






用Bedrock和SingleStore构建多智能体RAG
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, SingleStore, Multi-Agent Rag, Singlestore Database, Vector Capabilities, Intelligent Applications, Hybrid Search]
导读
在这个互动式闪电演讲中,学习如何构建一个可扩展的数据环境,通过AI为您的运营注入超强动力。探索SingleStore和Amazon Bedrock的强大功能,了解如何利用这些平台来增强您的数据管理能力,并在大规模环境下做出更明智的决策。学习可行的策略来改变您处理数据的方法,帮助您的组织在当今由AI驱动的环境中蓬勃发展。本演讲由亚马逊云科技合作伙伴SingleStore为您呈现。
演讲精华
以下是小编为您整理的本次演讲的精华。
在2024年亚马逊云科技 re:Invent活动上,SingleStore的战略解决方案工程师Justin Stranavco进行了一场全面的演讲,介绍了如何通过集成Bedrock和SingleStore来构建多智能体检索增强生成(RAG)系统。他的演讲旨在展示将这两种技术相结合,创建高效和可扩展的智能应用程序的强大功能。
Justin首先评估了观众对Bedrock的熟悉程度,Bedrock是一个用于开发和部署大型语言模型(LLM)的平台。只有几位与会者举手,表明他们对Bedrock的了解有限。然后,他介绍了SingleStore,这是一种多模型数据库解决方案,可以无缝集成向量、搜索、分析和事务数据库到一个统一的引擎中。Justin强调了SingleStore的向量功能,该功能自2017年以来一直存在,并强调它能够通过从各种来源(包括S3、Kafka、Hadoop和Python Spark)摄取数据来支持智能应用程序。
正如Justin所解释的,SingleStore的一个关键优势在于它能够处理多种数据类型,使其成为一个“随意带来,随意处理”的数据库,非常适合AI和机器学习应用程序。他分享了SingleStore在向量和AI领域的渊源,引用了它在2017年为两家公司开发的案例:高盛(一家著名银行)和Thorn(一家致力于打击人口贩运的组织,与Salesforce合作)。这种合作体现了SingleStore致力于开发前沿向量功能的决心。
通过将向量与关系和事务数据相协调,SingleStore降低了延迟、成本和幻觉,从而提高了查询响应时间。Justin展示了一系列信赖SingleStore满足向量、关系和分析需求的客户,证明了该解决方案在各个行业的广泛应用。这些客户包括Comcast、Uber、Cisco和Coupang等。
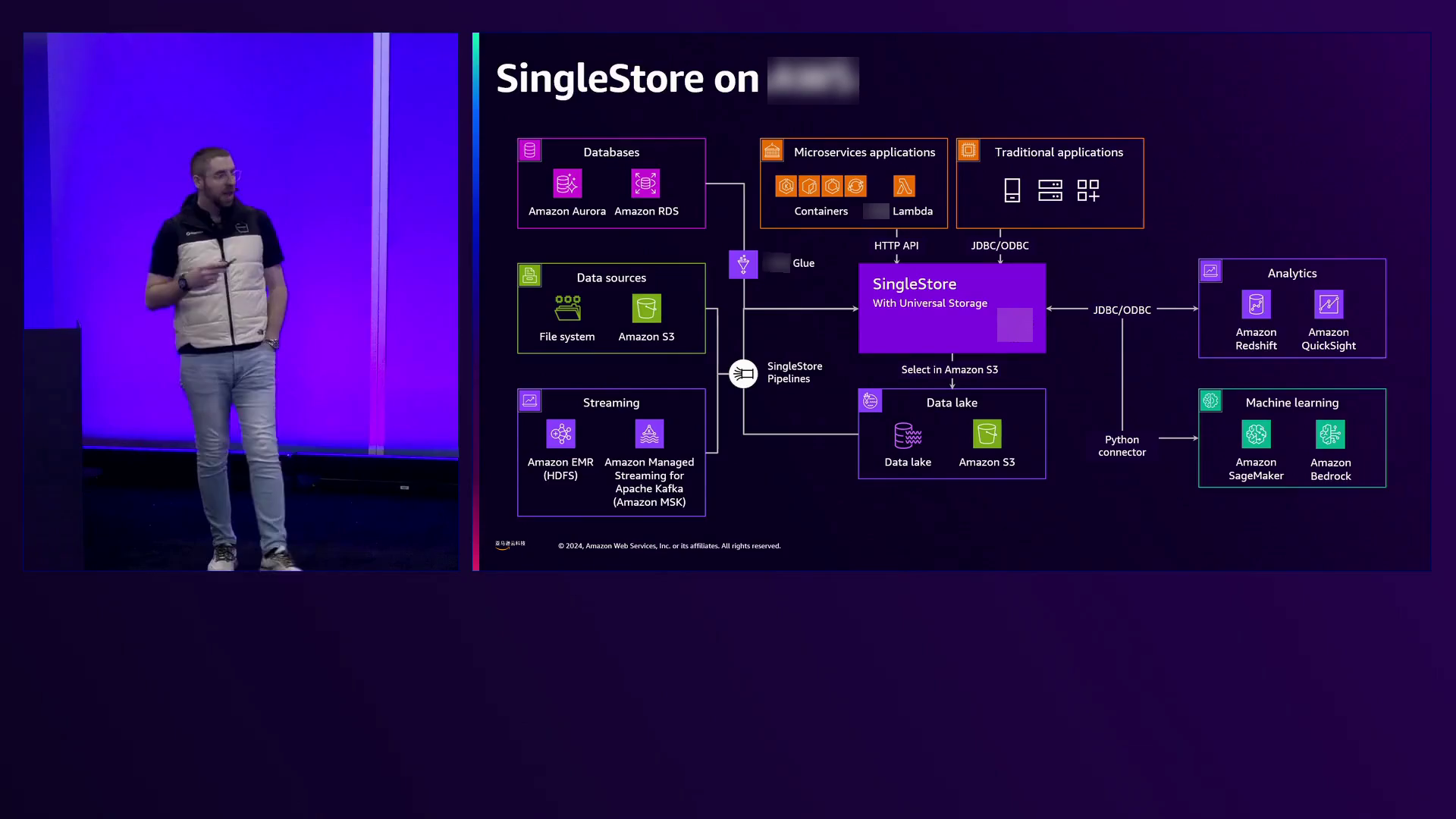
在介绍SingleStore与亚马逊云科技的集成时,Justin强调了它与各种亚马逊云科技产品的互操作性,从Bedrock到数据摄取源(如S3、Kafka和Hadoop)。他强调了数据库互操作性的重要性,将SingleStore定位为一种能够与其他数据库无缝协作的解决方案,确保长期的可行性和可扩展性。
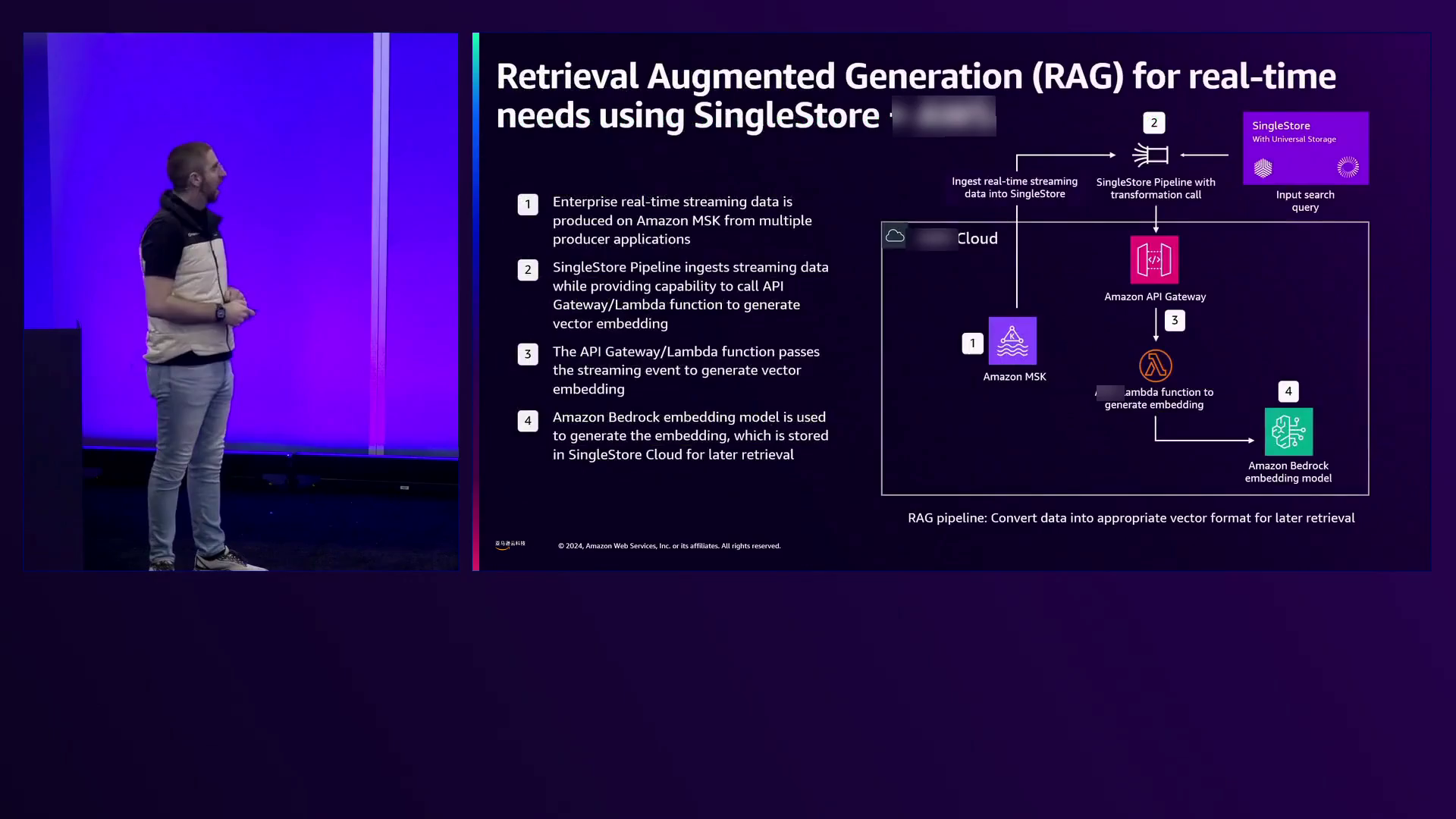
转向演讲的AI部分,Justin讨论了Bedrock选择不同模型的能力,如Anthropic的Haiku用于快速响应、Claude用于高效和稳健的响应,以及Opus用于复杂、深思熟虑的响应。他演示了如何使用仅需15行SQL代码的管道,让SingleStore从亚马逊云科技的托管Kafka服务(MSK)中摄取实时数据。这种简化的方法展示了SingleStore的易用性和灵活性。此外,Justin强调,无论是向量、标准数据点还是事件,SingleStore都可以通过连续实时摄取在不到一分钟的时间内摄取1000万个数据点。
摄取的数据(包括向量)随后存储在SingleStore中,通过简单的API调用或两行Python代码,可以与Bedrock无缝集成。Justin展示了这种方法的灵活性,允许整合不同的模型,如Bedrock嵌入模型、生成AI模型,甚至Amazon Lambda函数用于额外的计算。这种模块化使开发人员能够根据特定需求定制系统,从而促进创新和定制。
与传统的RAG系统相比,Justin强调了从多个事务、分析和向量数据库中拼凑数据的低效性,这会引入延迟、复杂性和成本。相比之下,SingleStore的协调解决方案通过在同一表中存储向量和非向量化文本,降低了复杂性,并支持随着模型变化而进行模式演化。这一特性确保了系统的适应性和面向未来,能够适应AI和机器学习模型的进步。
Justin接着深入探讨了三个关键的开发领域:词汇搜索(关键词、邻近、模糊匹配)、向量搜索和混合搜索。混合搜索是SingleStore的一个强大功能,它结合了词汇和语义搜索,可以使用词汇搜索结果作为语义搜索的上下文,或者在SQL查询中加权这两种搜索类型。这种方法允许开发人员利用两种搜索方法的优势,从而实现更准确、更相关的结果。
为了演示这种方法的威力,Justin分享了他之前与Anthropic合作的一个演示。该演示涉及将亚马逊Prime Video的评论数据摄取到SingleStore中,生成向量嵌入并将其存储在单个表中。用户可以输入一个标题,系统会使用词汇搜索检索相关评论,将它们作为上下文传递给LLM,并生成总结性的情感分析。例如,当Justin输入“Breaking Bad”时,系统检索到17条评论,并提供了一个三句话的总结,强调了该剧广受好评和出色的接受程度。这个真实的用例展示了SingleStore-Bedrock集成的实际应用,实现了对大型数据集的高效和准确分析。
Justin强调了这个过程的简便和快速,从数据摄取到构建多智能体系统仅用了不到两个小时。他鼓励观众选择适合自己并且可扩展的系统,因为在AI领域,复杂性往往会阻碍可扩展性。通过利用SingleStore和Bedrock的协调能力,开发人员可以简化工作流程、降低复杂性,并加速智能应用程序的开发和部署。
在整个演讲过程中,Justin提供了代码片段和技术细节,说明了实施过程。他分享了连接SingleStore、生成向量嵌入以及使用SQL查询查询数据库的见解。此外,他还提出公开分享演示代码和数据,以促进AI和数据库社区的协作和知识共享。
总之,Justin Stranavco在2024年亚马逊云科技 re:Invent活动上的演讲展示了将SingleStore的多模型数据库能力与Bedrock的LLM模型相结合,构建高效和可扩展的多智能体RAG系统的强大功能。通过协调数据源、降低复杂性并利用混合搜索技术,这种方法有望加速各行业和用例中智能应用程序的开发和部署,正如SingleStore的多元化客户群所证明的那样,包括Comcast、Uber、Cisco和Coupang。
下面是一些演讲现场的精彩瞬间:
SingleStore体现了数据库的未来发展方向,在不断演进的云生态系统中,与其他数据库的互操作性和集成至关重要,以确保长期成功。
仅需15行SQL代码,亚马逊云科技上的托管Kafka服务就能在不到一分钟的时间内摄取1000万个数据点,包括向量和事件,实现实时数据摄取。
引入了一种灵活且易于部署的端到端数据库解决方案,可无缝集成来自多个来源的数据,利用生成式人工智能模型和微服务来增强功能。

亚马逊云科技人工智能服务能够无缝集成来自各种来源的数据,降低了构建人工智能系统的延迟、复杂性和成本。

突出了在同一个数据库表中存储和管理向量以及非结构化文本数据的能力,实现了模式演进,并跟踪了不同模型随时间的向量变化。
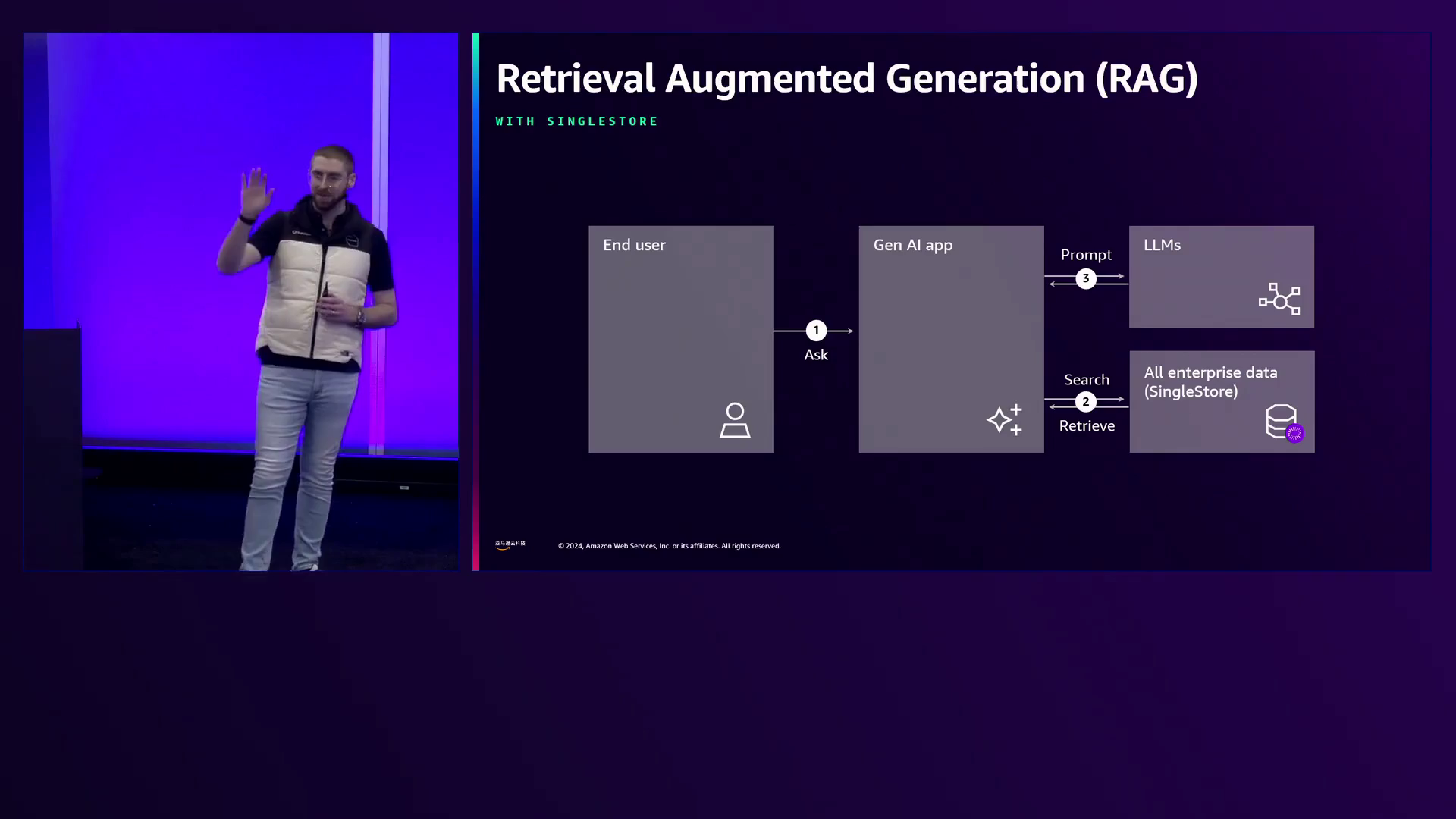
演讲者强调选择一个可扩展、可管理且适合长期使用的人工智能系统的重要性,而不应仅仅关注复杂性。
总结
在人工智能和数据快速发展的世界中,SingleStore作为一种强大的多模型数据库解决方案应运而生,它将向量、搜索、分析和事务数据库融合到一个引擎中。本次演讲深入探讨了SingleStore与Bedrock平台的集成,Bedrock允许用户选择和利用多种AI模型,从而实现高效的多智能体RAG(检索增强生成)系统的创建。
演讲者Justin Stranavco演示了SingleStore的实时数据摄入能力如何与Bedrock的模型选择和集成相结合,从而简化构建智能应用程序的过程。通过协调来自各种来源的数据,包括向量、关系数据和事务数据,SingleStore降低了延迟、成本和幻觉,最终加快了答复时间。
Stranavco强调了这种方法的灵活性,展示了用户如何权衡词汇和语义搜索,创建利用两种技术优势的混合搜索功能。他还强调了模式演化的重要性,允许跨不同模型跟踪向量,同时保持相同的底层文本数据。
演讲最后呼吁采取行动:选择适合您的系统,并能够随着您的需求而扩展。单纯的复杂性并不能很好地扩展,推进人工智能发展的关键在于选择能够适应和成长的解决方案,与您不断发展的需求相适应,从而实现长期成功。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。

















 1061
1061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









