







无监督学习中存在一个问题,就是我们并不知道问题的确切答案。由于没有数据集样本类标的确切数据,我们无法在无监督学习中使用评估监督学习模型性能的相关技术。
因此,为了对聚类效果进行定量分析,我们需要使用模型内部的固有度量来比较不同K-means聚类结果的性能。在完成K-means模型的拟合后,簇内误差平方和可以通过inertia属性来访问。
使用肘方法确定簇的最佳数量
先生成聚类样本数据集
from IPython.display import Image
from sklearn.datasets import make_blobs
X,y=make_blobs(n_samples=150,
n_features=2,
centers=3,
cluster_std=0.5,
shuffle=True,
random_state=0)
import matplotlib.pyplot as plt
plt.scatter(X[:,0],X[:,1],c='r',marker='o',s=50)
plt.grid()
plt.show()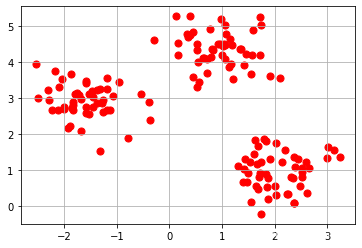
显然,使用聚类算法K-means的结果一定是三类!!!

from sklearn.cluster import KMeans
distortions=[]
for i in range(1,11):
km=KMeans(n_clusters=i,
init='k-means++',
n_init=10,
max_iter=300,
random_state=0)
km.fit(X)
distortions.append(km.inertia_)
plt.plot(range(1,11),distortions,marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Distortion')
plt.show()上面这串代码的逻辑就是设置聚类个数的值从1到10分别计算聚类结果后的簇内误差平方和,并折线图的方式展示结果:
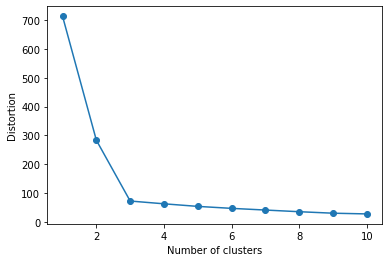
显示,如图所示,当k=3时图案呈现了肘型,这表明对于次数据集来说,k=3的确是一个很好的选择。

通过轮廓图定量分析聚类质量
另一种评估聚类质量的定量分析方法是轮廓分析(silhouette analysis)。此方法也可用于K-means之外的其他聚类方法。轮廓分析可以使用一个图形工具来度量簇中样本聚集的密集程度。轮廓系数的值介于-1到1之间。
绘制k=3时K-means算法的轮廓系数图:
km=KMeans(n_clusters=3,
init='k-means++',
n_init=10,
max_iter=300,
tol=1e-04,
random_state=0)
y_km=km.fit_predict(X)import numpy as np
from matplotlib import cm
from sklearn.metrics import silhouette_samples
cluster_labels=np.unique(y_km)
n_clusters=cluster_labels.shape[0]
silhouette_vals=silhouette_samples(X,y_km,metric='euclidean')
y_ax_lower,y_ax_upper=0,0
yticks=[]
for i,c in enumerate(cluster_labels):
c_silhouette_vals=silhouette_vals[y_km==c]
c_silhouette_vals.sort()
y_ax_upper+=len(c_silhouette_vals)
color=cm.jet(i/n_clusters)
plt.barh(range(y_ax_lower,y_ax_upper),
c_silhouette_vals,
height=1.0,
edgecolor='none',
color=color)
yticks.append((y_ax_lower+y_ax_upper)/2)
y_ax_lower+=len(c_silhouette_vals)
silhouette_avg=np.mean(silhouette_vals)
plt.axvline(silhouette_avg,color='red',linestyle='--')
plt.yticks(yticks,cluster_labels+1)
plt.ylabel('Cluster')
plt.xlabel('Silhouette coefficient')
plt.show()结果展示
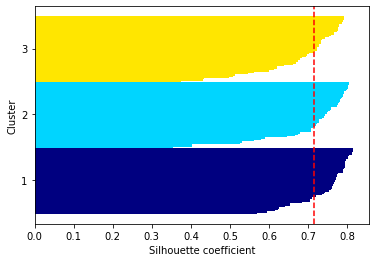
通过观察轮廓图,我们可以快速知晓不同簇的大小,而且能够判断簇中是否包含异常点.为了评判聚类效果的优劣,我们在图中增加了轮廓系数的平均值(虚线)。
上面的作图原理不必深究,会套用就行!



















 3500
3500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











