









目录
前言
本次只是针对世界杯比赛比分汇总表做了两个专题分析展示,一个是夺冠球队进失球率,一个是夺冠球队顺逆风球情况
一、数据集介绍
赛事数据链接:世界杯数据可视化分析赛题与数据-天池大赛-阿里云天池
本次数据分析项目包括3张来自FIFA官方数据整理的基础数据表
世界杯成绩信息表:WorldCupsSummary
包含了所有21届世界杯赛事(1930-2018)的比赛主办国、前四名队伍、总参赛队伍、总进球数、现场观众人数等汇总信息,包括如下字段:
- Year: 举办年份
- HostCountry: 举办国家
- Winner: 冠军队伍
- Second: 亚军队伍
- Third: 季军队伍
- Fourth: 第四名队伍
- GoalsScored: 总进球数
- QualifiedTeams: 总参赛队伍数
- MatchesPlayed: 总比赛场数
- Attendance: 现场观众总人数
- HostContinent: 举办国所在洲
- WinnerContinent: 冠军国家队所在洲
世界杯比赛比分汇总表:WorldCupMatches.csv
包含了所有21届世界杯赛事(1930-2014)单场比赛的信息,包括比赛时间、比赛主客队、比赛进球数、比赛裁判等信息。包括如下字段:
- Year: 比赛(所属世界杯)举办年份
- Datetime: 比赛具体日期
- Stage: 比赛所属阶段,包括 小组赛(GroupX)、16进8(Quarter-Final)、半决赛(Semi-Final)、决赛(Final)等
- Stadium: 比赛体育场
- City: 比赛举办城市
- Home Team Name: 主队名
- Away Team Name: 客队名
- Home Team Goals: 主队进球数
- Away Team Goals: 客队进球数
- Attendance: 现场观众数
- Half-time Home Goals: 上半场主队进球数
- Half-time Away Goals: 上半场客队进球数
- Referee: 主裁
- Assistant 1: 助理裁判1
- Assistant 2: 助理裁判2
- RoundID: 比赛所处阶段ID,和Stage字段对应
- MatchID: 比赛ID
- Home Team Initials: 主队名字缩写
- Away Team Initials: 客队名字缩写
世界杯球员信息表:WorldCupPlayers.csv
- RoundID: 比赛所处阶段ID,同比赛信息表的RoundID字段
- MatchID: 比赛ID
- Team Initials: 队伍名
- Coach Name: 教练名
- Line-up: 首发/替补
- Shirt Number: 球衣号码
- Player Name: 队员名
- Position: 比赛角色,包括:C=Captain, GK=Goalkeeper
- Event: 比赛事件,包括进球、红/黄牌等
二、读取数据,去重
import pandas as pd
df=pd.read_csv("/WorldCupMatches.csv")
df.shape
# (852, 19)
df[df.duplicated()] # 筛选重复值 16个重复值
df=df.drop_duplicates() #删除重复项
df.shape
#(836, 19)
三、夺冠球队进失球率展示
1. 计算进球数、进球率及场次
# 主队进球数
data1=pd.DataFrame(df.groupby("Home Team Name")["Home Team Goals"].agg(["count",'sum']).sort_values('sum',ascending=False).reset_index())
data1.rename(columns={'Home Team Name': '球队','count': '场次','sum':'进球数'}, inplace=True)
# 客队进球数
data2=pd.DataFrame(df.groupby("Away Team Name")["Away Team Goals"].agg(["count",'sum']).sort_values('sum',ascending=False).reset_index())
data2.rename(columns={'Away Team Name': '球队','count': '场次','sum':'进球数'}, inplace=True)
# 合并
data3=data1.merge(data2,on="球队",how="outer")
data3=data3.fillna(0) # 因为部分球队没有作为主队出场过,所以合并后会有NaN,用0填充
data3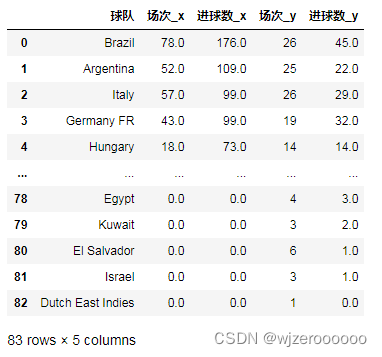
data3["总场次"]=data3["场次_x"]+data3["场次_y"]
data3["总进球数"]=data3["进球数_x"]+data3["进球数_y"]
data3["进球率"]=(data3["总进球数"]/data3["总场次"]).round(2)
data3.sort_values("进球率",ascending=False)[:10]| 球队 | 场次_x | 进球数_x | 场次_y | 进球数_y | 总场次 | 总进球数 | 进球率 |
| Hungary | 18 | 73 | 14 | 14 | 32 | 87 | 2.72 |
| Brazil | 78 | 176 | 26 | 45 | 104 | 221 | 2.12 |
| Germany FR | 43 | 99 | 19 | 32 | 62 | 131 | 2.11 |
| Germany | 32 | 66 | 12 | 27 | 44 | 93 | 2.11 |
| Turkey | 2 | 10 | 8 | 10 | 10 | 20 | 2 |
| France | 29 | 66 | 30 | 40 | 59 | 106 | 1.8 |
| Netherlands | 29 | 49 | 21 | 37 | 50 | 86 | 1.72 |
| Soviet Union | 18 | 43 | 13 | 10 | 31 | 53 | 1.71 |
| Argentina | 52 | 109 | 25 | 22 | 77 | 131 | 1.7 |
| Denmark | 7 | 13 | 9 | 14 | 16 | 27 | 1.69 |
进球率排名前十的球队。
2. 计算失球数、失球率及场次
# 主队失球数
data4=pd.DataFrame(df.groupby("Home Team Name")["Away Team Goals"].agg(["count",'sum']).sort_values('sum',ascending=False).reset_index())
data4.rename(columns={'Home Team Name': '球队','count': '场次','sum':'失球数'}, inplace=True)
# 客队失球数
data5=pd.DataFrame(df.groupby("Away Team Name")["Home Team Goals"].agg(["count",'sum']).sort_values('sum',ascending=False).reset_index())
data5.rename(columns={'Away Team Name': '球队','count': '场次','sum':'失球数'}, inplace=True)
# 合并填充
data6=data4.merge(data5,on="球队",how="outer")
data6=data6.fillna(0)
# 失球率
data6["总场次"]=data6["场次_x"]+data6["场次_y"]
data6["总失球数"]=data6["失球数_x"]+data6["失球数_y"]
data6["失球率"]=(data6["总失球数"]/data6["总场次"]).round(2)
data6.sort_values("失球率",ascending=True)[:10]| 球队 | 场次_x | 失球数_x | 场次_y | 失球数_y | 总场次 | 总失球数 | 失球率 |
| Angola | 1 | 1 | 2 | 1 | 3 | 2 | 0.67 |
| rn">Republic of Ireland | 5 | 2 | 8 | 8 | 13 | 10 | 0.77 |
| Wales | 1 | 1 | 4 | 3 | 5 | 4 | 0.8 |
| German DR | 3 | 2 | 3 | 3 | 6 | 5 | 0.83 |
| England | 35 | 20 | 27 | 36 | 62 | 56 | 0.9 |
| Italy | 57 | 41 | 26 | 36 | 83 | 77 | 0.93 |
| Netherlands | 29 | 20 | 21 | 28 | 50 | 48 | 0.96 |
| Brazil | 78 | 66 | 26 | 36 | 104 | 102 | 0.98 |
| Norway | 1 | 0 | 7 | 8 | 8 | 8 | 1 |
| Serbia | 1 | 1 | 2 | 2 | 3 | 3 | 1 |
失球率由低到高排名前十的球队。
3. 夺冠国家进失球率矩阵图
# 合并数据表
data7=data3.merge(data6,on="球队",how="outer")
data7=data7[['球队','总场次_x','总进球数','进球率','总失球数','失球率']]
data7.rename(columns={'总场次_x': '总场次'}, inplace=True)
# 画图
import numpy as np
col=["Brazil","Italy","Germany FR","Argentina","France","Uruguay","England","Germany","Spain"]
result=[]
for i in col:
result.append(data7[data7["球队"]==i])
result=np.array(result)
result=result.reshape(9,6)
result=pd.DataFrame(result,index=col,columns=data7.columns)
result=result.iloc[:,1:].astype('float')
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.family']='sans-serif'
mpl.rcParams['font.sans-serif']=[u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
minx = min(result["失球率"])
maxx = max(result["失球率"])
miny = min(result["进球率"])
maxy = max(result["进球率"])
plt.figure(figsize=(8,8),dpi=100)
for i in range(result.shape[0]):
plt.scatter(x=result["失球率"][i],y=result["进球率"][i],s=result["总场次"][i]*20,alpha=0.65,cmap='viridis')
plt.xlim(xmin= maxx+0.1,xmax=minx-0.1) # 将失球率从大到小设定X轴
plt.vlines(x=result['失球率'].mean(), ymin=miny-0.1, ymax=maxy+0.1,
colors='black', linewidth=1)
plt.hlines(y=result['进球率'].mean(), xmin=minx-0.1, xmax=maxx+0.1,
colors='black', linewidth=1)
for x,y,z in zip(result["失球率"],result["进球率"],col):
plt.text(x, y, z, ha='center',fontsize=10)
plt.xlabel("高<—————— 失球率(%) ——————>低",fontsize=15)
plt.ylabel("低<—————— 进球率(%) ——————>高",fontsize=15)
plt.title("夺冠国家进失球率-波士顿矩阵图", fontsize=20)
plt.show()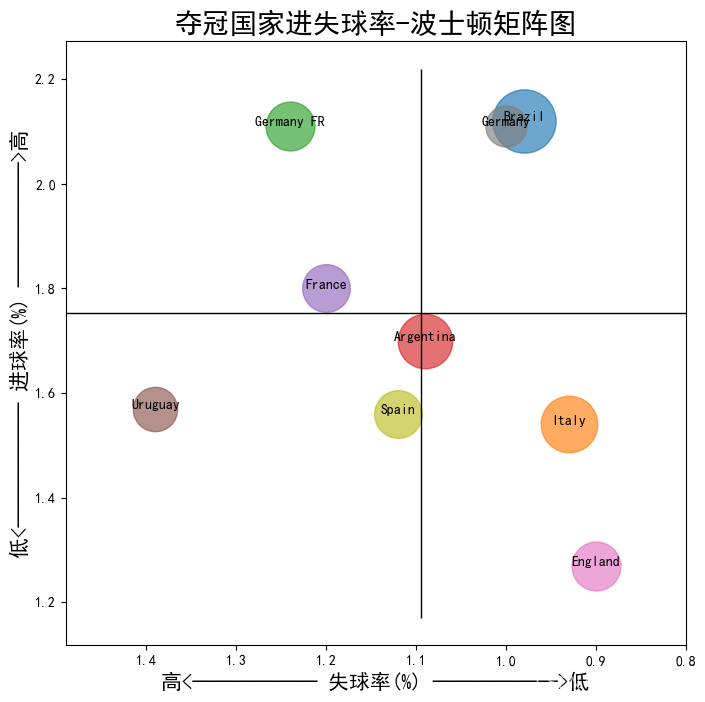
这里可以看出,巴西及德国的攻守比较平衡,意大利和英格兰偏重防守。
四、夺冠球队顺逆风球情况
1. 构造胜负关系
df["Half-Goal-difference"]=df["Half-time Home Goals"]-df["Half-time Away Goals"] #半场净胜球
df["Away-Half-Goal-difference"]=df["Half-time Away Goals"]-df["Half-time Home Goals"] #作为客队半场净胜球
df["Goal-difference"]=df["Home Team Goals"]-df["Away Team Goals"] #全场净胜球
df["Away-Goal-difference"]=df["Away Team Goals"]-df["Home Team Goals"] #作为客队全场净胜球
# 半场输赢关系
df.loc[df["Half-Goal-difference"] >0 ,'Half-result'] = '6'
df.loc[df["Half-Goal-difference"] ==0 ,'Half-result'] = '0'
df.loc[df["Half-Goal-difference"] <0 ,'Half-result'] = '-3'
df.loc[df["Away-Half-Goal-difference"] >0 ,'Away-Half-result'] = '6'
df.loc[df["Away-Half-Goal-difference"] ==0 ,'Away-Half-result'] = '0'
df.loc[df["Away-Half-Goal-difference"] <0 ,'Away-Half-result'] = '-3'
# 全场输赢关系
df.loc[df["Goal-difference"] >0 ,'result'] = '1'
df.loc[df["Goal-difference"] ==0 ,'result'] = '0'
df.loc[df["Goal-difference"] <0 ,'result'] = '-1'
df.loc[df["Away-Goal-difference"] >0 ,'Away-result'] = '1'
df.loc[df["Away-Goal-difference"] ==0 ,'Away-result'] = '0'
df.loc[df["Away-Goal-difference"] <0 ,'Away-result'] = '-1'
# 相减后为字符串,转化为数字
df["Half-result"]=df["Half-result"].astype("int32")
df["result"]=df["result"].astype("int32")
df["Away-Half-result"]=df["Away-Half-result"].astype("int32")
df["Away-result"]=df["Away-result"].astype("int32")赋值6,-3是为了区分胜、平、负三种关系,如果按照足球规则3分,1分,0分赋值则无法完全区分。
df["v1"]=df["Half-result"]-df["result"]
df["v2"]=df["Away-Half-result"]-df["Away-result"]
print(df["v1"].value_counts())
print(df["v2"].value_counts())这里就得到了主客两种情况的结果统计
| 作为主队结果 | 作为客队结果 | 类别说明 | ||||||
| 5 | 269 | -2 | 269 | 5 | 上半场赢,全场赢 | |||
| -1 | 176 | 1 | 176 | -1 | 上半场平,全场赢 | |||
| 0 | 134 | 0 | 134 | 0 | 上半场平,全场平 | |||
| -2 | 97 | 5 | 97 | -2 | 上半场输,全场输 | |||
| 1 | 70 | -1 | 70 | 1 | 上半场平,全场输 | |||
| -4 | 34 | 7 | 34 | -4 | 上半场输,全场赢 | |||
| -3 | 27 | 6 | 27 | -3 | 上半场输,全场平 | |||
| 6 | 25 | -3 | 25 | 6 | 上半场赢,全场平 | |||
| 7 | 4 | -4 | 4 | 7 | 上半场赢,全场输 | |||
2. 主、客队胜负类别可视化
import matplotlib as mpl
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
mpl.rcParams["font.sans-serif"]=["SimHei"]
mpl.rcParams["axes.unicode_minus"]=False
df1=pd.DataFrame(df["v1"].value_counts()/df["v1"].count())
df2=pd.DataFrame(df["v2"].value_counts()/df["v2"].count())
g=["5","-1","0","-2","1","-4","-3","6","7"]
g1=["-2","1","0","5","-1","7","6","-3","-4"]
c=["red","yellow","violet","cyan","lightseagreen","silver","orange","olive","green"]
c1=["cyan","lightseagreen","violet","red","yellow","green","olive","orange","silver"]
t=df1["v1"]
t1=df2["v2"]
wedgeprops = {'width':0.3}
explode = (0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.15)
fig = plt.figure(figsize=(15,15))
plt.subplot(121)
plt.pie(t,explode=explode,labels=g,autopct="%3.1f%%",startangle=60,colors=c,wedgeprops=wedgeprops)
plt.title("作为主队半场与全场胜负关系占比")
plt.subplot(122)
plt.pie(t1,explode=explode,labels=g1,autopct="%3.1f%%",startangle=60,colors=c1,wedgeprops=wedgeprops)
plt.title("作为客队半场与全场胜负关系占比")
plt.show()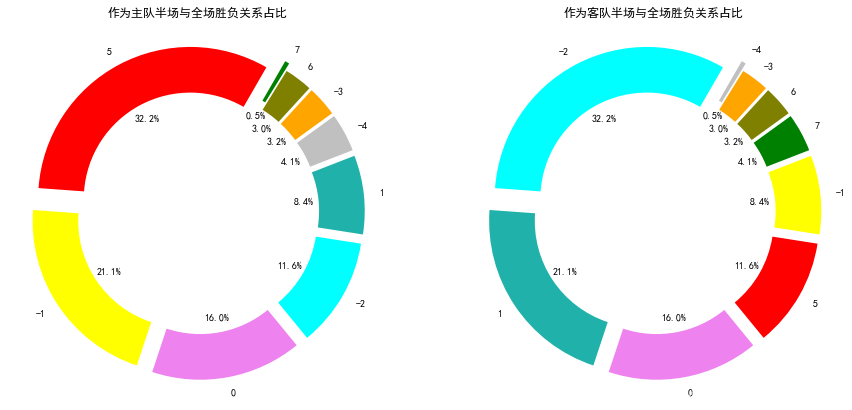
作为主队,在上半场不败的前提下,全场获胜的场次占比达到53.3%。
作为客队,在上半场打平或者输球的情况下,全场输球的占比达到53.3%。
3. 顺、逆风球球队柱图
df3=df[df["v1"]==5] # 顺风球
df3_away=df[df["v2"]==5]
df4=df[(df["v1"]==-3)|(df["v1"]==-4)] # 逆风球
df4_away=df[(df["v2"]==-3)|(df["v2"]==-4)]
fig = plt.figure(figsize=(12,8))
plt.subplot(221)
df3["Home Team Name"].value_counts().sort_values(ascending=True)[-10:].plot(kind= 'barh')
plt.title("作为主队顺风球球队前十")
plt.subplot(222)
df3_away["Away Team Name"].value_counts().sort_values(ascending=True)[-10:].plot(kind= 'barh')
plt.title("作为客队顺风球球队前十")
plt.subplot(223)
df4["Home Team Name"].value_counts().sort_values(ascending=True)[-10:].plot(kind= 'barh')
plt.title("作为主队逆风球球队前十")
plt.subplot(224)
df4_away["Away Team Name"].value_counts().sort_values(ascending=True)[-10:].plot(kind= 'barh')
plt.title("作为客队逆风球球队前十")
plt.subplots_adjust(wspace=0.5,hspace=0.3)
plt.show()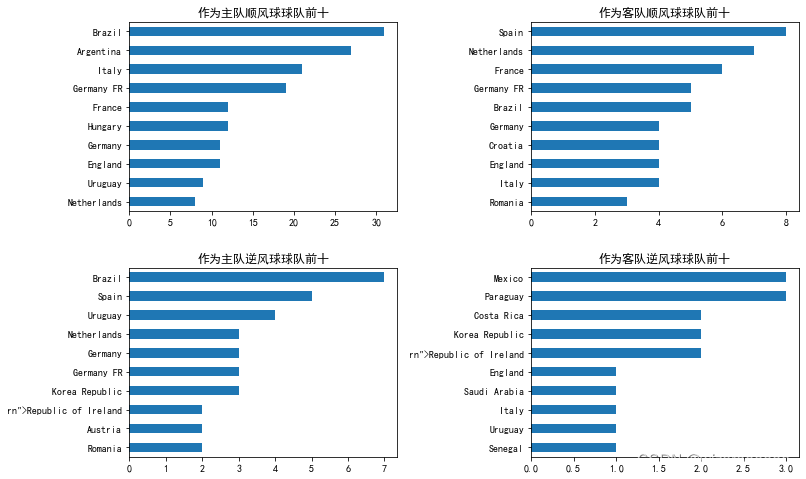
其实世界杯是不分主客场的,小组赛只是针对双方球衣的选择问题,抽到主队的就穿该队的主场球衣,也就是该队的传统比赛服,如西班牙的红色、法国的三色球衣、巴西的黄色、阿根廷的蓝白色等。打到淘汰赛就不是了,16进8小组第一的是主队,而四分之一比如A1对C1,A1就是主队
4. 夺冠国家胜负类别可视化
4.1 作为主队时
plt.figure(figsize=(20,20))
for i, j in enumerate(col):
df_home=df[df["Home Team Name"]==j]
data=pd.DataFrame(df_home.loc[:,"v1"].value_counts()/df_home.loc[:,"v1"].count())
plt.subplot(3,3,i+1)
plt.pie(data["v1"],labels=data.index,autopct="%3.1f%%",startangle=60,colors=c,\
textprops={'fontsize': 15},wedgeprops={'width':0.3},pctdistance=0.7)
plt.title(j, fontsize=18)
plt.show()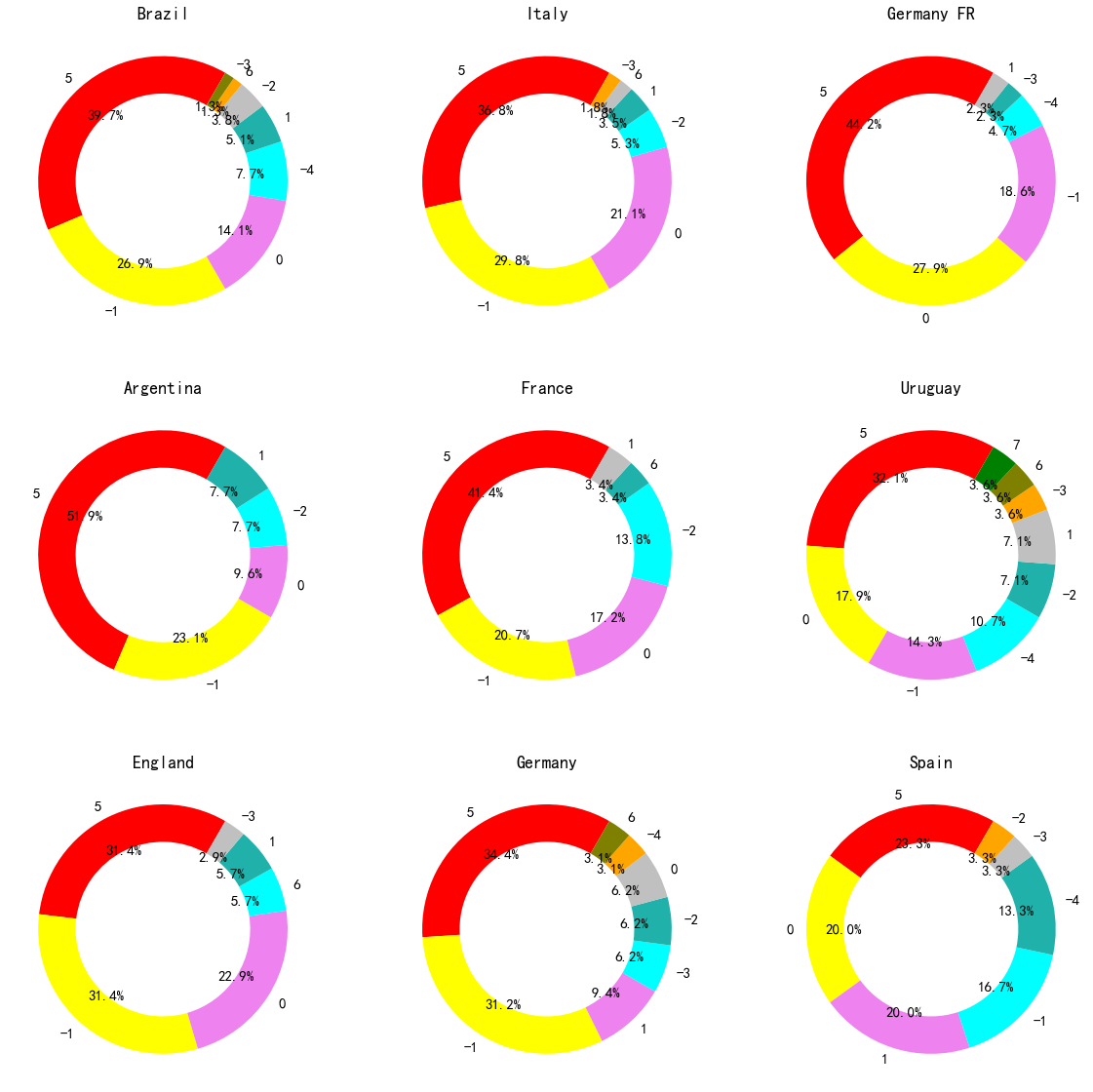
作为主队时,各个球队赢球的场次占比都比较多,例如巴西,作为主队(身着黄色球衣)时,在上半场领先的情况下,全场就没有输过球。且全场输球的场次占比只有8.9%,难道主场球衣真有胜负加持?
4.2 作为客队时
plt.figure(figsize=(20,20))
for i, j in enumerate(col):
df_away=df[df["Away Team Name"]==j]
data1=pd.DataFrame(df_away.loc[:,"v2"].value_counts()/df_away.loc[:,"v2"].count())
plt.subplot(3,3,i+1)
plt.pie(data1["v2"],labels=data1.index,autopct="%3.1f%%",startangle=60,\
colors=c1,textprops={'fontsize': 15},wedgeprops={'width':0.3},pctdistance=0.7)
plt.title(j, fontsize=18)
plt.show()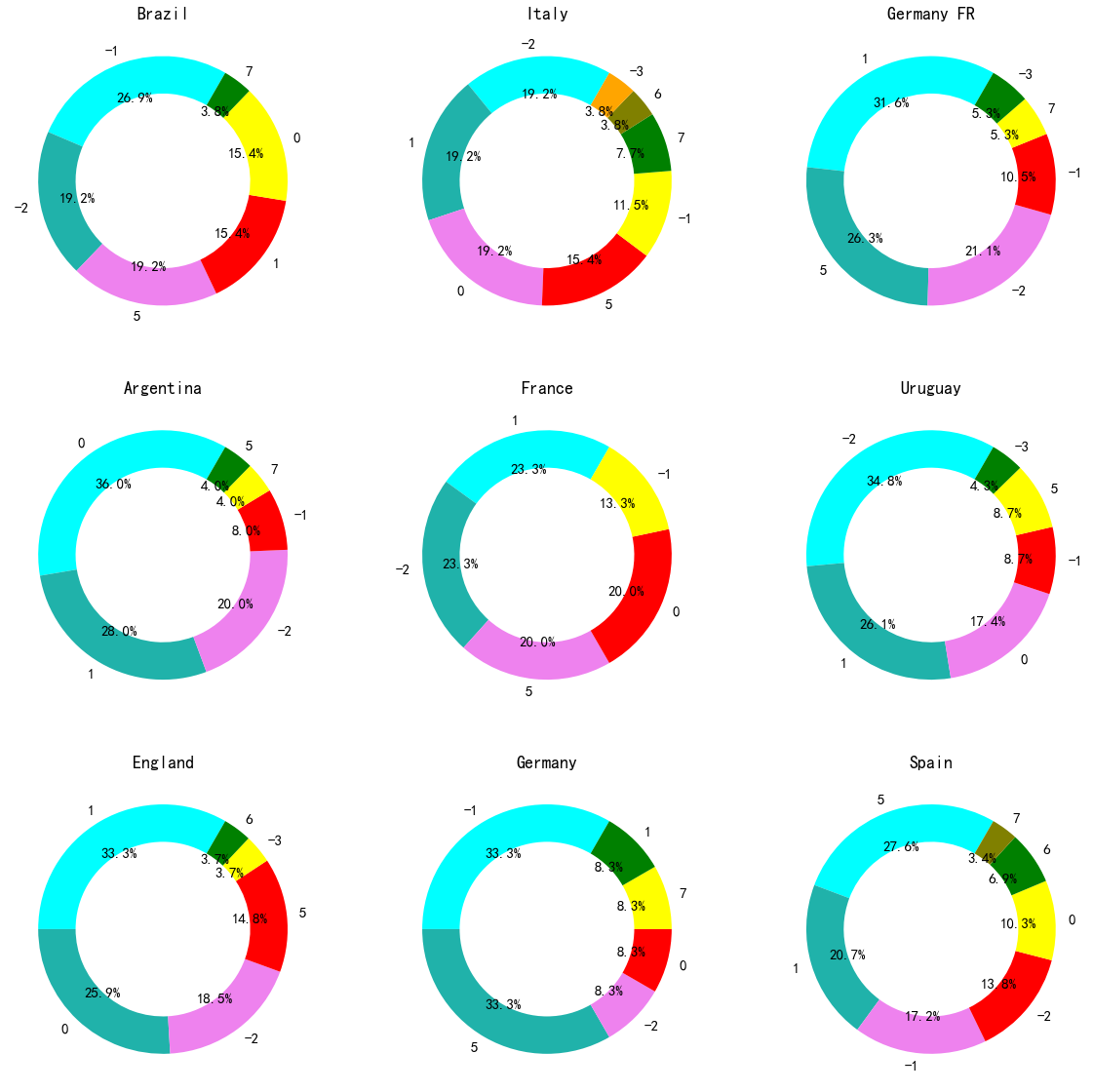
作为客队时,输球的场次占比高于作为主队,例如巴西:全场输的比例达到38.4%
五、其余可视化部分展示
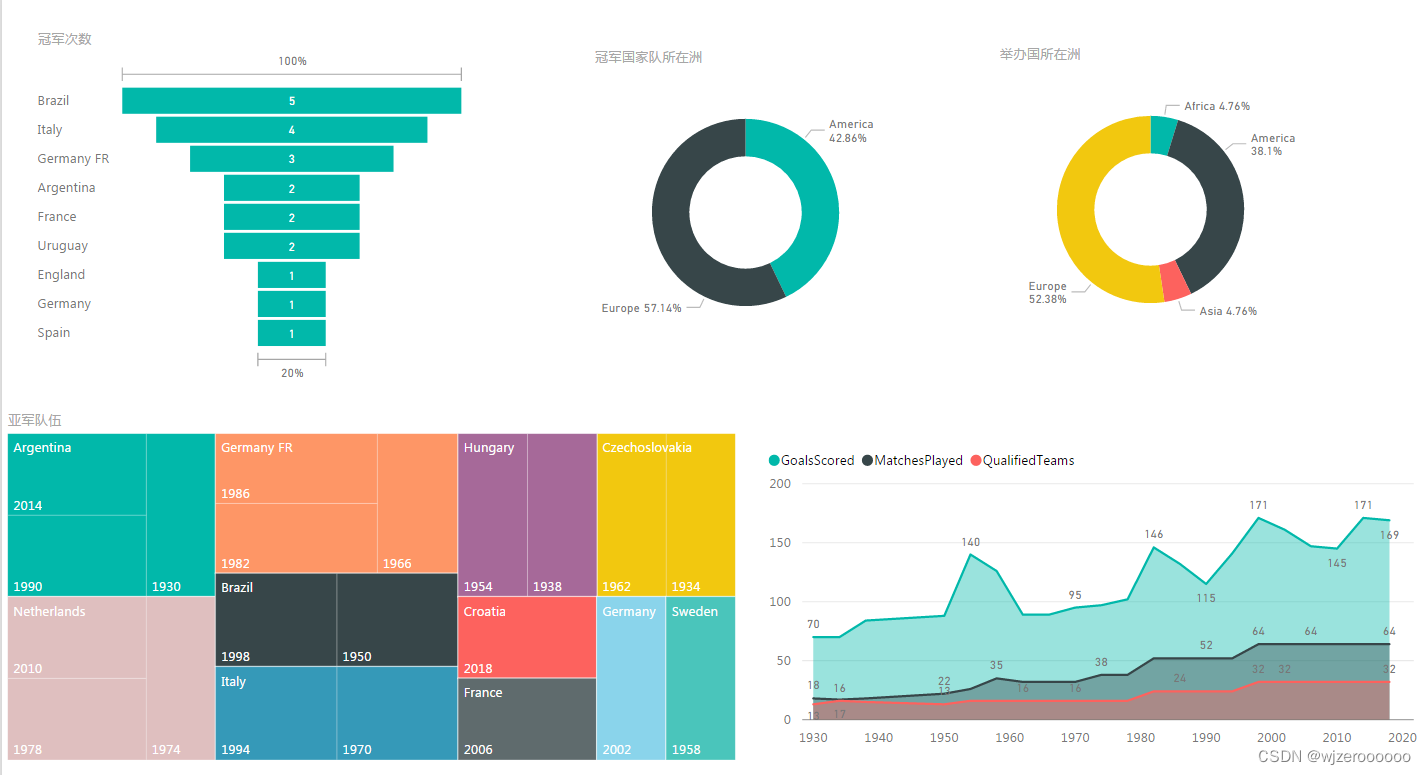
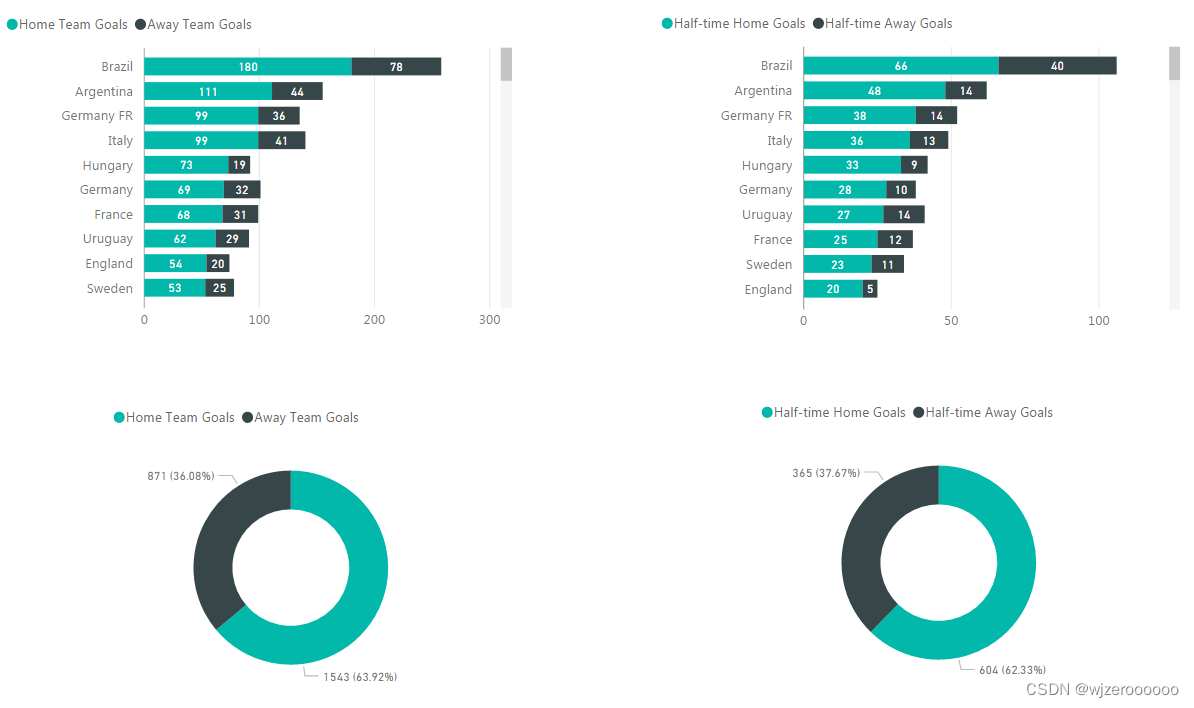
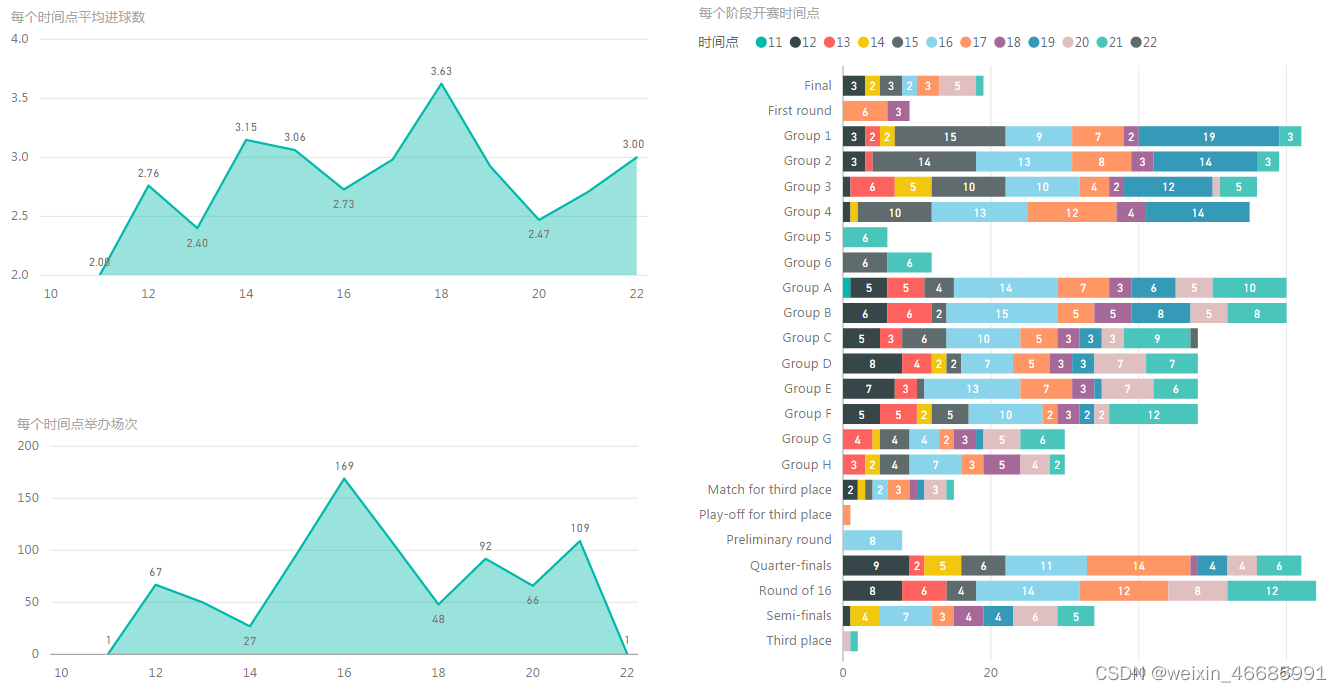
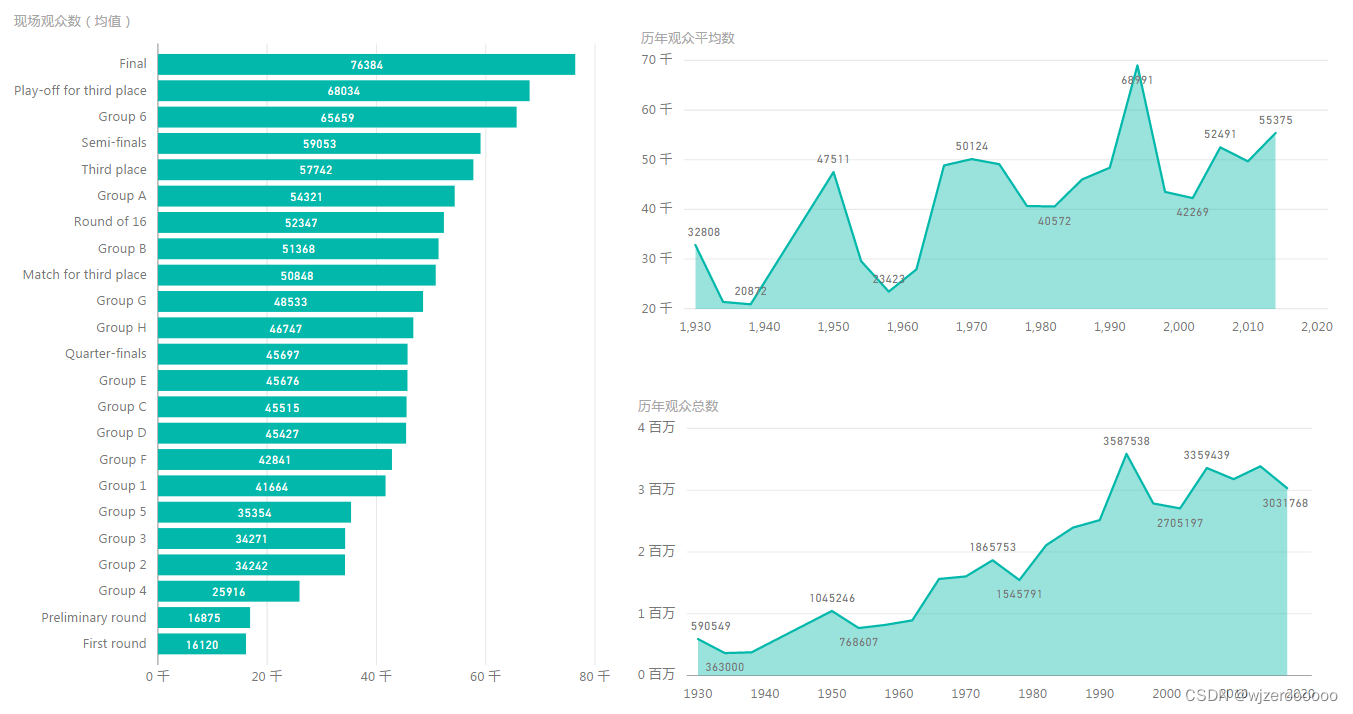
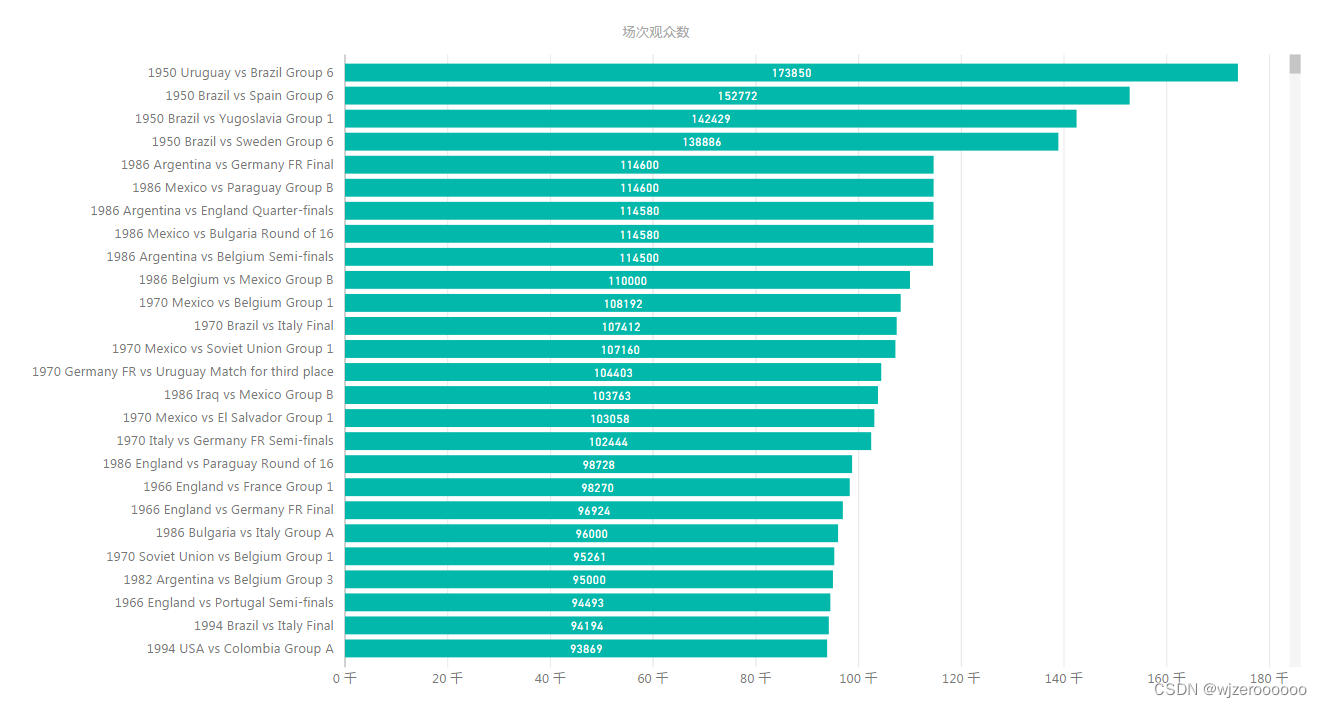
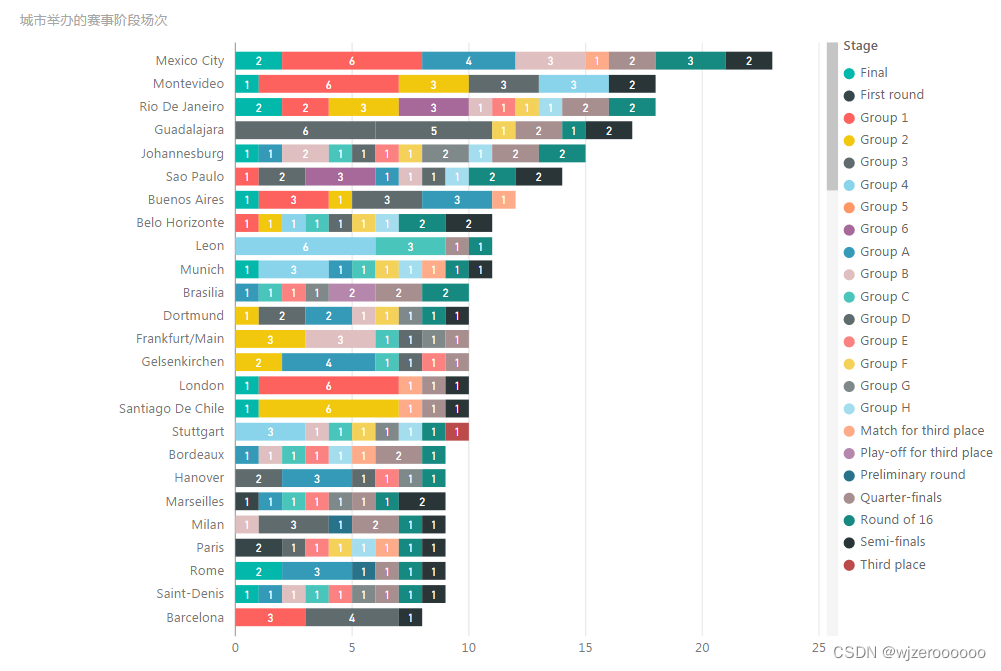
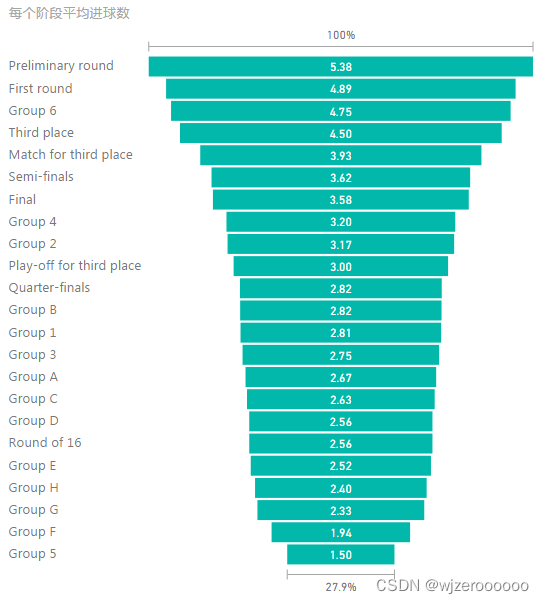
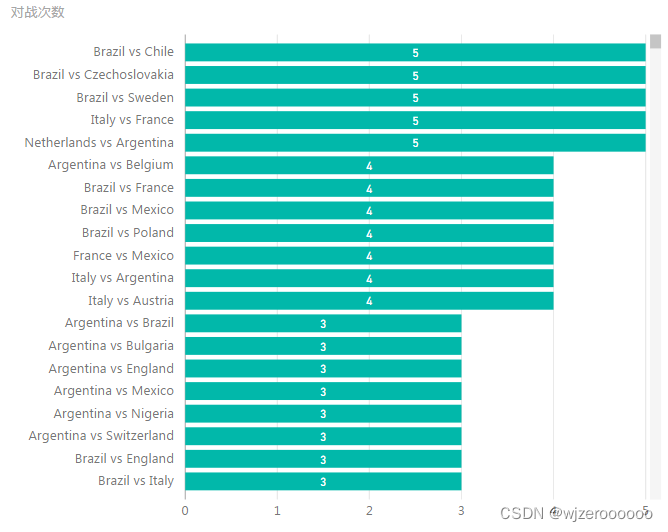
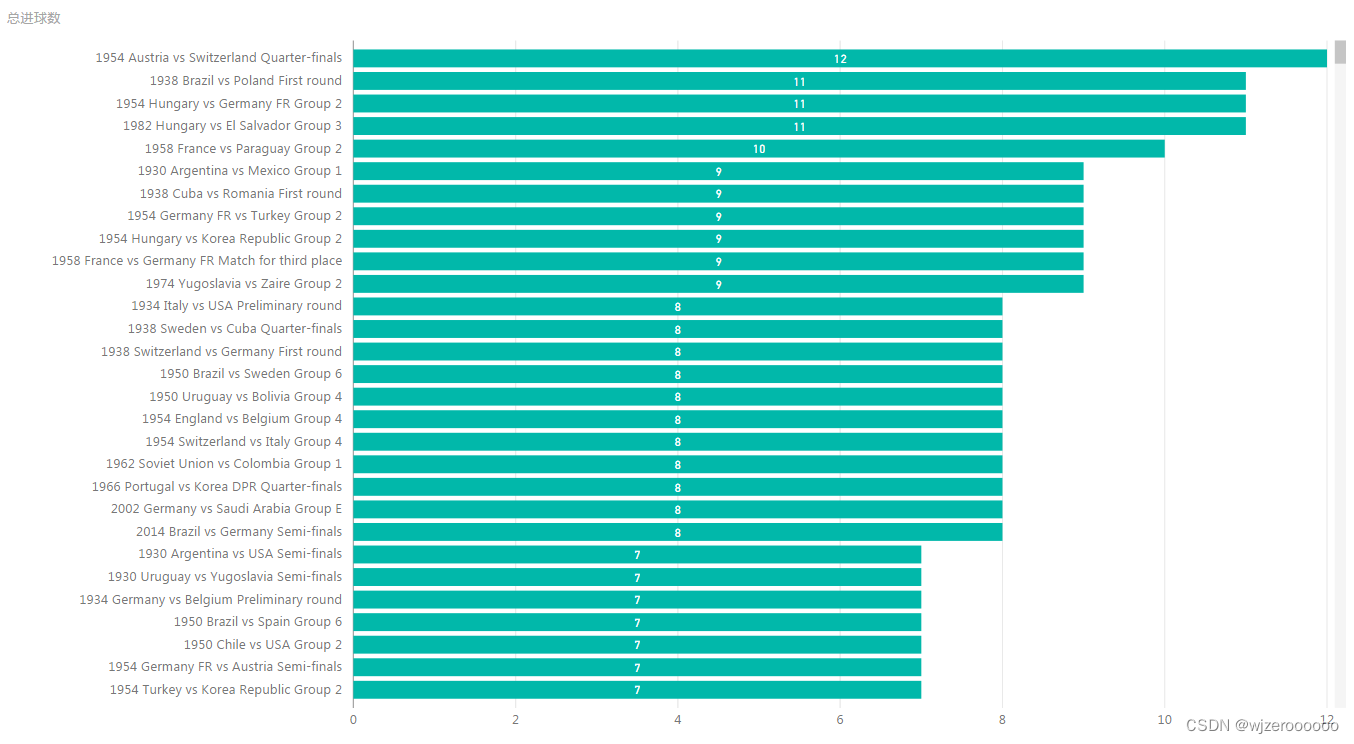
总结
原始数据有3个表格,可以选择自己感兴趣的方向分析,总的来说是一次不错的数据分析锻炼。

















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









