






0. 这篇文章干了啥?
网格部件分割在多个领域有广泛应用,从图形学中的纹理贴图和四边形网格划分到机器人学的物体理解。流行的网格部件分割方法要么是基于学习的,要么是采用更传统的形状分析方法。例如,一种稳健的网格分割形状分析方法是形状直径函数,它计算每个面的标量值以表示其局部厚度,然后将这些值聚类以获得分割区域。然而,基于学习的方法受到缺乏多样分割数据的限制,而传统方法在处理超过有限种类网格时效果不佳。最近,大型二维基础模型如Segment Anything(SAM)和SAM2在图像分割方面取得了最先进的结果。这重新激发了人们从聚合这些二维模型在网格多视图渲染中产生的掩码来接近三维分割的兴趣。然而,之前和当前用于网格分割的二维到三维提升方法仅限于语义组件分割,而不是部件分割,因为它们需要输入要分割部件的文本描述,这使得它们无法分割重复的对象(如手臂、手)。
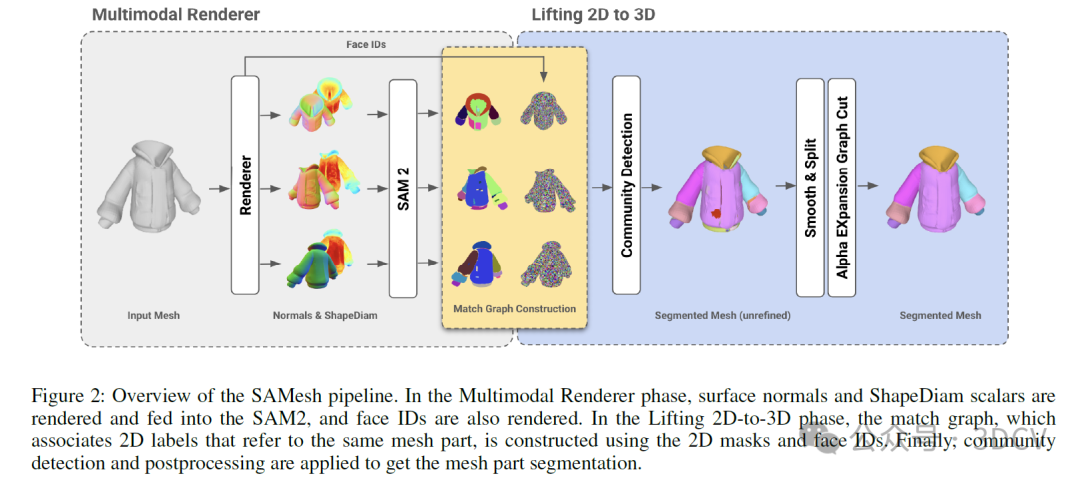
SAMesh是一种零样本网格部件分割方法,仅需要输入网格。SAMesh由两个阶段组成:多模态渲染和二维到三维提升。在第一阶段,从不同角度的渲染图被单独输入到SAM2中以生成多视图掩码。此外,我们还从每个相应的视角渲染网格三角形面的ID。在提升阶段,我们使用多视图掩码和面ID来构建匹配图,该图用于将二维区域标签与其对应的三维部件相关联。具体来说,我们在该图上运行社区检测以获得粗略的网格部件分割,然后进一步后处理以获得最终分割。我们在无纹理设置下操作,并发现无纹理渲染不会使SAM2产生足够详细的二维掩码来区分网格部件。作为替代方案,我们发现SAM2可以在其他模态的输入上运行。具体来说,我们展示了通过将几何形状的法线渲染和ShapeDiam标量渲染都输入到SAM2中,我们可以获得比依赖单一模态更高质量的详细二维掩码和网格部件分割。
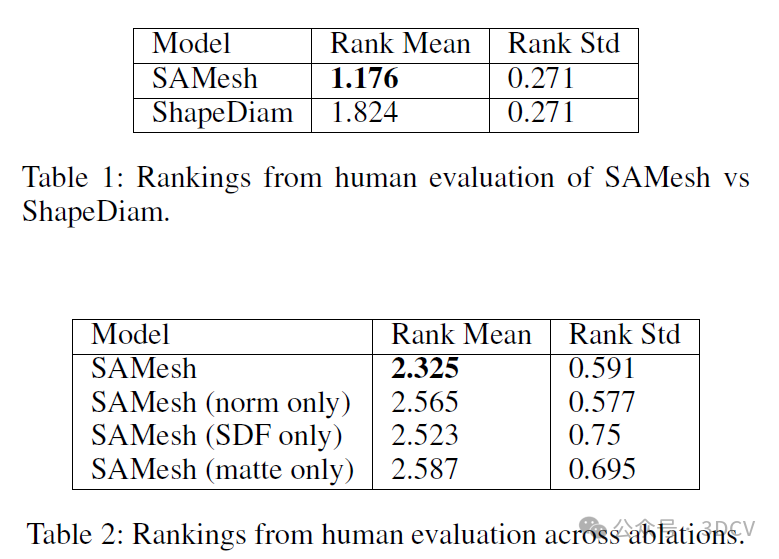
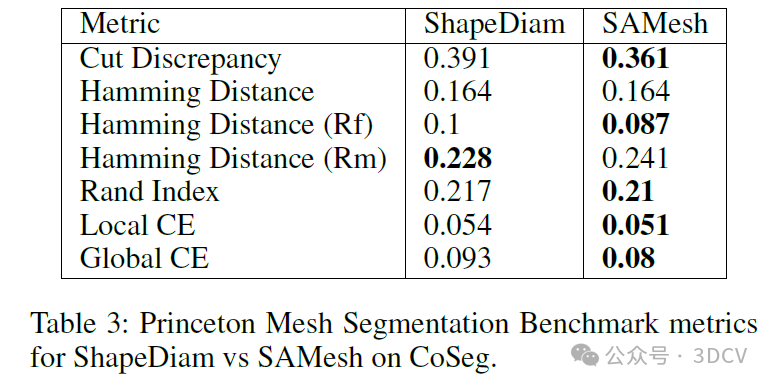
我们通过将我们的方法与ShapeDiam进行比较来评估我们的方法,后者在现有的网格部件分割基准测试中表现良好。我们展示了我们的方法在这些基准测试上的性能与ShapeDiam相当或超过其性能。由于这些基准测试中对象的多样性有限,我们整理并发布了一个通过生成模型创建的多样对象模型数据集。我们通过人工偏好评估表明,SAMesh产生的分割质量大大超过了ShapeDiam产生的分割质量。
下面一起来阅读一下这项工作~
1. 论文信息
标题:Segment Any Mesh: Zero-shot Mesh Part Segmentation via Lifting Segment Anything 2 to 3D
作者:George Tang, William Zhao, Logan Ford, David Benhaim, Paul Zhang
机构:MIT CSAIL、Backflip AI
原文链接:https://arxiv.org/abs/2408.13679
代码链接:https://github.com/gtangg12/samesh
2. 摘要
我们提出了Segment Any Mesh(SAMesh),这是一种新颖的零样本网格部件分割方法,该方法克服了基于形状分析、基于学习以及当前零样本方法的局限性。SAMesh的工作流程分为两个阶段:多模态渲染和2D到3D的提升。在第一阶段,网格的多视图渲染图被单独通过Segment Anything 2(SAM2)处理,以生成二维掩码。然后,通过跨多视图渲染图关联指向相同网格部件的掩码,将这些掩码提升为网格部件分割。我们发现,将SAM2应用于法线和形状直径标量的多模态特征渲染图,比仅使用网格的无纹理渲染图能取得更好的结果。通过将我们的方法建立在SAM2之上,我们能够无缝地继承未来对二维分割所做的任何改进。我们将我们的方法与一种稳健且经过充分评估的形状分析方法——形状直径函数(Shape Diameter Function,简称ShapeDiam)进行了比较,并展示了我们的方法在性能上与其相当或超过其性能。由于当前的基准测试包含的对象多样性有限,我们还整理并发布了一个生成的网格数据集,并使用它通过人工评估来展示我们的方法在泛化能力上对ShapeDiam的改进。我们的代码和数据集可在https://github.com/gtangg12/samesh上获取。
3. 效果展示

4. 主要贡献
我们的贡献包括:
• 我们提出了SAMesh,这是一种新颖的零样本方法,它将通过在多视图渲染上应用SAM2产生的掩码提升到三维网格部件分割。
• 我们展示了通过融合来自多模态渲染的掩码(特别是渲染的表面法线和ShapeDiam标量)可以提高性能。推荐课程:国内首个面向工业级实战的点云处理课程
• 我们将我们的方法与稳健且经过充分评估的形状直径函数进行了基准测试,并在现有数据集上展示了我们的方法的有效性。
• 由于这些现有基准测试没有表现出太多的对象多样性或复杂性,我们还从自定义的三维生成模型中整理了一个数据集,并使用它来证明我们方法的泛化能力。
5. 基本原理是啥?
SAMesh流程概述。在多模态渲染阶段,表面法线和ShapeDiam标量被渲染并输入到SAM2中,同时渲染出面ID。在2D到3D提升阶段,使用二维掩码和面ID构建匹配图,该图将指向相同网格部件的二维标签关联起来。最后,应用社区检测和后处理以获取网格部件分割。
6. 实验结果
7. 总结 & 未来工作
在本文中,我们提出了SAMesh,这是一种新颖的零样本网格部件分割方法,它利用多模态渲染和2D到3D提升技术。通过设计,SAMesh无缝地从二维分割的任何改进中受益。这一优势同时也成为了SAMesh效果的瓶颈,因为其效果依赖于底层SAM模型的性能。我们还注意到相对缺乏客观的3D分割度量标准。虽然这样的任务本质上是主观的,但我们认为更实用的界面倾向于更多的分割部件而不是更少的。
对于未来的工作,可以开发一个界面,允许人类用户使用二维视图来细化掩码,使他们能够执行诸如提示、平滑面和其他基于SAM的修改等任务。这种方法可以增强实际应用,如对象理解、纹理化和拓扑结构,在方法工作良好的情况下。对于更精确的任务,可以将人工干预集成到过程中以确保准确性。此外,我们可以利用这种人在环中的过程来整理数据集,并将其提炼为MeshCNN模型,类似于SAM的数据引擎。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。
8、3D视觉交流群,成立啦!
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、最前沿、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
最前沿:具身智能、大模型、Mamba、扩散模型等
除了这些,还有求职、硬件选型、视觉产品落地、产品、行业新闻等交流群
添加小助理: dddvision,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









