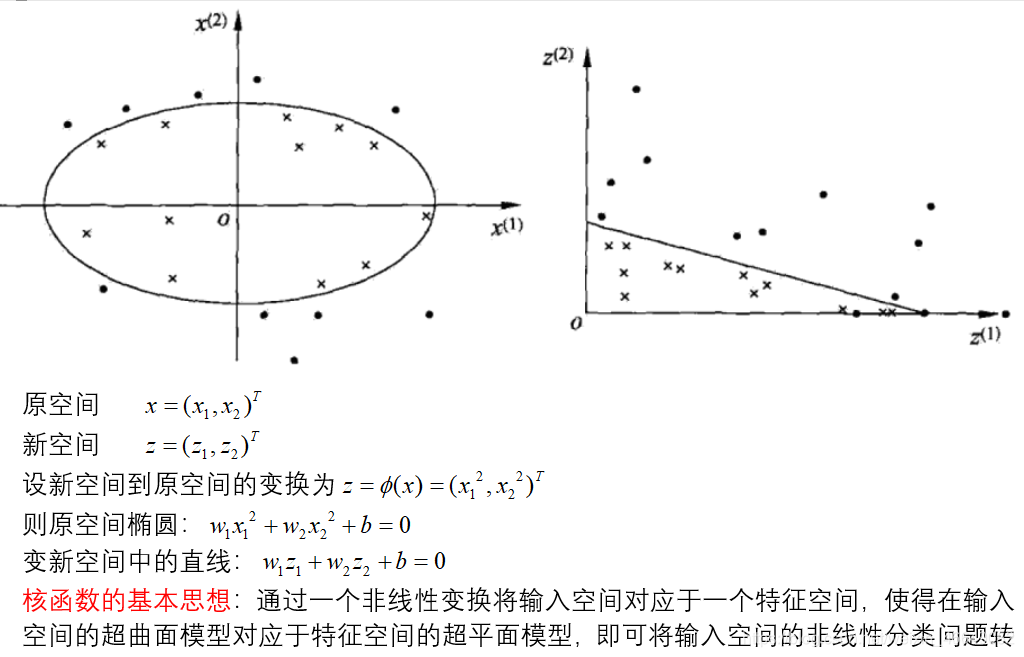

2.目标函数

3.常用核函数
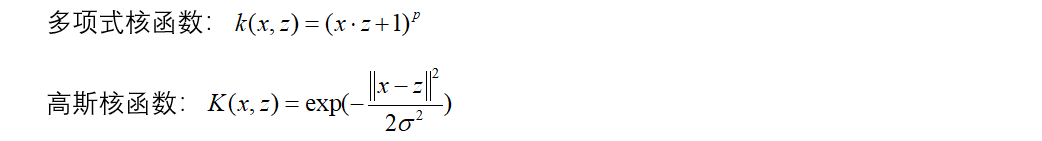
4.非线性支持向量机算法

五、序列最小最优算法—SMO算法

1.两个变量二次规划求解方法


2.变量选择方法


3.SMO算法


4.SMO算法代码实现
import matplotlib as mpl
import matplotlib.pyplot as plt
from matplotlib.patches import Circle
import numpy as np
# 加载数据
def loadDataSet(fileName):
dataMat = []
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat, labelMat
# SMO算法实现-α的求解过程
# alpha的选取,随机选择一个不等于i值的j
def selectJrand(i, m):
j = i
while (j == i):
# random.uniform()可以生成[low,high)中的随机数,可以是单个值
j = int(np.random.uniform(0, m))
return j
# 进行剪辑
def clipAlpha(aj, H, L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
# SMO算法的核心实现
# dataMatIn表示X,classLabels表示y,C表示惩罚因子,toler表示误差值达到多少时可以停止,maxIter表示迭代次数
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
# 转换成矩阵
dataMatrix = np.mat(dataMatIn)
labelMat = np.mat(classLabels).transpose()
# 初始化b为0
b = 0
# 获取数据维度
m, n = np.shape(dataMatrix)
# 初始化所有alpha为0
alphas = np.mat(np.zeros((m, 1)))
iter = 0
# 迭代求解
while (iter < maxIter):
alphaPairsChanged = 0
for i in range(m):
# 计算g(xi)
gXi = float(np.multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[i, :].T)) + b
# 计算Ei
Ei = gXi - float(labelMat[i])
if ((labelMat[i] * Ei < -toler) and (alphas[i] < C)) or ((labelMat[i] * Ei > toler) and (alphas[i] > 0)):
# 随机选择一个待优化的alpha(先随机出alpha下标)
j = selectJrand(i, m)
# 计算g(xj)
gXj = float(np.multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[j, :].T)) + b
# 计算Ej
Ej = gXj - float(labelMat[j])
# 把原来的alpha值复制,作为old值
alphaIold = alphas[i].copy();
alphaJold = alphas[j].copy()
# 计算上下界
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L == H: print("L==H"); continue
# 计算eta
eta = 2.0 * dataMatrix[i, :] * dataMatrix[j, :].T - dataMatrix[i, :] * dataMatrix[i, :].T - dataMatrix[
j,
:] * dataMatrix[
j, :].T
if eta >= 0: print("eta>=0"); continue
# 计算alpha[j],为了和公式对应把j看出2
alphas[j] -= labelMat[j] * (Ei - Ej) / eta
# 剪辑alpha[j],为了和公式对应把j看出2
alphas[j] = clipAlpha(alphas[j], H, L)
if (abs(alphas[j] - alphaJold) < 0.00001): print("j not moving enough"); continue
# 计算alpha[i] ,为了和公式对应把j看出1
alphas[i] += labelMat[j] * labelMat[i] * (alphaJold - alphas[j])
# 计算b1
b1 = b - Ei - labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[i, :].T - labelMat[
j] * (alphas[j] - alphaJold) * dataMatrix[i, :] * dataMatrix[j, :].T
# 计算b2
b2 = b - Ej - labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[j, :].T - labelMat[
j] * (alphas[j] - alphaJold) * dataMatrix[j, :] * dataMatrix[j, :].T
# 求解b
if (0 < alphas[i]) and (C > alphas[i]):
b = b1
elif (0 < alphas[j]) and (C > alphas[j]):
b = b2
else:
b = (b1 + b2) / 2.0
alphaPairsChanged += 1
print("iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged))
if (alphaPairsChanged == 0):
iter += 1
else:
iter = 0
print("iteration number: %d" % iter)
return b, alphas
# 计算W
def clacWs(alphas, dataArr, classLabels):
X = np.mat(dataArr)
labelMat = np.mat(classLabels).transpose()
m, n = np.shape(X)
# 初始化w都为0
w = np.zeros((n, 1))
# 循环计算
for i in range(m):
w += np.multiply(alphas[i] * labelMat[i], X[i, :].T)
return w
if __name__ == '__main__':
# 加载数据
dataMat, labelMat = loadDataSet('svm1.txt')
print(dataMat)
print(labelMat)
# 画散点图
fig = plt.figure()
ax = plt.subplot(111)
cm_dark = mpl.colors.ListedColormap(['g', 'r'])
# squeeze
ax.scatter(np.array(dataMat)[:, 0], np.array(dataMat)[:, 1], c=np.array(labelMat).squeeze(), cmap=cm_dark, s=30)
# 调用上述方法。求解w,b,alpha
b, alphas = smoSimple(dataMat, labelMat, 0.6, 0.001, 40)
w = clacWs(alphas, dataMat, labelMat)
print('b=', b)
print('alphas=', alphas)
print('w =', w)
# 画决策平面
x = np.arange(-2.0, 12.0, 0.1)
y = (-w[0] * x - b) / w[1]
ax.plot(x, y.reshape(-1, 1))
ax.axis([-2, 12, -8, 6])
# 画支持向量
alphas_non_zeros_index = np.where(alphas > 0)
for i in alphas_non_zeros_index[0]:
circle = Circle((dataMat[i][0], dataMat[i][1]), 0.2, facecolor='none', edgecolor=(0, 0.8, 0.8), linewidth=3,
alpha=0.5)
ax.add_patch(circle)
plt.show()
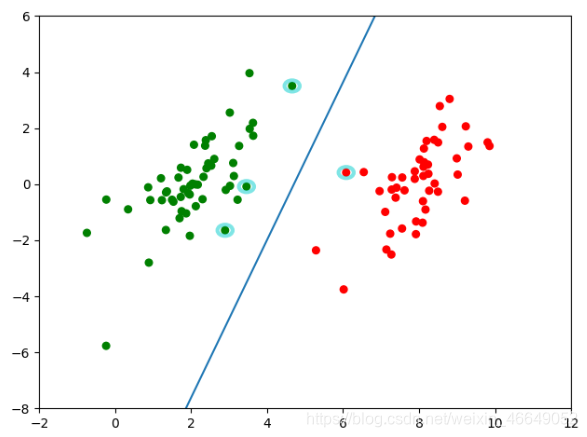
5.SMO算法改进版—改进SVM的运行速度
# 改进以加快SVM的运行速度
import matplotlib as mpl
import matplotlib.pyplot as plt
from matplotlib.patches import Circle
from numpy import *
# 加载数据
def loadDataSet(fileName):
dataMat = []
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat, labelMat
# SMO算法实现-α的求解过程
# alpha的选取,随机选择一个不等于i值的j
def selectJrand(i, m):
j = i
while (j == i):
# random.uniform()可以生成[low,high)中的随机数,可以是单个值
j = int(random.uniform(0, m))
return j
# 进行剪辑
def clipAlpha(aj, H, L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
# 定义一个新的数据结构-将常用的参数进行封装
class optStruct:
def __init__(self, dataMatIn, classLabels, C, toler):
self.X = dataMatIn
self.labelMat = classLabels
self.C = C
self.tol = toler
self.m = shape(dataMatIn)[0]
self.alphas = mat(zeros((self.m, 1)))
self.b = 0
# 第一列是标志位,0无效 1有效
self.eCache = mat(zeros((self.m, 2)))
# 计算Ei的方法
def calcEk(oS, k):
fXk = float(multiply(oS.alphas, oS.labelMat).T * (oS.X * oS.X[k, :].T)) + oS.b
Ek = fXk - float(oS.labelMat[k])
return Ek
# 选择第二个待优化的alpha j,选择一个误差最大的alpha j
def selectJ(i, oS, Ei):
# 初始化
maxK = -1
maxDeltaE = 0
Ej = 0
# 设为有效
oS.eCache[i] = [1, Ei]
# 非零项
validEcacheList = nonzero(oS.eCache[:, 0].A)[0]
if (len(validEcacheList)) > 1:
# 迭代所有有效的缓存,找到误差最大的E
for k in validEcacheList:
# 不选择和i相等的值
if k == i:
continue
Ek = calcEk(oS, k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE):
maxK = k
maxDeltaE = deltaE
Ej = Ek
return maxK, Ej
else:
# 第一次循环时是没有有效的缓存值得,所以随机选一个(仅会执行一次)
j = selectJrand(i, oS.m)
Ej = calcEk(oS, j)
return j, Ej
# 更新缓存
def updateEk(oS, k):
Ek = calcEk(oS, k)
oS.eCache[k] = [1, Ek]
def innerL(i, oS):
# 计算Ei值
Ei = calcEk(oS, i)
# 满足这个条件,α值才能得到更新
if ((oS.labelMat[i] * Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or (
(oS.labelMat[i] * Ei > oS.tol) and (oS.alphas[i] > 0)):
j, Ej = selectJ(i, oS, Ei) # 这里不再是随机选取了
alphaIold = oS.alphas[i].copy()
alphaJold = oS.alphas[j].copy()
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L == H: print("L==H"); return 0
eta = 2.0 * oS.X[i, :] * oS.X[j, :].T - oS.X[i, :] * oS.X[i, :].T - oS.X[j, :] * oS.X[j, :].T
if eta >= 0: print("eta>=0"); return 0
oS.alphas[j] -= oS.labelMat[j] * (Ei - Ej) / eta
oS.alphas[j] = clipAlpha(oS.alphas[j], H, L)
# 这里增加了更新缓存的方法
updateEk(oS, j)
if (abs(oS.alphas[j] - alphaJold) < 0.00001): print("j not moving enough"); return 0
oS.alphas[i] += oS.labelMat[j] * oS.labelMat[i] * (alphaJold - oS.alphas[j])
# 这里增加了更新缓存的方法
updateEk(oS, i)
# 计算b1、b2值
b1 = oS.b - Ei - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.X[i, :] * oS.X[i, :].T - oS.labelMat[j] * (
oS.alphas[j] - alphaJold) * oS.X[i, :] * oS.X[j, :].T
b2 = oS.b - Ej - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.X[i, :] * oS.X[j, :].T - oS.labelMat[j] * (
oS.alphas[j] - alphaJold) * oS.X[j, :] * oS.X[j, :].T
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]):
oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]):
oS.b = b2
else:
oS.b = (b1 + b2) / 2.0
return 1
else:
return 0
# 完整改进后的SMO算法
def smoP(dataMatIn, classLabels, C, toler, maxIter):
oS = optStruct(mat(dataMatIn), mat(classLabels).transpose(), C, toler)
iter = 0
# 表示是否在全部数据集上进行迭代
entireSet = True
#
alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
# 遍历全部的数据集
if entireSet:
for i in range(oS.m):
alphaPairsChanged += innerL(i, oS)
print("fullSet, iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged))
iter += 1
else:
# 遍历非边界数据集
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i, oS)
print("non-bound, iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged))
iter += 1
# 进行切换
if entireSet:
entireSet = False
elif (alphaPairsChanged == 0):
entireSet = True
print("iteration number: %d" % iter)
return oS.b, oS.alphas
# 计算w
def calcWs(alphas, dataArr, classLabels):
X = mat(dataArr);
labelMat = mat(classLabels).transpose()
m, n = shape(X)
w = zeros((n, 1))
for i in range(m):
w += multiply(alphas[i] * labelMat[i], X[i, :].T)
return w
if __name__ == '__main__':
dataMat, labelMat = loadDataSet('data/svm1.txt')
# 画图
fig = plt.figure()
ax = fig.add_subplot(111)
cm_dark = mpl.colors.ListedColormap(['g', 'r'])
ax.scatter(array(dataMat)[:, 0], array(dataMat)[:, 1], c=array(labelMat).squeeze(), cmap=cm_dark, s=30)
# plt.show()
b, alphas = smoP(dataMat, labelMat, 0.6, 0.001, 40)
w = calcWs(alphas, dataMat, labelMat)
print('b=', b)
print('alphas=', alphas)
print('w=', w)
# 画决策平面
x = arange(-2.0, 12.0, 0.1)
y = (-w[0] * x - b) / w[1]
ax.plot(x, y.reshape(-1, 1))
ax.axis([-2, 12, -8, 6])
# 画支持向量
alphas_non_zeros_index = where(alphas > 0)
for i in alphas_non_zeros_index[0]:
circle = Circle((dataMat[i][0], dataMat[i][1]), 0.2, facecolor='none', edgecolor=(0, 0.8, 0.8), linewidth=3,
alpha=0.5)
ax.add_patch(circle)
plt.show()
6.SVM代码实现之核函数
# SVM代码实现之核函数
import matplotlib as mpl
import matplotlib.pyplot as plt
from matplotlib.patches import Circle
from numpy import *
# 加载数据
def loadDataSet(fileName):
dataMat = []
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat, labelMat
# SMO算法实现-α的求解过程
# alpha的选取,随机选择一个不等于i值的j
def selectJrand(i, m):
j = i
while (j == i):
# random.uniform()可以生成[low,high)中的随机数,可以是单个值
j = int(random.uniform(0, m))
return j
# 进行剪辑
def clipAlpha(aj, H, L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
# 核函数
# X,A表示Xi和Xj
def kernelTrans(X, A, kTup):
m, n = shape(X)
K = mat(zeros((m, 1)))
if kTup[0] == 'lin': # 线性核
K = X * A.T
elif kTup[0] == 'rbf': # 高斯核
# 处理二范式
for j in range(m):
deltaRow = X[j, :] - A
K[j] = deltaRow * deltaRow.T
K = exp(K / (-2 * kTup[1] ** 2))
else:
raise NameError('Houston We Have a Problem --That Kernel is not recognized')
return K
# 定义一个新的数据结构
class optStruct:
def __init__(self, dataMatIn, classLabels, C, toler, kTup):
self.X = dataMatIn
self.labelMat = classLabels
self.C = C
self.tol = toler
self.m = shape(dataMatIn)[0]
self.alphas = mat(zeros((self.m, 1)))
self.b = 0
# 第一列是标志位,0无效,1有效
self.eCache = mat(zeros((self.m, 2)))
self.K = mat(zeros((self.m, self.m)))
for i in range(self.m):
self.K[:, i] = kernelTrans(self.X, self.X[i, :], kTup)
# 计算Ei的方法
def calcEk(oS, k):
fXk = float(multiply(oS.alphas, oS.labelMat).T * oS.K[:, k] + oS.b)
Ek = fXk - float(oS.labelMat[k])
return Ek
# 选择第二个待优化的alpha j,选择一个误差最大的alpha j
def selectJ(i, oS, Ei):
maxK = -1
maxDeltaE = 0
Ej = 0
oS.eCache[i] = [1, Ei] # 设为有效
validEcacheList = nonzero(oS.eCache[:, 0].A)[0]
if (len(validEcacheList)) > 1:
for k in validEcacheList: # 迭代所有有效的缓存,找到误差最大的E
if k == i: continue # 不选择和i相等的值
Ek = calcEk(oS, k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE):
maxK = k;
maxDeltaE = deltaE;
Ej = Ek
return maxK, Ej
else: # 第一次循环时是没有有效的缓存值得,所以随机选一个(仅会执行一次)
j = selectJrand(i, oS.m)
Ej = calcEk(oS, j)
return j, Ej
def updateEk(oS, k): # 更新缓存
Ek = calcEk(oS, k)
oS.eCache[k] = [1, Ek]
def innerL(i, oS):
Ei = calcEk(oS, i)
if ((oS.labelMat[i] * Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or (
(oS.labelMat[i] * Ei > oS.tol) and (oS.alphas[i] > 0)):
j, Ej = selectJ(i, oS, Ei) # 这里不再是随机选取了
alphaIold = oS.alphas[i].copy()
alphaJold = oS.alphas[j].copy()
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L == H: print("L==H");return 0
# 这里计算要使用核函数
eta = 2.0 * oS.K[i, j] - oS.K[i, i] - oS.K[j, j]
if eta >= 0: print("eta>=0"); return 0
oS.alphas[j] -= oS.labelMat[j] * (Ei - Ej) / eta
oS.alphas[j] = clipAlpha(oS.alphas[j], H, L)
# 这里增加了更新缓存的方法
updateEk(oS, j)
if (abs(oS.alphas[j] - alphaJold) < 0.00001): print("j not moving enough");return 0
oS.alphas[i] += oS.labelMat[j] * oS.labelMat[i] * (alphaJold - oS.alphas[j])
# 这里增加了更新缓存的方法
updateEk(oS, i)
# 这里直接用核函数代替
b1 = oS.b - Ei - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.K[i, i] - oS.labelMat[j] * (
oS.alphas[j] - alphaJold) * oS.K[i, j]
b2 = oS.b - Ej - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.K[i, j] - oS.labelMat[j] * (
oS.alphas[j] - alphaJold) * oS.K[j, j]
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]):
oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]):
oS.b = b2
else:
oS.b = (b1 + b2) / 2.0
return 1
else:
return 0
# 完整的改进后的使用核函数的SMO算法
def smo(dataMatIn, classLabels, C, toler, maxIter, kTup=('lin', 0)):
oS = optStruct(mat(dataMatIn), mat(classLabels).transpose(), C, toler, kTup)
iter = 0
entireSet = True
alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
# 遍历全部数据集
if entireSet:
for i in range(oS.m):
alphaPairsChanged += innerL(i, oS)
print("fullSet, iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged))
iter += 1
else:
# 遍历非边界数据集
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i, oS)
print("non-bound, iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged))
iter += 1
if entireSet:
entireSet = False # 进行切换
elif (alphaPairsChanged == 0):
entireSet = True
print("iteration number: %d" % iter)
return oS.b, oS.alphas
# 计算w
def calcWs(alphas, dataArr, classLabels):
X = mat(dataArr)
labelMat = mat(classLabels).transpose()
m, n = shape(X)
w = zeros((n, 1))
for i in range(m):
w += multiply(alphas[i] * labelMat[i], X[i, :].T)
return w
if __name__ == '__main__':
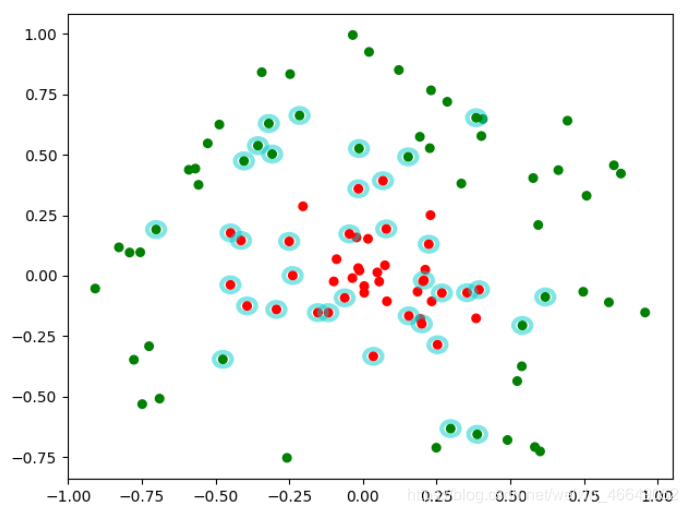
# svm2是非线性数据
dataMat, labelMat = loadDataSet('data/svm2.txt')
# 画图
fig = plt.figure()
ax = fig.add_subplot(111)
cm_dark = mpl.colors.ListedColormap(['g', 'r'])
ax.scatter(array(dataMat)[:, 0], array(dataMat)[:, 1], c=array(labelMat).squeeze(), cmap=cm_dark, s=30)
# plt.show()
b, alphas = smo(dataMat, labelMat, 200, 0.0001, 10000, ('rbf', 1.3))
w = calcWs(alphas, dataMat, labelMat)
print('b=', b)
print('alphas=', alphas)
print('w=', w)
# 画支持向量
alphas_non_zeros_index = where(alphas > 0)
for i in alphas_non_zeros_index[0]:
circle = Circle((dataMat[i][0], dataMat[i][1]), 0.03, facecolor='none', edgecolor=(0, 0.8, 0.8), linewidth=3,
alpha=0.5)
ax.add_patch(circle)
plt.show()















 494
494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









