




目录
一. 论文简述
1. 第一作者:Zhuang Liu
2. 发表年份:2022
3. 发表期刊:CVPR
4. 关键词:ConvNet、Transformers、CNNs、数据集
5. 探索动机:在2020年,视觉Transformers,尤其是Swin Transformers等分层Transformers开始取代ConvNets,成为通用视觉主干的首选。人们普遍认为,视觉Transformers比ConvNets更准确、更高效、更易扩展。但是大量的工作其实是将之前运用在CNN网络结构上的思路改进到Transformers结构当中去。而且现在有更多的数据,更好的数据增强,以及更加合理的优化器等但所以vision Transformers之所以能够取得SOTA的效果,会不会是这些其他因素影响了网络。Transformers到底是厉害在哪了?
6. 工作目标:如果把这些用在transformer上的技巧用在CNN上之后,进而重新设计ConvNet,卷积能达到的效果的极限是在哪里?是否也能得到相似的结果呢?
7. 核心思想:ConvNeXt在ResNet50模型的基础上,仿照Swin Transformers的结构进行改进而得到的纯卷积模型。模型改进可以分为:整体结构改变、层结构改变和细节改变三大部分。
8. 实现方法:
Training Techniques:训练轮数从最初的90个epoch扩展到300个epoch,使用AdamW 优化器,Mixup、Cutmix、RandAugment、Random Erasing等数据增强技术,以及随机深度和标签平滑等正则化方案。仅改变训练方法,ResNet-50模型的性能从76.1%就提高到78.8%。
Macro Design
- changing stage compute ratio:Swin-Tr在网络各个阶段的模块比例为1:1:3:1,Swin-L的比例是1:1:9:1。ResNet50各个模块的比例:3:4:6:3,调整为3:3:9:3。这个小的操作让ResNet50的精度从78.8%提升到79.4%。后面的阶段都会使用这个比例。
- changing stem to “Patchify”:在ResNet的stem cell中,包含一个步长为2的7×7卷积层和一个最大池化,对输入图像进行4倍下采样。Transformers策略是使用patchify层。我们将ResNet的stem cell替换为更简单的4×4、步幅为4的卷积层(k=s=4),使得滑动窗口不再相交,每次只处理一个patch的信息。精度从79.4%变为79.5%。
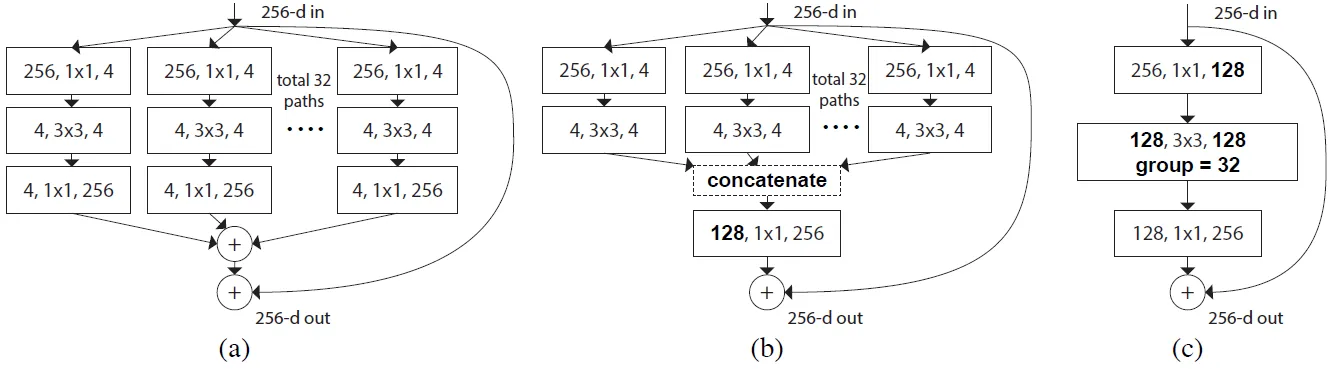
ResNeXt-ify
ResNeXt相比普通的ResNet而言在FLOPs以及 accuracy之间做到了更好的平衡,核心组成部分是分组卷积,其中卷积滤波器被分成不同的组。作者采用的是更激进的深度卷积(即分组数等于输入通道数),这个技术在之前主要是应用在MobileNet这种轻量级网络中,用于降低计算量。但在这里,作者发现深度卷积由于每个卷积核单独处理一个通道,这种形式跟自注意力机制很相似,都是在单个通道内做空间信息的混合加权。将bottleneck中的3x3卷积替换成深度卷积,再把网络宽度从64增加到96。准确率从79.5到80.5。
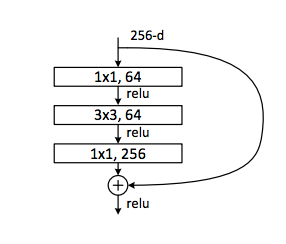
Inverted Bottleneck
Inverted Bottleneck是在Resnet网络当中首次提出,即(大维度-小维度-大维度)的形式。
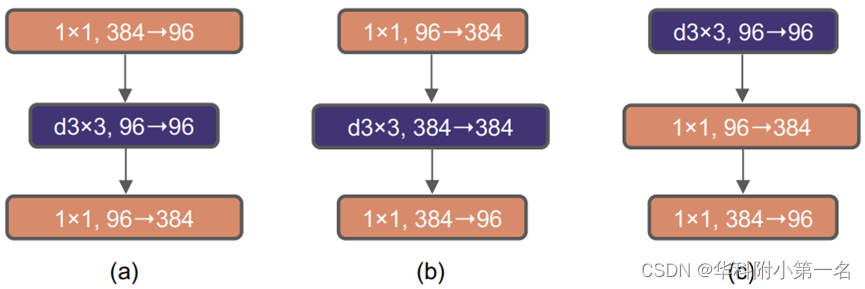
后来在MobileNetV2中提出了inverted bottleneck结构,采用(小维度-大维度-小维度)形式,认为这样能让信息在不同维度特征空间之间转换时避免压缩维度带来的信息损失,后来在Transformers的MLP中也使用了类似的结构,中间层全连接层维度数是两端的4倍。下图a是一个普通的ResNext的网络的结构,下图b是一个经过调整的Inverted Bottleneck结构,可以看到,虽然中间层增加了深度可分离卷积的计算量,但是由于减小了输出的大小,所以整个网络的计算量还是下降了。为了减少计算量,本文将反瓶颈中的中间卷积层移到了最前面,如下图c所示。网络的性能从80.5%提高到80.6%。
Large Kernel Sizes
VGGNet提出,堆叠多个小的卷积核,要比直接使用大的卷积核的效果要更好。Transformers的一个总所周知的厉害之处便是其长距离的相关性,使用窗口大小是7*7甚至12*12,这又是为什么呢?论文对大卷积核进行了进一步的探索,作者把深度卷积的位置进行了调整,放到了反瓶颈的开头。最终结果相近,说明在7x7在相同参数量下效果是一致的。将深度卷积的卷积核大小由3x3改成了7x7,准确率从80.6到80.6。
Micro Design
- 用GELU代替ReLU。主要是为了对齐比较,并没有带来精度提升。
- 更少的激活函数。由于Transformers中只使用了一个激活层,在block中的两个1x1卷积之间使用一层激活层,其他地方不使用,准确率从80.6到81.3。
- 更少的归一化层。由于Transformers中BN层很少,本文也只保留了1x1卷积之前的一层BN,准确率从81.3到81.4。
- 用LN代替了BN。由于Transformers中使用了LN,且一些研究发现BN会对网络性能带来一些负面影响,本文将所有的BN替换为LN,准确率从81.4到81.5。
- 单独的下采样层。标准ResNet的下采样层通常是stride=2的3x3卷积,对于有残差结构的block则在直连边连接中使用stride=2的1x1卷积。而Swin-T中的下采样层是单独的,因此本文用类似的策略,我们使用步长为2的2×2卷积层进行空间下采样。又因为这样会使训练不稳定,因此在每个下采样层前面增加了LN来稳定训练,准确率从81.5到82.0。
9. 实验结果:ConvNeXt是一个借鉴Transformers网络的CNN模型,从作者的实验看出,每一点精度的提升都是经过大量的实验。虽然原生模型是一个分类模型,但是其可以作为backbone被应用到任何其它模型中。通过一系列实验比对,在相同的FLOPs下,ConvNeXt相比Swin Transformers拥有更快的推理速度以及更高的精度,在ImageNet 22K上ConvNeXt-XL达到了87.8%的准确率。
10.论文下载:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4967
4967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











