







 本文详细介绍了A/B测试的流程,包括确立目标、设计实验、合理性检验、结果分析等方面。强调了如何确定实验个体、设计实验指标、计算最小样本量以及如何避免实验偏差。同时,提出了在实验不严谨情况下的处理方法,如合成对照组和倾向评分匹配。
本文详细介绍了A/B测试的流程,包括确立目标、设计实验、合理性检验、结果分析等方面。强调了如何确定实验个体、设计实验指标、计算最小样本量以及如何避免实验偏差。同时,提出了在实验不严谨情况下的处理方法,如合成对照组和倾向评分匹配。
本章内容:
- A/B测试流程简介
- 如何确立实验目标?
- 如何设计实验?
- 如何对实验的合理性进行检验?
- 如何分析实验结果?
- 如何处理实验不严谨的情况?
1. A/B测试的流程
📖A/B测试严格流程
- 确立目标
- 实验设计
- 运行实验,收集数据
- 合理性检验
- 数据分析
- 得到见解
2. 如何确立目标?
📖如何确立目标?
- 确定A/B测试要解决的问题
需要结合产品、运营、推广等角度的需求。
比如:VP的要求为增加广告,从而增加收入;而产品的要求为,增加广告不能影响用户体验;结合两方的需求,确立问题为如何增加广告才能不影响用户体验。进一步细化为广告时长增加多少,不会影响用户体验。
- 确定原假设、备择假设
设置原假设的标准为:不需要有任何改动的行为设定为原假设。
因为假设检验通常验证原假设是否成立,如果原假设不成立,则考虑存在备择假设的可能。将不需要有任何改动的行为作为原假设,更节省改动带来的人力、时间成本。
故上述案例中,可设定为: 原假设:广告时长不影响用户观看时长 备择假设:广告时长影响用户观看时长
3. 如何设计实验?(⭐)
📖设计实验的3个重点环节
- 确定实验个体,确保独立/随机分组
- 设计实验指标
- 确定最小样本量,以预估实验周期
3.1 如何确定实验个体,及分组?
📖什么是定义实验个体,及其规则?
定义实验个体:指找到一个字段,该字段需要尽可能独立,可以代表用户的唯一标识,比如用户名、登录账号等。
- 该字段不会有多个个体同时使用
- 该字段更换设备时不会影响个体识别
- 该字段方便获取
没有最佳字段,需要结合实验目标,判断不同字段对实验的影响来选择。
☑常用“个体”字段,及对比
| 字段 | 优点 | 缺点 | 解决方案 |
| 注册账号 | 稳定,易获取,更换设备的情况下不会更换个体 | 要求用户必须注册 | |
| 网络Cookie | 绑定唯一网络内容 | 更换设备/浏览器时影响识别个体 | 将多个设备/浏览器的个体联系起来,剔除重复个体 |
| IP | 便于获取 | 更换设备时影响个体识别 |
📖如何划分实验组和对照组?
- 对照组:原方案保持不变;上例中可为:原始广告时长(110秒)的非会员用户
- 实验组:采用新方案;上例中可为:较短广告时长(40秒)的非会员用户
(个人感觉上述划分不一定严谨,如果原始方案中,广告时长为110秒,需要在110秒的基础上加新的广告时长,那么应该对比的实验组应该设置为110+秒的非会员用户)
📖如何判断样本是否独立/随机?
- 样本不独立的表现
- 个体间存在社交联系。比如社交平台,那么一方可能会把消息告诉另一方,从而影响实验效果。可尝试切断社交联系,如选择没有相互互动数据用户
- 个体间存在此消彼长。比如滴滴平台,如果在同一地区,那么订单量就会此消彼长。可选择不同地域的用户。
- 样本不随机的表现
- 样本特征分布不均匀。比如实验组有25%为男,对照组有15%为女,那么就没有排除性别对标签的影响。增强随机性的方法:用户ID尾数的奇偶、哈希函数、mod函数
3.2 如何设计实验指标?
📖3种实验中涉及的指标
- 观测指标:衡量实验影响大小的指标,可以选择一个或多个。
- 参考指标:非实验直接指标,负责参考观测指标效果的指标。
- 监控指标:用于监控实验是否正常、有序、准确、合理。
📖如何设定观测指标?
- 将实验结果中衡量的指标细化,比如用户满意度,可以细化为用户观看时长、点赞数、弹幕数;
- 对细化指标做拆分,如用户性别拆分、等级拆分、地域拆分;
- 使用与收入相关的参考指标,如广告点击收入;
- 对参考指标细分,如用户观看广告时长
📖如何设定监控指标?
-
是否准确、便于计算,比如样本量是否如预期
🤷♀️例子:因为可能每天能收集到的样本量只有10个,最小样本量为100个,那么就需要对每天的样本量增长情况进行监控,如果样本量完全没增加,说明样本设计可能存在问题
-
测试开始前,实验组与对照组数据是否相似
3.3 如何确定最小样本量?
📖样本量设计的注意事项
- 样本量越大,对实验越有信心
- 常见实验组和对照组样本量之比为:1:1,但如果实验影响平台收入或其他关键指标,可以将影响指标组的样本量比例调低。
比如实验组为去除广告,对照组为不去除广告,去除广告会导致减少广告收入,这时调低实验组比例为3:7,则可以减少实验对收入的影响程度
📖假设检验中的两类错误
- 弃真错误(I类错误):原假设正确时,拒绝原假设的概率为 α \alpha α;
- 去伪错误(II类错误):当备择假设正确时,本应该拒绝原假设,却无法拒绝原假设的概率为 β \beta β;
- 统计功效:当备择假设正确,成功拒绝原假设的概率为 1 − β 1-\beta 1−β
🔑如何计算最小样本量?
-
单组样本量计算公式(当检验统计量为均值时):
n = 2 ∗ σ 2 ( Z β + Z α / 2 ) 2 d i f f e r e n c e 2 n=2*\frac{ \sigma^2(Z_{\beta}+Z_{\alpha / 2})^2 }{ difference^2 } n=2∗difference2σ2(Zβ+Zα/2)2
其中,
σ 2 \sigma^2 σ2为样本个体指标的方差,方差越大,需要的样本量越大;
Z α / 2 Z_{\alpha / 2} Zα/2为I类错误对应的Z值,显著性 α \alpha α越小,通常为0.05,需要的样本量越大;
Z β Z_{\beta} Zβ为II类错误对应的Z值;显著性 β \beta β越小,通常为0.2,需要的样本量越大;
difference为两组样本指标差的百分比;指标差越小,需要的样本量越大。
-
单组样本量计算公式(当检验统计量为比例时):
n = ( Z α / 2 ∗ 2 ∗ p 1 + p 2 2 ∗ ( 1 − p 1 + p 2 2 ) + Z β p 1 ∗ ( 1 − p 1 ) + p 2 ∗ ( 1 − p 2 ) ) 2 ∣ p 1 − p 2 ∣ 2 n=\frac{ (Z_{\alpha/2}*\sqrt{ 2*\frac{p_1+p_2}{2}* (1-\frac{p_1+p_2}{2}) }+ Z_{\beta}\sqrt{ p_1*(1-p_1)+p_2*(1-p_2) } )^2 }{ |p_1-p_2|^2 } n=∣p1−p2∣2(Zα/2∗2∗2p1+p2∗(1−2p1+p2)+Zβp1∗(1−p1)+p2∗(1−p2))2
☑样本量计算网站:
- 简易版:云眼:https://www.eyeofcloud.com/abtest-widget/124.html
- 考虑第二类错误:Evanmiller:https://www.evanmiller.org/ab-testing/sample-size.html
- 当检验统计量为数值:https://www.stat.ubc.ca/~rollin/stats/ssize/n2.html
🔑对比统计学中,参数估计的样本量确定公式
-
7.4.1 估计总体均值时样本量的确定
在重复抽样,或无限总体抽样条件下,估计误差为 z α / 2 σ n z_{\alpha/2}\frac{\sigma}{\sqrt{n}} zα/2nσ。
其中 z α / 2 z_{\alpha/2} zα/2的值和样本量n共同确定了估计误差的大小。 当确定 1 − α 1-\alpha 1−α时, z α / 2 z_{\alpha/2} zα/2就可以确定。
如果给定 z α / 2 z_{\alpha/2} zα/2和总体标准差 σ \sigma σ,就可以求得任一指定估计误差所需要的样本量,公式如下:
n = ( z α / 2 ) 2 σ 2 E 2 n=\frac{ (z_{\alpha/2})^2\sigma^2 }{ E^2 } n=E2(zα/2)2σ2
其中E代表所希望达到的估计误差。
如果 σ \sigma σ未知,可以用样本的标准差来代替;也可以用试验调查的办法,选择一个初始样本,以该样本的标准差作为 σ \sigma σ的估计值。 根据公式计算出来的样本数为非整数时,通常取成较大的整数,即样本量的圆整法则。
-
7.4.2 估计总体比例时样本量的确定
在重复抽样,或无限总体抽样条件下,估计误差为 z α / 2 π ( 1 − π ) n z_{\alpha/2} \sqrt{ \frac{\pi(1-\pi)}{n} } zα/2nπ(1−π)。
其中 z α / 2 z_{\alpha/2} zα/2的值、总体比例 π \pi π、样本量n共同确定了估计误差的大小。 当确定 1 − α 1-\alpha 1−α时, z α / 2 z_{\alpha/2} zα/2就可以确定。 总体比例的值是固定的,所以估计误差由样本来确定,样本量越大,估计误差就越小,估计的精度越好。
如果给定 z α / 2 z_{\alpha/2} zα/2和总体标准差 σ \sigma σ,就可以求得任一指定估计误差所需要的样本量,公式如下:
n = ( z α / 2 ) 2 π ( 1 − π ) E 2 n=\frac{ (z_{\alpha/2})^2\pi(1-\pi) }{ E^2 } n=E2(zα/2)2π(1−π)
其中E代表所希望达到的估计误差,大多数情况下,E<0.10 。
如果 π \pi π未知,可以用类似样本的比例来代替;也可以用试验调查的办法,选择一个初始样本,以该样本的比例作 π \pi π的估计值。 当 π \pi π无法知道时,通常取使 π ( 1 − π ) \pi(1-\pi) π(1−π)最大时的0.5。
3.4 如何预估实验周期时长?
📖设计实验周期时长需要考虑的因素
- 是否足够达到最小样本量;假设每天只能提供10个样本量,在最小样本量100时需要10天
- 指标是否具有周期性;假设指标周期性变化明显,则至少需要覆盖一个周期,比如周末与工作日数据差异巨大,则至少需要7天。
- 外部事件的影响;比如对于观看时长,春晚、大规模断电影响
3.5 如何在A/B测试中避免偏差?
☑避免偏差自检清单
| 步骤 | 要求 | 说明 |
| 定义个体 | 指标定义准确 | 不同的定义方式得到的数据质量不同 |
| 分组 | 独立性 | 样本之间的交叉影响会影响实验结果 |
| 随机性 | 不够随机会给实验带来偏差 | |
| 实验指标 | 定义准确、便于计算 | 不准确无法对业务决策作出指导 |
| 样本量 | 依据显著性水平和方差确定 | 注意计算的为单组样本量 |
| 实验周期 | 要达到最小样本量要求 | 样本量不够实验效果会不够可靠 |
| 考虑样本周期性 | 保证样本有代表性 | |
| 考虑实验周期是否收到外部事件干扰 | 保证样本尽量干净 | |
| 合理性检验 | 实验前指标是否相同 | |
| 分组是否随机 | ||
| 每日样本量增速是否有偏差 | 检查实验有效性 |
4. 如何对实验的合理性检验?
📖为什么需要合理性检验?
- 样本难以达到绝对的随机和独立,故需要检验样本将的相互影响是否会对实验结果有较大程度的影响;
- A/B测试样本分流算法可能BUG,导致样本偏差;因为对于平台来说,可能多个A/B同时进行,分流算法可能把同一个样本分到两个测试中,从而无法断定影响由哪部分导致。
- 其他不可控因素,比如实验组的IOS版本出现加载错误。
📖合理性检验的4个主要维度
- 每天进入实验的样本量是否符合预期
- 两组样本的分布是否一致
- 两组样本在实验前的指标值是否相同
- 指标是否有异常波动(删除极端数据)
📖如何对结果进行合理性检验?P值检验
- 两个总体参数的假设检验
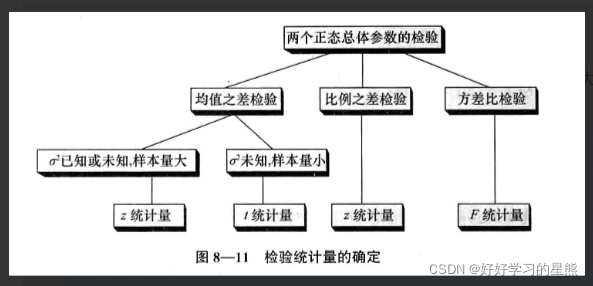
5. 如何分析实验结果?
假设实验前,实验组数据为A,对照组数据为B;实验后,实验组数据变化量为a,对照组数据为b。
📖前后比较(before-after)
- 适用场景:指标不随时间变化,故可以不需要对照组。
- 数据变化:实验前,A=B;试验后,实验组为A+a,对照组为B。
- 实验效果:增长a
📖双样本假设检验(Z/t检验)
- 适用场景:指标随时间有自然变化,即假设随着时间的变化,指标会增加c。
- 数据变化:实验前,A=B;试验后,实验组为A+a+c,对照组为B+c。
- 实验效果:增长a
📖双重差分(DID)
- 使用场景:实验开始前,实验组与对照组的指标就有差异,差异为d;同时假设时间变化指标为c。
- 数据变化:实验前,B+d=A;试验后,实验组为A+a+c;对照组为B+c
- 实验效果:增长a
📖线性回归模型(可使用其他模型)
-
使用场景:更加灵活,可以加入任意影响因素,同时设定影响因素是否存在。
-
公式:
Y ∼ a + b X 1 + . . . + n X n Y\sim{a+bX_1+...+nX_n} Y∼a+bX1+...+nXn
其中,a为实验前的指标,b…n为指标变化大小, X 1 . . . X n X_1...X_n X1...Xn各种影响是否存在,为0或者1。
6. 如何处理实验不严谨的情况?
📖合成对照组
- 适用场景:无法获得对照组
- 原理:使用自身历史数据预测未来数据,然后将实验数据与预测的未来数据做对比
- 方式:时间序列(ARIMA)
📖倾向评分匹配
- 适用场景:两组的混杂因素较多,导致无法判断是否由实验导致数据变化。
- 原理:从实验组和对照组中取相对匹配的子集,通过对比子集来得到结论。
- 方式:可以使用逻辑回归模型
-
建立逻辑回归模型:
Y ∼ X 1 + X 2 + . . . Y\sim{X_1+X_2+...} Y∼X1+X2+...
其中Y为二分标签,为1表示实验组,为0表示对照组; X i X_i Xi为各种影响因素。
-
计算每个影响因素的PS值;对于实验指标,则不计算
-
对比不同标签下,PS值相似的数据,即得到子集,对比相似子集的实验指标即可得到实验效果。
-

















 1076
1076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









