







获取ValueError: 数组不能包含 infs 或 NaNs
问题分析
data_Tai_LS[i, 3] = Lx(u_subdf, meanU, dt, model='autocovariance', method=2)
ValueError: array must not contain infs or NaNs
上面代码计算的结果,存入 数据中,因为计算结果可能为 infs或者 NaNs,所以抛出异常。
经检查发现,输入Lx()函数的参数 u_subdf 全为 nan, 导致计算结果出现 infs或者NaNs。
解决办法
将 infs 或 Nans 删除或跳过即可。
import numpy as np
a = np.array([[0, 0, 0, 0], [0, 0, 0, 0]])
if a.any() == 0:
print('all is 0')
其它解决方法
通过清除 NaN 和 infs 解决了
def clean(serie):
output = serie[(np.isnan(serie) == False) & (np.isinf(serie) == False)]
return output
df2
Out[6]:
x num a
0 0 0 0
1 0 0 0
2 0 0 0
3 0 0 0
4 0 0 0
5 0 0 0
df2.any()==0
Out[3]:
x True
num True
a True
dtype: bool
df3 = pd.DataFrame({'x': [1, 0, 0, 0, 0, 0],
'num': [1, 0, 0, 0, 0, 0],
'a': [1, 0, 0, 0, 0, 0]})
df3.any()==0
Out[5]:
x False
num False
其它解决方法2
由于np_subdf_2l[:, 0:3]全为0,导致Trans3D返回了全为空值的np1_subdf_2lnew,
meanU1, np1_subdf_2lnew, wd = Trans3D(np_subdf_2l[:, 0:3])
np1_subdf_2lnew 全为空值,导致 LcH() 函数报错。
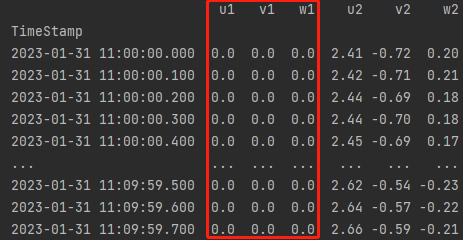
我们的判断语句,漏掉了上图的情况:
if nr_in_10[i] != self.Num_sub or np_subdf_ori.any() == 0:
continue
np_subdf_ori.any() == 0只识别 6列全为0,而上图是3列为0的情况。
修改:
if np_subdf_2l[:, 0:3].any()==0 or np_subdf_2l[:, 3:].any()==0:
continue
参考资料
[1] python - scipy.optimize.curvefit() - 数组不能包含 infs 或 NaNs 2022.10
[2] ValueError: array must not contain infs or NaNsValueError:数组不能包含 infs 或 NaNs 2016.6















 3675
3675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









