






概述:
本文将通过组织自己的训练数据,使用Pytorch深度学习框架来训练自己的模型,最终实现自己的图像分类!本篇文章以识别阳台为例子,进行讲述。
一. 数据准备
深度学习的基础就是数据,完成图像分类,当然数据也必不可少。先使用爬虫爬取阳台图片1200张以及非阳台图片1200张,图片的名字从0.jpg一直编到2400.jpg,把爬取的图片放置在同一个文件夹中命名为image(如下图1所示)。
针对百度图片的爬虫代码也放上,方便大家使用,代码可以爬取任意自定义的图片: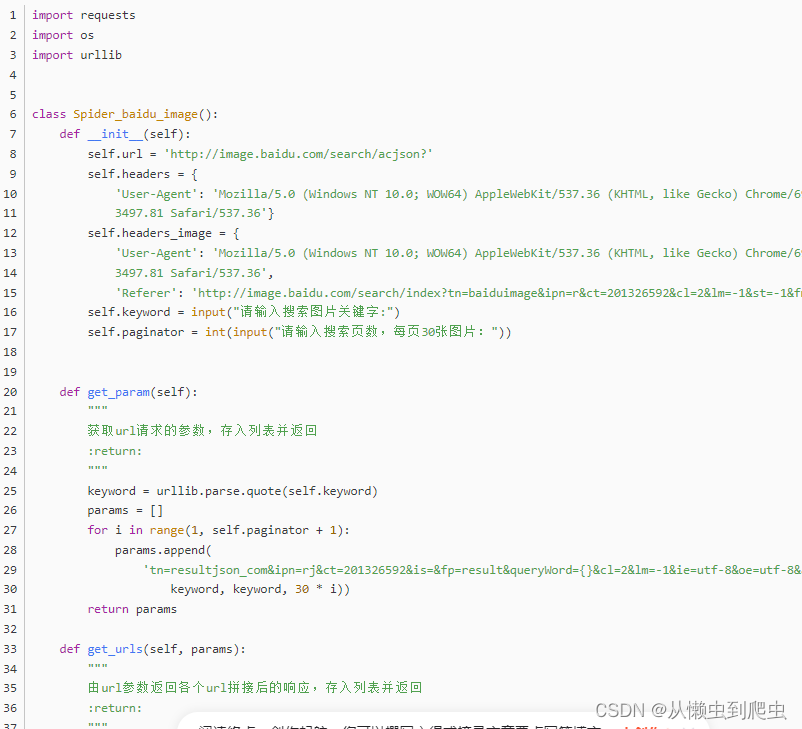
每个图片要加上对应的标签,那么在txt文档当中,选取图片的名称,在其后加上标签。如果是阳台,则标签为1,如果不是阳台,则标签为0。在2400张图片中,分成两个txt文档为训练集和验证集“train.txt”和“val.txt”(如下图2,3所示)


通过观察自己爬取的图片,可以发现阳台各式各样,有的半开放,有的是封闭式的,有的甚至和其他可识别物体花,草混在一起。同时,图片尺寸也不一致,有的是竖放的长方形,有的是横放的长方形,但我们最终需要是合理尺寸的正方形。所以我们使用Resize的库用于给图像进行缩放操作,我这里把图片缩放到84*84的级别。除缩放操作以外还需对数据进行预处理:
torchvision.transforms是pytorch中的图像预处理包
一般用Compose把多个步骤整合到一起:
比如说
transforms.Compose([
transforms.CenterCrop(84),
transforms.ToTensor(),
])
这样就把两个步骤整合到一起
CenterCrop用于从中心裁剪图片,目标是一个长宽都为84的正方形,方便后续的计算。除CenterCrop外补充一个RandomCrop是在一个随机的位置进行裁剪。
ToTenser()这个函数的目的就是读取图片像素并且转化为0-1的数字(进行归一化操作)。
代码如下:

解决对图像的处理过后,想要开始训练网络模型,首先要解决的就是图像数据的读入,Pytorch使用DataLoader来实现图像数据读入,代码如下:
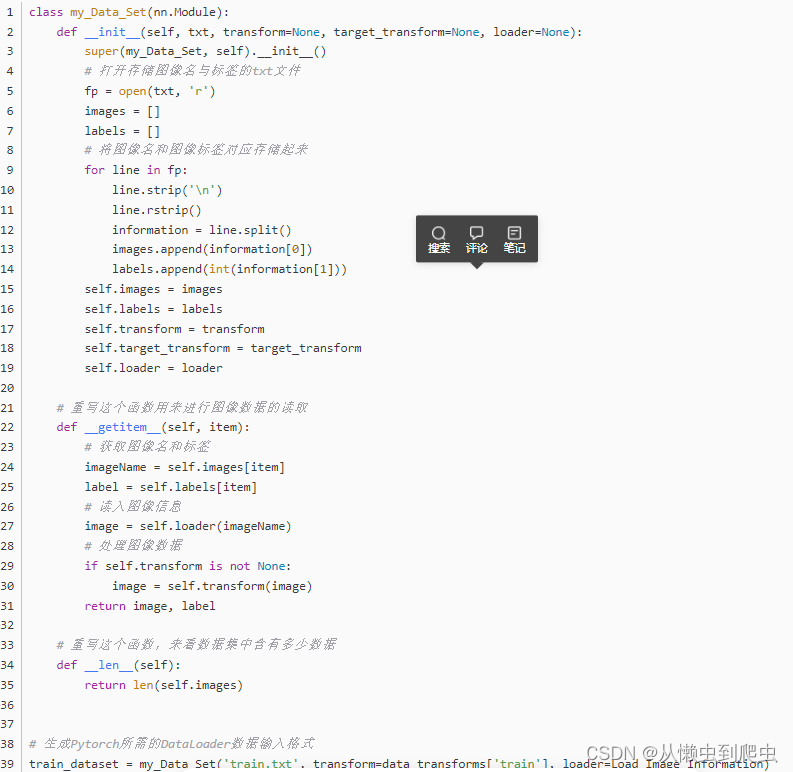
可验证是否生成了DataLoader格式数据:

二.定义一个卷积神经网络
卷积神经网络一种典型的多层神经网络,擅长处理图像特别是大图像的相关机器学习问题。卷积神经网络通过一系列的方法,成功地将大数据量的图像识别问题不断降维,最终使其能够被训练。卷积神经网络(CNN)最早由Yann LeCun提出并应用在手写体识别上。
一个典型的CNN网络架构如下图4: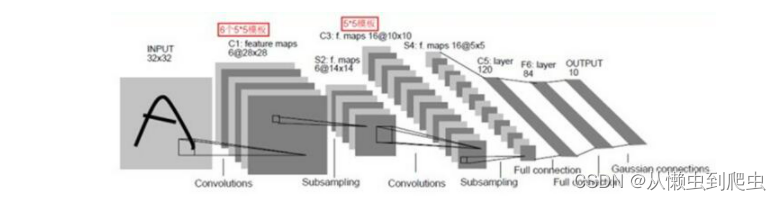
首先导入Python需要的库:

定义一个卷积神经网络:

我们首先定义了一个Net类,它封装了所以训练的步骤,包括卷积、池化、激活以及全连接操作。
__init__函数首先定义了所需要的所有函数,这些函数都会在forward中调用。从conv1说起,conv1实际上就是定义一个卷积层,3代表的是输入图像的像素数组的层数,一般来说就是输入的图像的通道数,比如这里使用的图像都是彩色图像,由R、G、B三个通道组成,所以数值为3;6代表的是我们希望进行6次卷积,每一次卷积都能生成不同的特征映射数组,用于提取图像的6种特征。每一个特征映射结果最终都会被堆叠在一起形成一个图像输出,再作为下一步的输入;5就是过滤框架的尺寸,表示我们希望用一个5 *5的矩阵去和图像中相同尺寸的矩阵进行点乘再相加,形成一个值。定义好了卷基层,我们接着定义池化层。池化层所做的事说来简单,其实就是因为大图片生成的像素矩阵实在太大了,我们需要用一个合理的方法在降维的同时又不失去物体特征,所以使用池化的技术,每四个元素合并成一个元素,用这一个元素去代表四个元素的值,所以图像体积会降为原来的四分之一。再往下一行,我们又一次碰见了一个卷基层:conv2,和conv1一样,它的输入也是一个多层像素数组,输出也是一个多层像素数组,不同的是这一次完成的计算量更大了,我们看这里面的参数分别是6,16,5。之所以为6是因为conv1的输出层数为6,所以这里输入的层数就是6;16代表conv2的输出层数,和conv1一样,16代表着这一次卷积操作将会学习图片的16种映射特征,特征越多理论上能学习的效果就越好。conv2使用的过滤框尺寸和conv1一样,所以不再重复。
对于fc1,16很好理解,因为最后一次卷积生成的图像矩阵的高度就是16层,前面我们把训练图像裁剪成一个84 * 84的正方形尺寸,所以图像最早输入就是一个3 * 84 * 84的数组。经过第一次5 *5的卷积之后,我们可以得出卷积的结果是一个6 * 80 * 80的矩阵,这里的80就是因为我们使用了一个5 *5的过滤框,当它从左上角第一个元素开始卷积后,过滤框的中心是从2到78,并不是从0到79,所以结果就是一个80 * 80的图像了。经过一个池化层之后,图像尺寸的宽和高都分别缩小到原来的1/2,所以变成40 * 40。紧接着又进行了一次卷积,和上一次一样,长宽都减掉4,变成36 * 36,然后应用了最后一层的池化,最终尺寸就是18 * 18。所以第一层全连接层的输入数据的尺寸是16 * 18 * 18。三个全连接层所做的事很类似,就是不断训练,最后输出一个二分类数值。
net类的forward函数表示前向计算的整个过程。forward接受一个input,返回一个网络输出值,中间的过程就是一个调用init函数中定义的层的过程。
F.relu是一个激活函数,把所有的非零值转化成零值。此次图像识别的最后关键一步就是真正的循环训练操作。
在这里我们进行了50次训练,每次训练都是批量获取train_loader中的训练数据、梯度清零、计算输出值、计算误差、反向传播并修正模型。我们以每200次计算的平均误差作为观察值。
下面进行测试环节:
最后会得到一个识别的准确率。
三.完整代码如下:
欢迎各位批评指正~















 846
846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









