









1.时间序列的创建
1.将datetime转换为timestamp
- pandas中,时间戳Timestamp(Series派生的子类表示)
from datetime import datetime
import pandas as pd
import numpy as np
pd.to_datetime('20220801')
pd.to_datetime('2022-08/01')
pd.to_datetime('2022-08-01')
>>Timestamp('2022-08-01 00:00:00')
2.创建时间序列的Series对象
data_index = pd.to_datetime(['2022-08-01','2022/09/01','20221001'])
pd.Series([1,22,3],index =data_index)
>>
2022-08-01 1
2022-09-01 22
2022-10-01 3
dtype: int64
- 通过datetime列表创建
data_index = [datetime(2011,1,2),datetime(2012,2,3),datetime(2022,8,22)]
pd.Series(np.arange(3),index=data_index)
>>
2011-01-02 0
2012-02-03 1
2022-08-22 2
dtype: int32
- 固定频率时间序列创建
- data_range() 函数创建Datetimeindex对象
- pd.date_range(
start=None,
end=None,
periods=None,
freq=None,
tz=None,
normalize=False,
name=None,
closed=None,
**kwargs,
) - start 表示开始日期
end 表示结束日期
periods表示产生多少个时间戳索引值
freq表示计时单位
至少指定其中三个参数
c = pd.date_range(start = '2021-01-02',end = '2021-02-03',freq = 'W-SUN')
>>DatetimeIndex(['2021-01-03', '2021-01-10', '2021-01-17', '2021-01-24',
'2021-01-31'],
dtype='datetime64[ns]', freq='W-SUN')
# W-SUN 为每周日的日期
pd.Series([1,2,3,44,55],index=c)
>>2021-01-03 1
2021-01-10 2
2021-01-17 3
2021-01-24 44
2021-01-31 55
Freq: W-SUN, dtype: int64
- 偏移2周2小时为周期
from pandas.tseries.offsets import *
a = Week(2)+Hour(2)
c = pd.date_range(start = '2021-01-02',freq = a,periods=5)
pd.Series([1,2,3,44,55],index=c)
>>2021-01-02 00:00:00 1
2021-01-16 02:00:00 2
2021-01-30 04:00:00 3
2021-02-13 06:00:00 44
2021-02-27 08:00:00 55
Freq: 338H, dtype: int64
- freq相关参数别名

- 将月度数据聚合为季度
# 把这一列作为时间索引
data.index = pd.to_datetime(data['指标'])
# 日期都算成月末
data.index = data.index + pd.offsets.MonthEnd(0)
#聚合为季度
data.iloc[:,:9].resample('Q').sum()/3
3.创建时间序列的DateFrame对象
list_1 = [[1,2,3],[4,5,6],[11,22,33]]
data_index = [datetime(2011,1,2),datetime(2012,2,3),datetime(2022,8,22)]

2.提取固定时间数据
data_index = pd.to_datetime(['2022-08-01','20220901','20221001'])
data_se = pd.Series([1,22,3],index =data_index)
data_se
2011-01-02 1
2012-02-03 22
2022-08-22 3
dtype: int64
- 取某日期的数据
data_se['2011-01-02']
>> 1
- 取所有年的数据
data_se['2011']
>>2011-01-02 1
dtype: int64
- 给所有日期进行排序(sort_index())
data_index = pd.to_datetime(['2022-09-09','20220901','20221001'])
data_se = pd.Series([1,22,3],index =data_index)
data_se
>>2022-09-09 1
2022-09-01 22
2022-10-01 3
dtype: int64
data_se = data_se.sort_index()
>>2022-09-01 22
2022-09-09 1
2022-10-01 3
dtype: int64
- 取某个时间段的数据(turncate)需先排序才可使用该方法(before after)
data_se.truncate(before='2022-09-08')
>>2022-09-09 1
2022-10-01 3
dtype: int64
3.时间序列的移动
- shift(periods=1,freq=None,axis=0) 方法,用来前后移动数据,但索引不发生改变(periods 也可以为负数)
- 向后移动 c.shift(1)
>>原数据 --- c
2021-01-02 1
2021-01-16 2
2021-01-30 3
2021-02-13 44
2021-02-27 55
Freq: 2W, dtype: int64`
>>移动后的数据 --- c.shift(1)
2021-01-02 NaN
2021-01-16 1.0
2021-01-30 2.0
2021-02-13 3.0
2021-02-27 44.0
Freq: 2W, dtype: float64
- c.diff(1) 一阶差分 减去前一个数据
>>原数据 --- c
2021-01-02 1
2021-01-16 2
2021-01-30 3
2021-02-13 44
2021-02-27 55
Freq: 2W, dtype: int64
>>移动后的数据 --- c.diff(1)
2021-01-02 NaN
2021-01-16 1.0
2021-01-30 1.0
2021-02-13 41.0
2021-02-27 11.0
Freq: 2W, dtype: float64
4.ARIMA模型建立
- 平稳性要求序列的均值和方差不发生明显的变化
- 单位根检验主要是检验p值是否大于0.05,大于0.05的时间序列是非平稳的,需要进行差分。p值小于0.05的是平稳的时间序列,如果使用差分之后的数据进行预测,预测值也需要重新计算差分之前的值,得到真实的预测值。
from statsmodels.tsa.stattools import adfuller as ADF
ADF(data['diff_1'])

-
差分 目的为了选取 d
-
1.将一个表格(DateFrame)对象中时间的数据转换为时间序列数据
# data['date'] 为表格中的时间列
data = pd.read_excel(r'C:\Users\merit\Desktop\工作簿1.xlsx')
datas = pd.to_datetime(data['date'].values,format='%Y%M%D')
# 将该列设置为索引
data_date = data.set_index(datas)
- 2.绘制折线图查看数据分布是否平稳
def draw_ts(timeSeries):
timeSeries.plot(color='blue')
plt.legend()
plt.show()
a = draw_ts(data_date['value'])
a

- 3.筛选一年值的平均值(按周期重采样)
data_date['value'].resample('12M').mean()
- 4.截取所需时间日期数据(1949-1959)
data_date = data_date["1949":"1959"]
b = draw_ts(data_date['value'])
b
- 5.差分后监测数据平稳性(目的:确定d,然后删除这俩列)
data_date = data_date.drop(['date'],axis=1)
data_date['diff_1']=data_date.diff()
draw_ts(data_date['diff_1'])
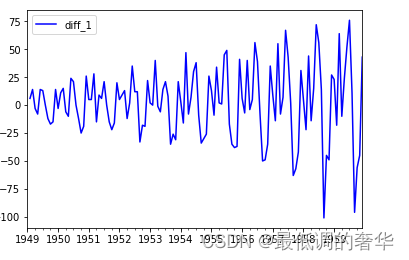
- 二阶差分
data_date['diff_2']=data_date['diff_1'].diff()
draw_ts(data_date['diff_2'])
# 然后单位根检验(平稳即确定 d)
from statsmodels.tsa.stattools import adfuller as ADF
ADF(data['diff_2'])
# 删除这俩列
del data_date['diff_1']
del data_date['diff_2']
- 6.确定p,q
pmax = 5
qmax = 5
bic_matrix = [] #bic矩阵
for p in range(pmax+1):
tmp = []
for q in range(qmax+1): #存在部分报错,所以用try来跳过报错。
try:
tmp.append(ARIMA(data_date['value'],order=(p,2,q)).fit().bic)
except:
tmp.append(None)
bic_matrix.append(tmp)
bic_matrix = pd.DataFrame(bic_matrix) #从中可以找出最小值
p,q = bic_matrix.stack().idxmin()
# #先用stack展平,然后用idxmin找出最小值位置。
print(u'BIC最小的p值和q值为:%s、%s' %(p,q))
>> BIC最小的p值和q值为:3、5
- 7.确定完p,d,q后进行arima模型建立(二阶差分后预测的数据,还需要经过计算才能得到原数据预测值。order =(p,d,q)d为差分阶数)
from statsmodels.tsa.arima_model import ARIMA
model = ARIMA(data, order=(3,2,5))
result = model.fit()
# 预测该部分日期内容
pred = result.predict('19600101','19610101')
print(len(pred))
print(pred[-13:])
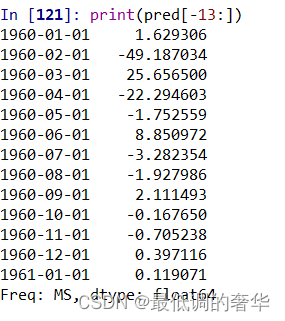
5.完整代码建立ARIMA模型,并对后十天数据进行预测,其中预测的值为二阶差分后的值,还需进行计算来得到预测值
import numpy as np
import pandas as pd
from datetime import datetime
import matplotlib.pylab as plt
from statsmodels.tsa.stattools import adfuller
data = pd.read_excel(r'C:\Users\merit\Desktop\工作簿1.xlsx')
data.head(5)
data.index = data['date']
data = data.drop(['date'],axis=1)
data = data.astype({'value':'float'})
data.dtypes
from statsmodels.tsa.arima.model import ARIMA
model = ARIMA(data, order=(1,1,1))
result = model.fit()
result
pred = result.predict(start=1, end =len(data) + 10 ) # 从训练集第0个开始预测(start=1表示从第0个开始),预测完整个训练集后,还需要向后预测10个
print(len(pred))
print(pred[-10:])
















 7111
7111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











