







史上最全的机器学习深度学习面经总结
提示:19年之后的面经,扩大了范围包括了cv,推荐,语音等面经中的知识点,
同时增加了那三本面经书的内容一些github上一些比较火的项目,大部分问题是重复的,去重之后其实大概也就百道题的样子.
文章目录
- 史上最全的机器学习深度学习面经总结
-
- 无监督相关(聚类,异常检测等)
-
- 问:kmeans的原理是什么?kmeans是一种基于划分的聚类,中心思想很简单,类内距离尽量小,类间距离尽量大,算法过程为:
-
- 相似度相关的
- 问:为什么在一些场景中要使用余弦相似度而不是欧氏距离?
- 问:余弦距离是否是一个严格定义的距离? (一个度量标准要满足什么要求才能算是距离)
- 问:K-means 中我想聚成100类 结果发现只能聚成98类,为什么?
- 问:kmeans,GMM,EM之间有什么关系?
- 问:高斯混合模型的核心思想是什么?(GMM和多元高斯有什么区别?,多元高斯函数的期望是什么)
- 问:GMM是如何迭代计算的?为什么kmeans,GMM,EM满足上面描述的方式?(EM算法数学原理)
- 问:为什么选择孤立森林?介绍一下iforest?
- 追问:为什么高度为log2(bagging的样本数量)?为什么每次随机仅选择一小部分的样本(默认是min(bagging的样本数量,256))?
- 追问:iforest的score function,为什么这么设计?
- 追问:为什么这里要引入分子和分母部分的修正项?
- 问:KNN算法是否存在损失函数?
- 不均衡学习:
-
- 模型的loss function,metrics和optimizers
- 问:如何评价聚类结果的好坏(知道哪些聚类的评估指标)?轮廓系数有没有用过
- 问:准确率的局限性是什么?
- 问:ROC曲线如何绘制,ROC和PRC的异同点;准确率(accuracy)、精确率(precision)、召回率(recall),各自的定义,各自的缺陷;PR曲线的绘制;使用PR曲线判断模型好坏;ROC曲线的横坐标、纵坐标意义;
- 问:ROC曲线和PR曲线的区别,适用场景,各自优缺点;
- 问:AUC的意义,AUC的计算公式?
- 问:给你M个正样本,N个负样本,以及他们的预测值P,求AUC
- 问:IV值,woe值是什么?
- 问:roc曲线中,高于和低于对角线表示意义
- 问:多分类 auc 怎么算?
- 问:F1,F2.。。.Fn值是什么,Fbeta怎么计算?
- 问:ks曲线和psi了解吗?
- loss function
-
- 最优化方法:
-
- 自动化机器学习/模型应用和特征工程部分
- 总结
文章目录
- 史上最全的机器学习深度学习面经总结
- 无监督相关(聚类,异常检测等)
- 问:kmeans的原理是什么?kmeans是一种基于划分的聚类,中心思想很简单,类内距离尽量小,类间距离尽量大,算法过程为:
- 相似度相关的
- 问:为什么在一些场景中要使用余弦相似度而不是欧氏距离?
- 问:余弦距离是否是一个严格定义的距离? (一个度量标准要满足什么要求才能算是距离)
- 问:K-means 中我想聚成100类 结果发现只能聚成98类,为什么?
- 问:kmeans,GMM,EM之间有什么关系?
- 问:高斯混合模型的核心思想是什么?(GMM和多元高斯有什么区别?,多元高斯函数的期望是什么)
- 问:GMM是如何迭代计算的?为什么kmeans,GMM,EM满足上面描述的方式?(EM算法数学原理)
- 问:为什么选择孤立森林?介绍一下iforest?
- 追问:为什么高度为log2(bagging的样本数量)?为什么每次随机仅选择一小部分的样本(默认是min(bagging的样本数量,256))?
- 追问:iforest的score function,为什么这么设计?
- 追问:为什么这里要引入分子和分母部分的修正项?
- 问:KNN算法是否存在损失函数?
- 不均衡学习:
- 模型的loss function,metrics和optimizers
- 问:如何评价聚类结果的好坏(知道哪些聚类的评估指标)?轮廓系数有没有用过
- 问:准确率的局限性是什么?
- 问:ROC曲线如何绘制,ROC和PRC的异同点;准确率(accuracy)、精确率(precision)、召回率(recall),各自的定义,各自的缺陷;PR曲线的绘制;使用PR曲线判断模型好坏;ROC曲线的横坐标、纵坐标意义;
- 问:ROC曲线和PR曲线的区别,适用场景,各自优缺点;
- 问:AUC的意义,AUC的计算公式?
- 问:给你M个正样本,N个负样本,以及他们的预测值P,求AUC
- 问:IV值,woe值是什么?
- 问:roc曲线中,高于和低于对角线表示意义
- 问:多分类 auc 怎么算?
- 问:F1,F2.。。.Fn值是什么,Fbeta怎么计算?
- 问:ks曲线和psi了解吗?
- loss function
- 最优化方法:
- 自动化机器学习/模型应用和特征工程部分
- 总结
无监督相关(聚类,异常检测等)
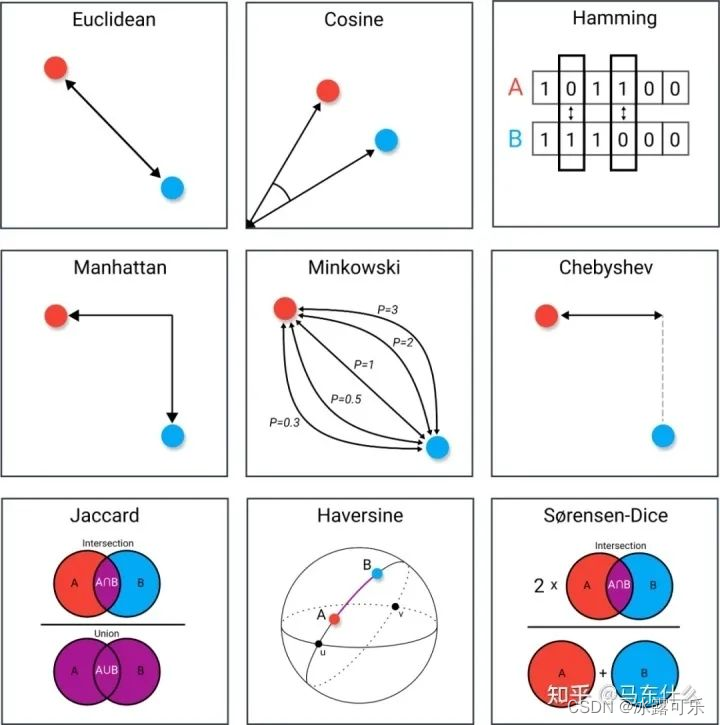
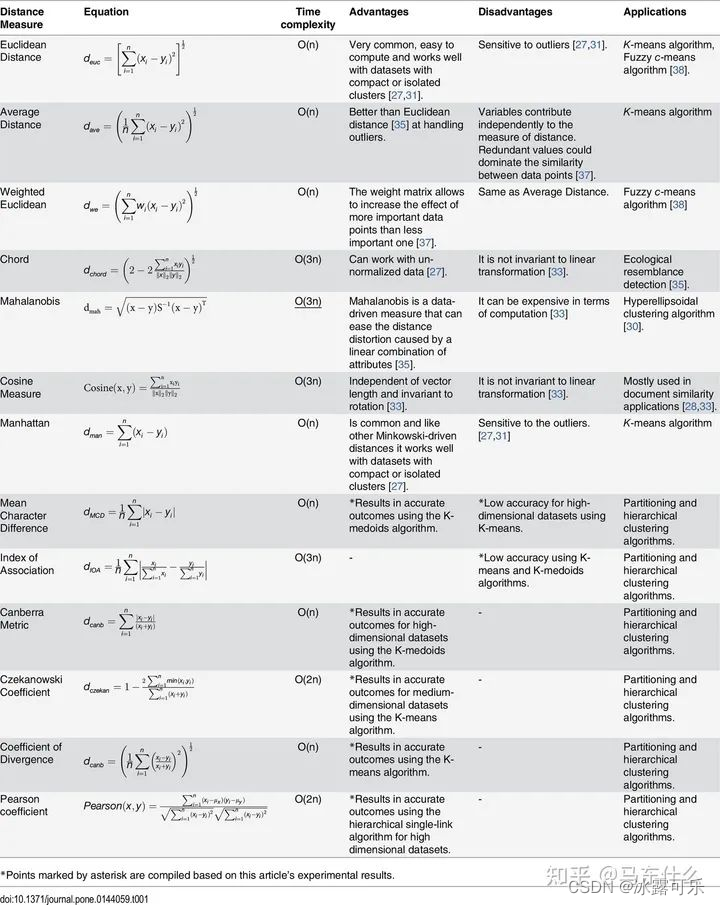
问:熟悉哪些距离度量的方法?写一下距离计算公式?
连续数据的距离计算:闵可夫斯基距离家族:

当p=1时,就是曼哈顿距离;
当p=2时,就是欧氏距离;
当p→∞时,就是切比雪夫距离。
余弦距离:
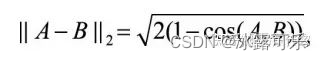
离散数据的距离计算:
杰卡尔德距离:A,B集合的交集/A,B集合的并集,交并比(IoU)
汉明距离:表示两个等长字符串在对应位置上不同字符的数目
关于距离计算,遇到了我在单独研究,因为也是非常大的一块内容。
上述的距离计算公式都是基于样本-样本 之间的简单距离计算,当引入了核方法进行映射之后还会有一些相应的更复杂的距离计算方法,
除此之外,迁移学习中的样本群体,即不同数据集之间的分布的距离的计算也是一大块儿内容,面试的时候应该不会问的太复杂,这里就暂时不深入展开了。
笔试还可能问到相对熵:图像的相对熵举例,相似度计算的。
问:你了解哪些常见的聚类算法?对聚类了解多少?
简单回答,基于划分,基于密度,基于网格,层次聚类,除此之外聚类和其它领域也有很多的结合形成的交叉领域比如半监督聚类,深度聚类,集成聚类等等;
问:kmeans的原理是什么?kmeans是一种基于划分的聚类,中心思想很简单,类内距离尽量小,类间距离尽量大,算法过程为:
1.初始化k个质心,作为初始的k个簇的中心点,k为人工设定的超参数;
2.所有样本点n分别计算和k个质心的距离,这里的距离也是人工定义的可以是不同的距离计算方法,每个样本点和k个质心中最近的质心划分为1类簇;
3.重新计算质心,方法是针对簇进行聚合计算,kmeans中使用简单平均的方法进行聚合计算,也可以使用中位数等方式进行计算;
4.重复上述过程直到达到预定的迭代次数或质心不再发生明显变化
kmeans的损失函数是什么?
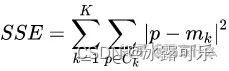
其中,K是聚类数量,p是样本,mk是第k个聚类的中心点。
每一个簇中,每个样本与质心的举例越小越好
SSE越小,说明样本聚合程度越高。
kmeans的初始点怎么选择?不同的初始点选择策略有哪些缺陷?怎么解决?
1.**随机初始化:**随机选择k个样本点作为初始质心,缺陷在于如果选择到的质心距离很接近落在同一个簇内,则迭代的结果可能会比较差,因为最终迭代出来的质心点会落在簇间,
最理想的状态是k个质心恰好对应k个簇,由于随机初始化的随机性,可以考虑多次进行随机初始化,选择聚合结果最优的一次(这里涉及到聚类的评估方法);
2.随机分取初始化:即将所有样本点随机赋予1个簇的编号,则所有样本点最后会有k个编号,然后进行组平均,即对于同一个簇的样本进行平均得到初始化质心。相对于随机初始化,初始的质心会更鲁棒一些,但是仍旧存在随机初始化的缺陷,仅仅是缓解;

其它聚类算法初始化策略:
使用其它聚类算法计算得到k个质心点作为kmeans的初始质心,我挺懵的,这样好像有亿点麻烦。。。
(0)初始点随机分布
(1)数据归一化和离群点的处理:
上面也说了k-means是根据欧式距离来度量数据的划分,**均值和方差大的数据会对结果有致命的影响。**同时,少量的噪声也会对均值产生较大的影响,导致中心偏移。所以在聚类前一定要对数据做处理。
(2)选择合适的k值: k-means++方法,在一开始确定簇时,让所有簇中心坐标两两距离最远。
————————————————
版权声明:本文为CSDN博主「冰露可乐」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_46838716/article/details/124485546
问:kmeans聚的是特征还是样本?特征的距离如何计算?
一般情况下是对样本聚类,
如果对特征聚类则处理方式也简单,对原始的输入进行.T ,即转置即可。
其目的其实和做相关系数类似,如果两个特征高度相关,例如收入和资产水平,则两个特征的距离相对较小,但是一般不可行,因为转置之后,维度往往是非常高的,例如有100万个样本则有100万的维度,计算上不现实,高维数据的距离度量也是无效的,不如直接计算相关系数;
为什么在高维空间中,欧式距离的度量逐渐失效?
《When Is “Nearest Neighbor” Meaningful?》
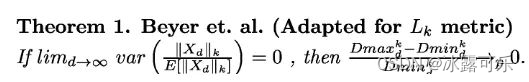
维度d趋于无穷大时,
高维空间中任意两个样本点的最大距离和最小距离趋于相等,距离度量失效;
怎么确定聚类数量K(聚类如果不清楚有多少类,有什么方法?)
手肘法: 当误差手肘处拐变,然后不咋巨变,那拐点就是k
比如下图k=3,手肘处的k
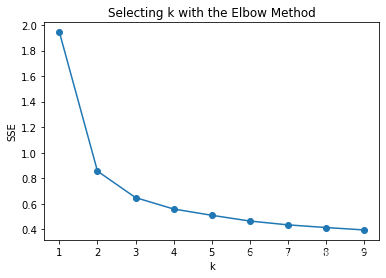
和评估分类或回归的方式一样,选择某个metric或某些metrics下最好的k,例如sse(其实就是kmeans的损失函数了),轮廓系数,兰德指数,互信息等;
如果聚类本身是为了有监督任务服务的(例如聚类产生features用于下游任务),则可以直接根据下游任务的metrics进行评估更好;
k-means如何调优
1.初始化策略调参;
2.k的大小调参,手工方法,手肘法为代表;
3.数据归一化和异常样本的处理;
介绍一下手肘法(gap statistic的计算很麻烦,这里就不写了)?
手肘法其实没什么特别的,
纵轴是聚类效果的评估指标,根据具体的问题而定,
如果聚类是作为单独的任务存在则使用sse或轮廓系数这类无监督的metric作为纵坐标,
然后找到metric最好并且k最小的结果对应的k为最终的选择;
手肘法其实也很容易做成自动化,我们计算metric变化的斜率就可以了,
具体方法就是计算k=n和k=n+1之间的斜率,当 斜率n和斜率n-1,斜率n+1和斜率n,斜率n+2和斜率n+1的差值均小于固定阈值时即可停止,代码实现上的思路和早停基本是一致的;
k-means的缺点,怎么解决?
1.对异常样本很敏感,簇心会因为异常样本被拉得很远
注意,这里的异常样本指的仅仅是在某些特征维度上取值特别大或者特别小的样本,是异常检测中定义的异常样本的一个子集,因为欧式距离的计算不考虑不同变量之间的联合分布,默认所有特征是相互独立的,所以kmeans中会对结果产生影响的异常样本特指简单的异常样本,即某些特征维度存在异常值的样本,这类异常样本通过简单的统计就可以得到;
解决方法即做好预处理,将异常样本剔除或修正;
2.k值需要事先指定,有时候难以确定;
解决方法即针对k调参;
3.只能拟合球形簇,对于流形簇等不规则的簇或是存在簇重叠问题的复杂情况等,效果较差
解决方法**,换算法**;
4.无法处理离散特征,缺失特征,
5.无法保证全局最优
解决方法:矮子里面挑高个,跑多次,取不同的局部最优里最优的
问:dbscan和optics是怎么解决这些缺点的?
dbscan和optics是基于密度的聚类
1.kmeans对异常样本很敏感,簇心会因为异常样本被拉得很远
dbscan和optics定义了密度的计算方式,不涉及到任何的平均这种鲁棒性较差的计算方式 ,对异常样本不敏感,还能检测异常样本呢;
2.k值需要事先指定,有时候难以确定;
dbscan和optics不需要指定簇的数量;算法迭代过程中自然而然产生最优的k个聚类簇;
3.kmeans只能拟合球形簇,对于流形簇等不规则的簇或是存在簇重叠问题的复杂情况等,效果较差
基于密度的聚类可以拟合任意形状的簇,这也归功于密度的计算方式,基于密度的聚类本身不对聚类簇的形状有任何的假设;
4.kmeans无法处理离散特征,缺失特征:缺失特征要插补,离散特征可以换离散特征的距离度量方法,基于密度的聚类算法可以灵活搭配各种不同的distance的度量方式;
5.kmeans无法保证全局最优:dbscan和optics也未解决!
骚!
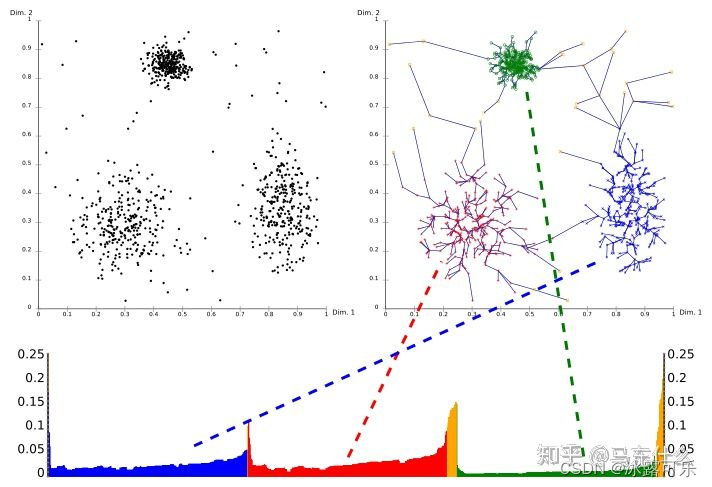
问:讲一下dbscan和optics的大致思路?
dbscan:单个超球体,病毒式扩散;
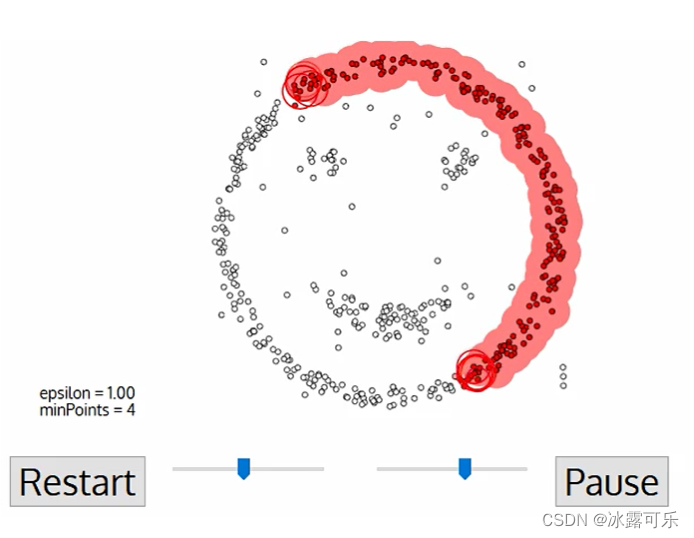
optics:两个嵌套的超球体一大一小,先映射为直方图,然后从直方图上生成聚类结果
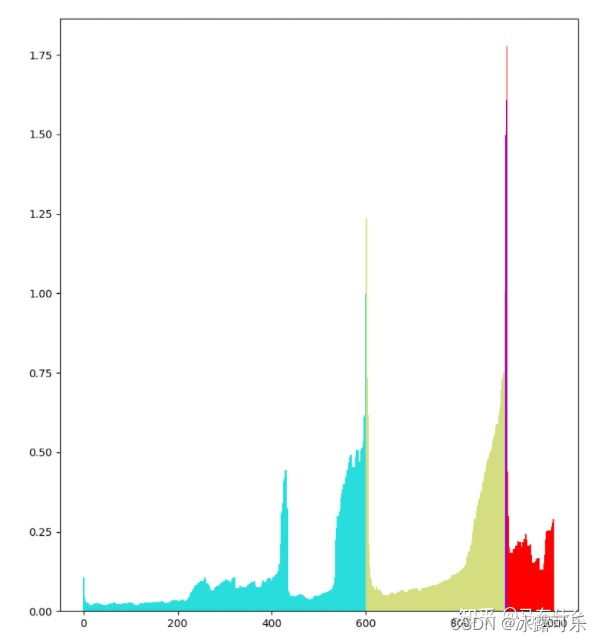
dbscan和optics:https://zhuanlan.zhihu.com/p/395088759
问:kmeans是否一定可以收敛,为什么?kmeans为什么无法保证全局最优?
loss是非凸函数!
收敛性证明就算了吧。。.这也太超纲了。.。
from K Means为什么不能收敛到全局最优点?-SofaSofa:http://sofasofa.io/forum_main_post.php?postid=1002942
kmeans的损失函数是一个非凸函数,所以无法保证全局最优;
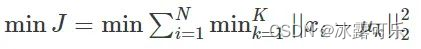
kmeans的损失函数,需要记忆一下,这里μk是第k个簇的质心,

为了方便描述,假设x是2维的,取k=1,则我们令:

的函数图像:
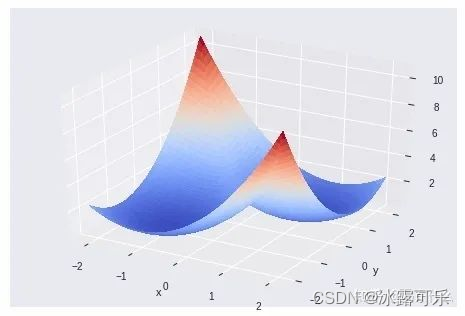
可以看到,优化目标z存在(1,1),(-1,1)两个最优解,
所以kmeans的损失函数不是一个凸函数而是一个非凸函数,难以保证收敛到全局最优。
相似度相关的
问:为什么在一些场景中要使用余弦相似度而不是欧氏距离?
如果A,B两个向量e 的模场均为1,则欧式距离和余弦距离之间满足:

总体来说,欧氏距离体现数值上的绝对差异,而余弦距离体现方向上的相对差异。
例如,统计两部剧的用户观看行为,用户A的观看向量为(0,1),用户B为 (1,0);
此时二者的余弦距离很大,而欧氏距离很小;
我们分析两个用户对于不同视频的偏好,更关注相对差异,显然应当使用余弦距离。
而当我们分析用户活跃度,以登陆次数(单位:次)和平均观看时长(单位:分钟)作为特征时,余弦距离会认为(1,10)、(10,100)两个用户距离很近;但显然这两个用户活跃度是有着极大差异的。
因此,我们关注向量数值绝对差异,应当使用欧氏距离,
如果关心的是向量方向上的相对差异,则应当使用余弦距离。
问:余弦距离是否是一个严格定义的距离? (一个度量标准要满足什么要求才能算是距离)
该题主要考察面试者对距离的定义的理解,以及简单的反证和推导。
首先看 距离的定义:在一个集合中,如果每一对元素均可唯一确定一个实数,使得三条距离公理(正定性,对称性,三角不等式)成立,则该实数可称为这对元素之间的距离。
余弦距离满足正定性和对称性,但是不满足三角不等式,因此它并不是严格定义的距离。
问:K-means 中我想聚成100类 结果发现只能聚成98类,为什么?
迭代的过程中出现空簇,原因在于k太大,实际的簇数量小于k;
但是要注意:初始化策略不会导致空簇的问题,因为即使最简单的随机初始化也是从原始的样本点里选择部分样本作为质心,如果初始质心中存在异常样本,则最终聚类的结果,这个异常点会自成一个簇而不会出现空簇的问题;
https://datascience.stackexchange.com/questions/44897/k-means-clustering-what-to-do-if-a-cluster-has-0-elements
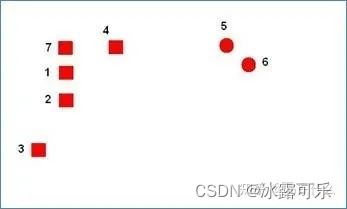
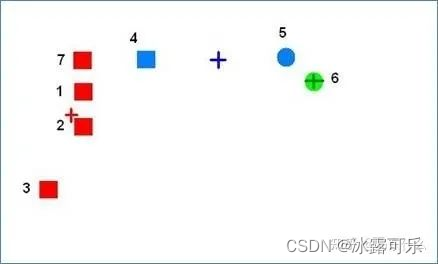
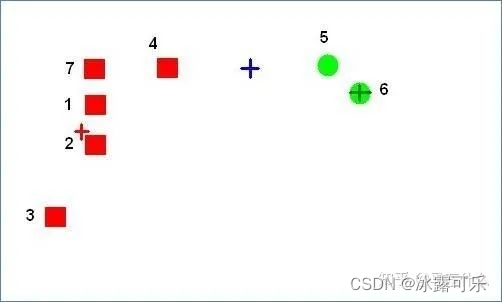
空簇对应的中心点和任意一个样本点的距离
都不是
该样本点距离其它质心点的距离的最小值。
问:kmeans,GMM,EM之间有什么关系?
kmeans是基于划分的聚类算法,
GMM是基于模型的聚类算法,
EM是估计GMM的参数使用的优化算法;
-
kmeans可以看作是GMM的一种特例,于协方差为单位矩阵,故kmeans聚类的形状是球形的,而GMM是椭球型的;
-
kmeans使用hard EM求解,GMM使用soft EM求解(kmeans感觉还是从直观上的计算过程上理解比较舒服,通过hard em也是一个解释就是了);
关于上述的原因,在下一个问题里说明
问:高斯混合模型的核心思想是什么?(GMM和多元高斯有什么区别?,多元高斯函数的期望是什么)
GMM就是多个相关多元高斯分布的加权求和;
理解GMM之前,先回归基本概念:
一元高斯分布:
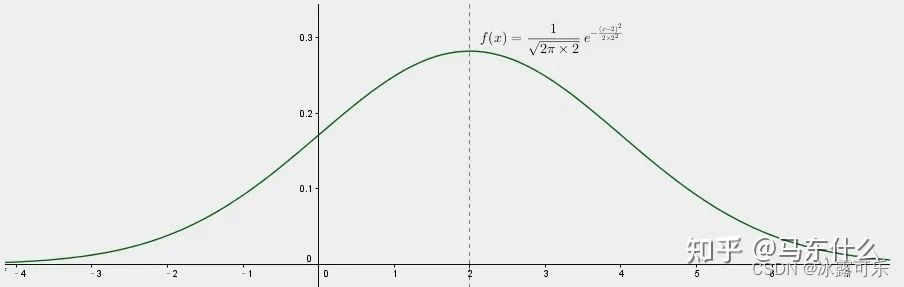


可以看到,相关系数的计算过程中,已经对变量做了均值方差的标准化处理了,所以对两个特征计算相关系数不需要考虑量纲大小的问题;
现实世界中,不同的特征(多个特征=多元)很难完全独立,因此我们也会使用非独立的多元高斯分布,公式写作:

高斯混合模型:
高斯混合模型GMM是多元高斯分布之上的概念,他认为现实世界的数据是由多个不同参数的相关多元高斯模型以不同的权重累积求和构成的(单元,独立多元高斯模型可以看作相关多元高斯模型的特例);


难记!忆了解一下即可
问:GMM是如何迭代计算的?为什么kmeans,GMM,EM满足上面描述的方式?(EM算法数学原理)
首先需要了解em算法,em算法和梯度下降法一样,都可以用来优化极大似然函数,当极大似然函数中存在隐变量时,EM算法是一种常用的优化算法;
EM算法是一种迭代优化策略,由于它的计算方法中每一次迭代都分两步,其中一个为期望步(E步),另一个为极大步(M步),所以EM算法被称为EM算法(Expectation-Maximization Algorithm)



问:为什么选择孤立森林?介绍一下iforest?
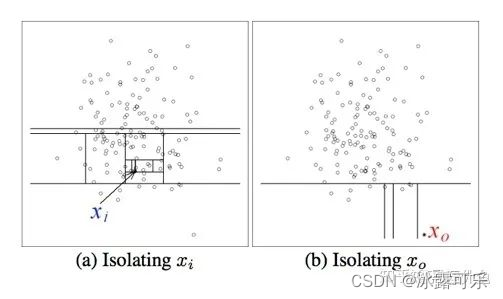
优点:基于集成异常检测的思路,鲁棒性强;
不涉及距离和密度计算,计算速度很快;每棵树独立生成可并行或分布式;
iforest的算法流程:
(1)底层是极限随机树,随机选择一个特征,随机选择部分样本(bagging),每次分裂随机选择一个分裂节点,最大深度是 log2(bagging的样本数量)
(2)整合所有极限随机树的结果,使用score function打分:

(3)score function的计算结果在0~1之间,
如果异常得分接近 1,那么一定是异常点;
如果异常得分远小于 0.5,那么一定不是异常点;
如果异常得分所有点的得分都在 0.5 左右,那么样本中很可能不存在异常点。
详细的可见:
isolation forest:https://zhuanlan.zhihu.com/p/181378482
isolation forest的score function公式到底是个啥?:https://zhuanlan.zhihu.com/p/181650438
追问:为什么高度为log2(bagging的样本数量)?为什么每次随机仅选择一小部分的样本(默认是min(bagging的样本数量,256))?
直观上来看,m个特征,我们用m个极限随机树分别进行完全分裂,分裂到叶子节点的样本特征值完全相同,得到n个样本在m个极限随机树上的分裂次数,即得到n个样本在m个特征上的分裂次数,然后取平均就可以满足我们的预测目标了。本质上通过分裂次数代替聚类或密度的计算,分裂越少,则样本在这个特征上的异常程度越高,然后综合考虑样本在多个特征上的异常程度;
但是这么做的问题有:
1.计算复杂度太高了,树的完全分裂的时间复杂度为O(n),上述做法的总的时间复杂度为O(mn);
2.本质上做的是基于集成学习的无监督学习,鲁棒性强,但是单纯用1个极限随机树分裂1个特征,随机因素影响太大,重新训练的结果差异可能会很大。解决的方法是每个特征用多个极限随机树来拟合,则计算复杂度进一步扩大为O(mnk),k为树的数量;
3.无监督的核心缺陷,无法自动特征选择,所有特征的重要性一视同仁,则如果存在大量无用特征或者噪声特征,会严重影响计算结果;

2.仍旧是针对问题1,树每次使用的样本默认为 min(采样的样本数,256),这么做主要避免了太大数量的样本上分裂次数过多**计算复杂度高 **的问题,然后通过集成提高整个模型的鲁棒性。(精度和效率之间的一种折衷,根据论文和实际的应用结果,效果还ok);
3.针对问题2,仍旧是精度和效率上的折衷 ,k个极限随机树通过采样,最终一共使用k个特征,每一轮随机选择一个特征生成一棵树;
4.针对问题1和2的不精确分裂的问题(实质上也没有办法做精确分裂),tree分裂上的不精确在实践中可以被认为提高了算法的鲁棒性,类似于lgb直方图;
5.针对问题3,特征的随机采样某些情况下缓解了无效特征的问题(大部分特征有效少部分特征无效的情况),但是本质上没有解决(大部分特征无效,少部分特征有效的情况),最终的特征工程还是要基于业务经验来进行;
追问:iforest的score function,为什么这么设计?
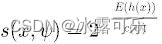 步一步拆解来看:
步一步拆解来看:
1.指数函数形式的设计
我们希望iforest输出的结果能够在一个有限的范围内,例如像auc的取值范围为0.5~1一般,有界的评估指标便于比较(高度必然为正数,因此分子部分可以保证为负数,2**-x必然是大于0小于1的);
2分子的设计:
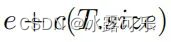
h(x)部分,并不是简单的直接计算样本在tree上的分裂次数,观察上述公式,其中e表示的才是样本在tree上的分裂次数,后面额外多了一项c(T.size)的修正项,T.size表示的样本所在叶子节点中所有样本的数量。
c(n)表示样本数量为n的情况下,生成随机二叉树的期望高度:

3.分母部分的设计:
分母部分使用的仍旧是上述的C(n)的公式,只不过分母部分的n指的是每一棵极限随机树使用的全部样本数量,即bagging得到的样本数量,默认是256个样本。这里的分母也是作为修正项存在的。
追问:为什么这里要引入分子和分母部分的修正项?
1.分子部分的修正项:
主要目的在于将样本落在的叶子节点中的样本数量大小这一因素考虑进来,假设某个样本A落入了叶子节点1,叶子节点1中有5个样本;某个样本B落入了叶子节点2,叶子节点2中有5000个样本,并且假设A和B的树的深度e都是3,则如果我们不引入修正项c(T.size),计算结果是完全相同的。但实际上很明显,A的异常程度是要高于B的,因为B所在的叶子节点的样本数量很大,其实是可以继续分裂很多次,然而考虑到性能的问题,我们对树的高度做了限制,因此会引发这样的误差。
修正项的引入可以很好的解决这个问题 ,C(n)代表了给定n个叶子节点,所能生成的随机二叉树的平均高度,显然,叶子节点数量越多,则平均高度越大,则score function的计算结果越小,从而巧妙地缓解了上述存在的问题;
2.分母部分的修正项:
主要目的在于将每个tree所训练的bagging的样本数大小这一因素考虑进来,假设bagging的样本大小为64和256,则根据iforest的设计,max_depth分别为5和8,显然,bagging的样本数量越大则树可以生成的树的深度大概率越深,因此在分母部分引入给定bagging样本数量下,所能生成的随机二叉树的平均高度,显然,bagging样本数越多,平均高度越大,则score function计算的结果越大。
问:KNN算法是否存在损失函数?
无!无!无!无!无!无!无!无!无!
knn是一种懒惰学习(lazy learning)的算法,对应的有eager learning:
lazy learning:
只存储数据集而不从中学习,不需要模型训练
收到测试数据后开始根据存储数据集对数据进行分类或回归;
eager learning:
1.从收集到的数据中学习,需要模型训练;
2.受到测试数据后直接完成分类或回归
不均衡学习:
问:数据不均衡如何解决,抽样得到的分类准确率如何转换为原准确率?
将采样后的预测的类别按照采样比例进行相应的增大或减少,例如对类别A下采样了50%,则预测结果中类别A的预测数量为m,令m=m/0.5=2m,然后计算分类准确率;
这种处理方式是不准确的,合理的方式应该是直接对原始数据进行评估指标的计算;
问:解决难样本问题的方法(hard sample problem),ohem与focal loss的相同点和不同点
问:如果把不平衡的训练集(正负样本1:3)通过降采样平衡后,那么对于平衡后的AUC值和预测概率值有怎样的变化?
roc曲线对类别数量的变化不敏感,因此auc的计算结果整体不会发生明显变化;
通过下采样平衡后,变相增大了正样本数量,分类决策边界远离正样本,预测概率整体变大;
AUC不咋变,而边界偏向正样本
问:class_weight的思想是什么?
class_weight对应的简单加权法是代价敏感学习最简单的一种方法,思想就是小类样本加权,使其在loss中比重变大;
问:不均衡学习原理?
目前主流的不均衡学习主要是关于分类问题的不均衡。所谓不均衡分类,指的是样本不同类别的数量差异越来越大的情况下,模型越来越偏向于预测大类样本的现象,因此,模型分类性能越来越差。
单纯从样本不均衡的角度出发(不考虑分布变化,小样本学习,分类问题的困难程度等其它问题),不均衡的类别对模型造成影响的原因:
1.目标函数优化的方法,使用梯度下降法优化目标函数的模型对于不均衡问题更敏感;而tree模型纯粹基于贪心策略进行分裂的方法则对此并不敏感;
2.目标函数的使用,hinge loss和交叉熵对于不均衡的敏感度不同;
不均衡是一个现象,是分类模型效果差的潜在原因之一;
问:了解哪些不均衡学习的处理方法?讲讲smote算法的原理?为什么平常很少使用smote这类基于样本生成的方法?
问:过采样(上采样)和生成样本的区别?
上采样不一定是生成样本,例如简单的repeat式的上采样,通过repeat不涉及样本生成的过程,但生成样本一定是一种上采样;
模型的loss function,metrics和optimizers
无监督metrics:
问:如何评价聚类结果的好坏(知道哪些聚类的评估指标)?轮廓系数有没有用过
sse很简单
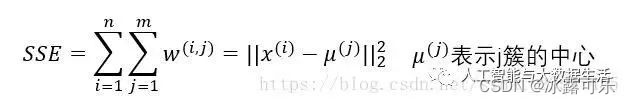

有监督metrics:
问:准确率的局限性是什么?
1.不同分类阈值下准确率会发生变化,评估起来比较麻烦;
2.对样本不均衡问题特别敏感,例如当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率;
公式:分类正确的样本数/总样本数
问:ROC曲线如何绘制,ROC和PRC的异同点;准确率(accuracy)、精确率(precision)、召回率(recall),各自的定义,各自的缺陷;PR曲线的绘制;使用PR曲线判断模型好坏;ROC曲线的横坐标、纵坐标意义;
TP,FP,TN,FN,都是英文缩写很好记忆
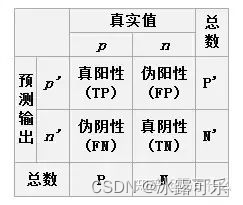
准确率=(tp+tn)/total
正负样本都自己预测准确了
精确率=tp/(tp+fp) 分子为正确预测的正样本的样本数量,分母为预测为正样本的样本数量
在被预测为正样本的情况中(包含正正,误正),算真的正样本的比率
召回率=tp/(tp+fn) 分子为正确预测的正样本的样本数量,分母为所有正样本的样本数量
**召回:**在正样本中,有的为正,有的为被误判为负样本,看看正确预测的比率,
这都是科学家们,没事整出来的组合,反正为了吃饭,各种指标啥的造一把,你记忆很困难,而且容易混乱……
误杀率=fp/(fp+tn) 分子为错误预测的正样本数量,分母为所有负样本的样本数量
被预测为否样本中,被错误预测为负样本的……
极度不均衡情况下,模型将所有样本预测为大类则准确率就能很高了;
分类阈值接近0,则模型将所有样本预测为正样本则召回率接近100%;
分类阈值接近1,则模型将极少样本预测为正样本则精确率接近100%(例如就预测一个样本为正样本并且这个样本恰好为正样本则精确率为1);
召回和精确率都受到分类阈值的影响较大;
pr曲线,以召回率为横坐标,精确率为纵坐标
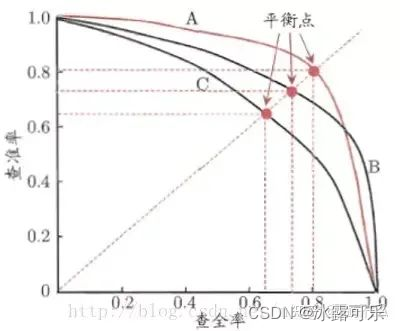
如果一个学习器的P-R曲线被另一个学习器的P-R曲线完全包住,则可认为后者的性能优于前者,例如上面的A和B优于学习器C;
一般使用平衡点来评估无法直接比较的情况例如上图的A和B模型,平衡点(BEP)是P=R时的取值,如果这个值较大,则说明学习器的性能较好。而F1 = 2 * 召回率 * 精确率 /( 召回率 + 精确率 ),同样,F1值越大,我们可以认为该学习器的性能较好。
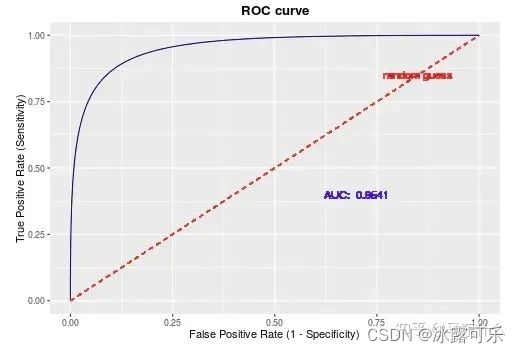
roc曲线,和pr曲线一样,纵坐标是精确率,但是横坐标是误杀率。
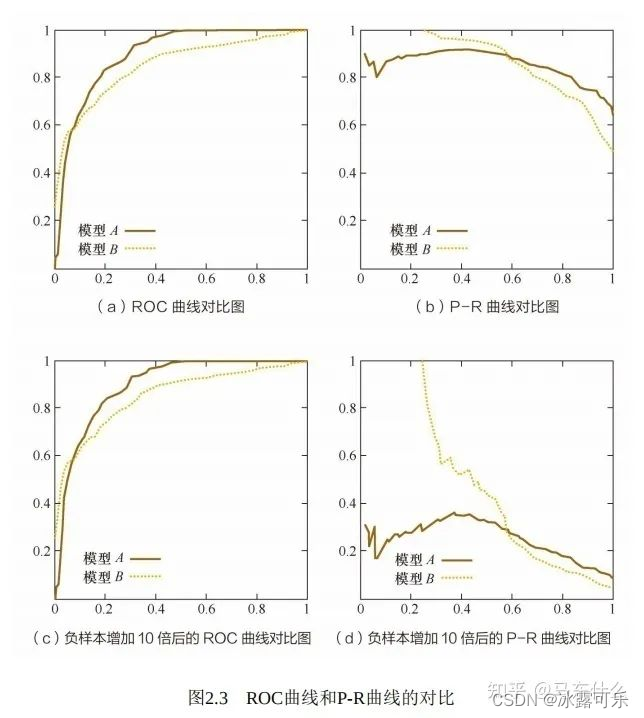
其中第一行ab均为原数据的图,左边为ROC曲线,右边为P-R曲线。
第二行cd为负样本增大10倍后俩个曲线的图。
可以看出,ROC曲线基本没有变化,但P-R曲线确剧烈震荡。
因此,在面对正负样本数量非常不均衡的场景下,
ROC曲线会是一个更加稳定能反映模型好坏的指标,
问:ROC曲线和PR曲线的区别,适用场景,各自优缺点;
**roc曲线对于正负样本比例不敏感 **,
因为roc曲线的纵坐标是精确率=预测正确的正样本/预测为正样本的样本数量,
横坐标是误杀率=预测错误的负样本/所有负样本数量,
改变了标签中类别的分布之后,预测正确的正样本/预测为正样本的样本数量,会同时发生同向的变化,
预测错误的负样本/所有负样本数量,也会发生同向的变化,
即roc的横纵坐标的计算结果是独立的,分别是针对正样本和针对负样本独立计算的,两个坐标的计算不会发生互相影响,
因此类别比例发生变化的情况下,roc也不会产生剧烈的变动;
pr曲线的纵坐标是精确率=预测正确的正样本/预测为正样本的样本数量,
横坐标是召回率=预测正确的正样本/所有正样本的数量,
即pr的横纵坐标的计算结果是存在相互关系的,他们都是针对正样本进行计算,两个坐标的计算发生互相影响,从而使得pr曲线对类别的变化很敏感;
roc聚焦于二分类模型整体对正负样本的预测能力,所以适用于评估模型整体的性能;如果主要关注正样本的预测能力而不care负样本的预测能力,则pr曲线更合适;
问:AUC的意义,AUC的计算公式?
auc是roc的曲线下面积,但是auc的实际意义仅仅从roc的曲线下面积不好理解,这里可以先了解一下auc的计算公式有哪些:
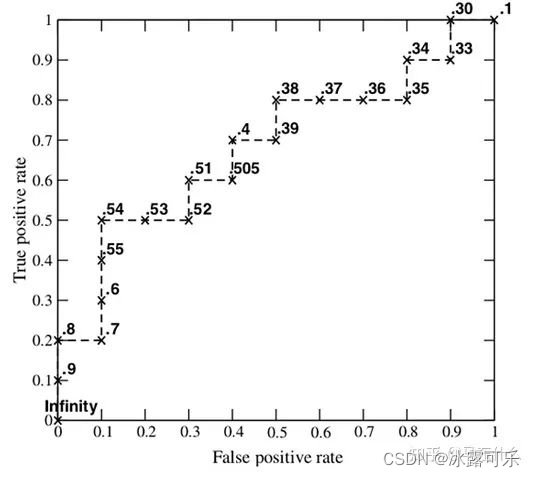
直接根据roc曲线进行计算,计算roc曲线下面积,缺点是计算误差较大,我们需要确定非常大量的分类阈值才能毕竟auc的真实计算结果;
auc的实际意义:auc的实际意义是任意选定一个正负样本对,正样本的预测结果大于负样本的预测结果的概率;
问:给你M个正样本,N个负样本,以及他们的预测值P,求AUC

问:IV值,woe值是什么?
woe是一种用于类别特征编码的编码方法,公式为:

问:roc曲线中,高于和低于对角线表示意义
roc曲线中,高于和低于对角线表示意义
roc曲线的对角线,表示一个随机预测模型的性能,如果模型的roc曲线在对角线下方,则该模型比随机模型还差,高于对角线则表示模型比随机模型好,模型是有意义的;
具体的,可以从auc的物理意义上去理解,roc的对角线下方面积为0.5,意味着对角线的随机模型的auc为0.5,结合auc的物理意义:任意选择一个正负样本对,正样本的预测结果高于负样本的预测结果的概率,则说明对角线代表的随机模型对于正负样本对的相对大小的判定是随机的;
问:多分类 auc 怎么算?
多分类问题中,在二分类指标的基础上需要进行一些处理才能适配多分类的评估,整体有两种计算策略:
基于macro的策略:ovr的划分方式,分别计算每个类别的metrics然后再进行平均
基于micro的策略:所有类放在一起算metrics;
micro的评估方式,当类别非常不均衡时,micro的计算结果会被样本数量多的类别主导,此时需要使用macro
问:F1,F2.。。.Fn值是什么,Fbeta怎么计算?
fbeta是f_metrics系列的最终定义式,公式如下:(f系列的可以统一用这个公式来记忆)
 当beta=1时,Fbeta=F1,当beta=n时,Fbeta=fn;
当beta=1时,Fbeta=F1,当beta=n时,Fbeta=fn;
beta用于定义召回率和精确率的相对重要性,越大,则recall越重要,当beta趋于无穷大时,Fbeta=recall,越小,则precision越重要,当beta**2趋于0时,Fbeta=precision
问:ks曲线和psi了解吗?

ks曲线的横坐标是分类的阈值,纵坐标代表了精确率或者误杀率,一个分类阈值对应的一个精确率和一个误杀率,而ks曲线就是用每个分类阈值下的精确率-误杀率,ks值则是指ks曲线上的最大值;

loss function
问:知道哪些常见的损失函数?
点预测问题:0-1损失函数:
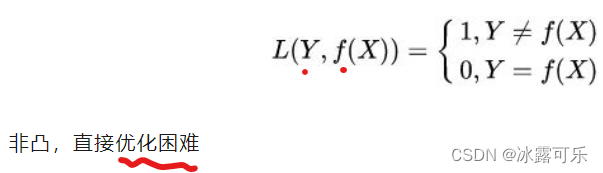
logloss(交叉熵)(多分类),
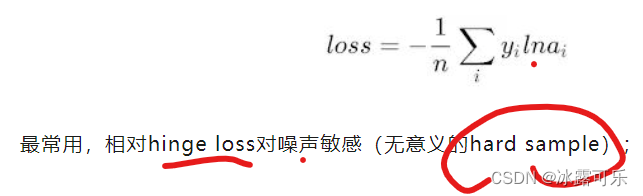
Cross-entropy(二元交叉熵)(logloss在二分类的特例):

exponential loss

hingeloss,
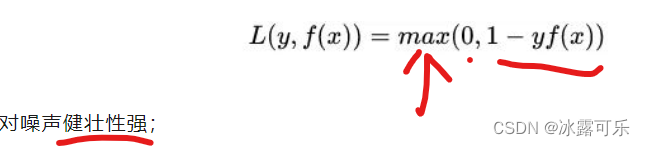
mse,mae,rmse,mape,smape:
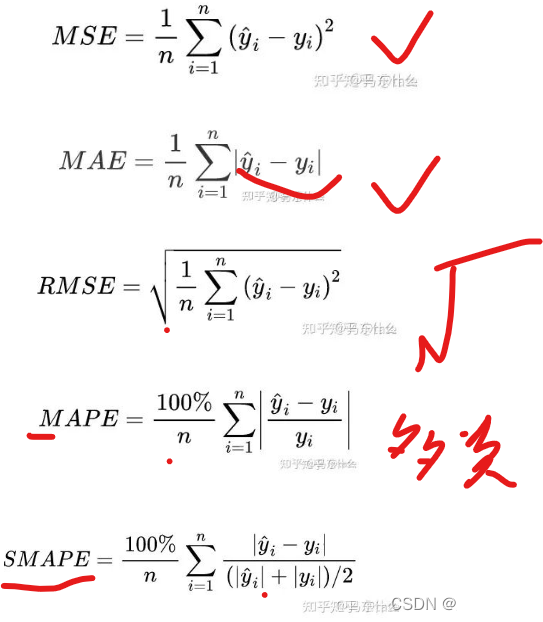
mse,mae,rmse对标签y取值特别大的样本鲁棒性都较差,mae和rmse相对有所缓解,
mape:范围[0,+∞),MAPE 为0%表示完美模型,MAPE 大于 100 %则表示劣质模型。
可以看到,MAPE就是mae 多了个分母。
注意点:当真实值有数据等于0时,存在分母0除问题,需要做平滑
mape对标签y取值特别大的样本的鲁棒性较强,因为通过除以真实标签(即分母项),对单个异常样本的loss进行了放缩;缺陷在于对标签y取值接近0的样本鲁棒性很差,一点点的偏差就会使得单个样本的mape的loss的计算结果很大,
smape:smape是针对mape的对异常小样本的鲁棒性很差的问题进行了修正,可以较好的避免mape因为真实值yi小而计算结果太大的问题;同时对异常大的样本的鲁棒性也较好;
mape和smape都可以作为loss function进行优化;
区间预测问题:
直接估计参数的分布的参数,贝叶斯深度学习这部分内容里有,之前看的deepar也是用的这种,称为distribution loss,这块儿研究的不多,后续应该找个时间好好系统性的看一下回归中的区间预测问题;
问:mse对于异常样本的鲁棒性差的问题怎么解决?
1、如果异常样本无意义,则对异常样本进行平滑等方式处理成正常样本,如果异常样本很稀少,直接删除也可以;
- 如果异常样本有意义,例如双十一销量,需要模型把这些有意义的异常考虑进来,则从模型侧考虑使用表达能力更强的模型或复合模型或分群建模等;
3.loss function层面选择更鲁棒的损失函数例如smape
二分类为什么用二元交叉熵?为什么不用mse?
原因:sigmoid对模型输出进行压缩到(0,1)区间的条件下,根据二元交叉熵得到的梯度更新公式中不包含sigmoid的求导项,根据mse的得到的梯度更新公式则会包含 。
使用mse推导出的梯度更新量:

根据二元交叉熵推导出来的梯度更新公式:

问:mse,sigmoid+交叉熵梯度推导
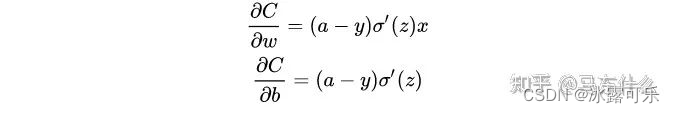
没有sigmoid或其它的转换,则公式中求导项为1,
二元交叉熵(带sigmoid,求导过程中用到sigmoid的导数公式,否则到第二张图的第二步就可以停止了):
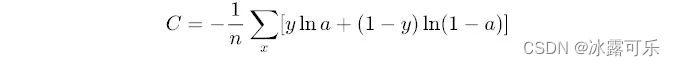
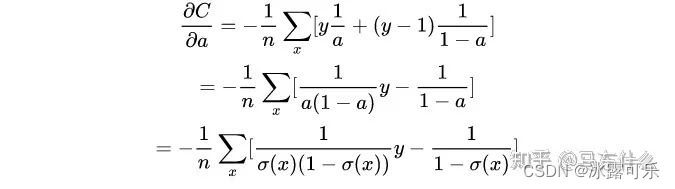
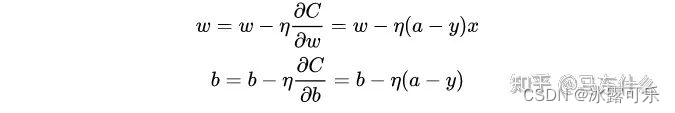
问:信息量,信息熵、相对熵(KL散度)、交叉熵、条件熵、互信息、联合熵的概念和公式?
信息量用来度量一个事件的不确定性程度,
不确定性越高则信息量越大,
一般通过事件发生的概率来定义不确定性,信息量则是基于概率密度函数的log运算,用以下式子定义:

信息熵,衡量的是一个事件集合的不确定性程度,就是事件集合中所有事件的不确定性的期望,公式定义如下:
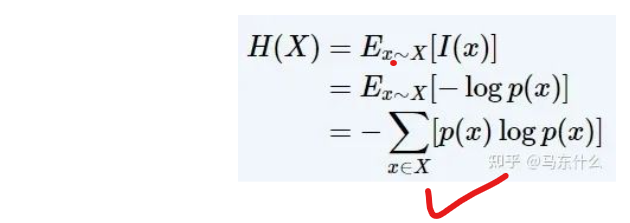
相对熵(kl散度): kl散度,从概统角度出发,表示用于两个概率分布的差异的非对称衡量,kl散度也可以从信息理论的角度出发,从这个角度出发的kl散度我们也可以称之为相对熵,实际上描述的是两个概率分布的信息熵的差值:

js散度公式如下:


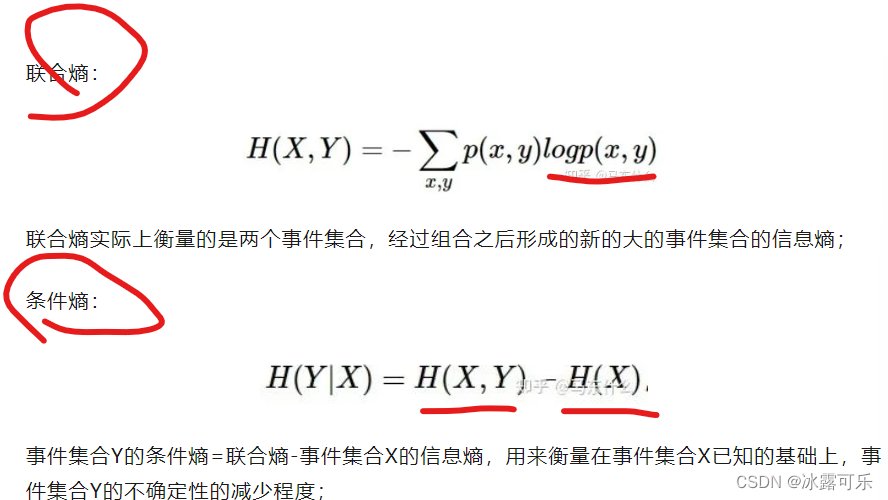
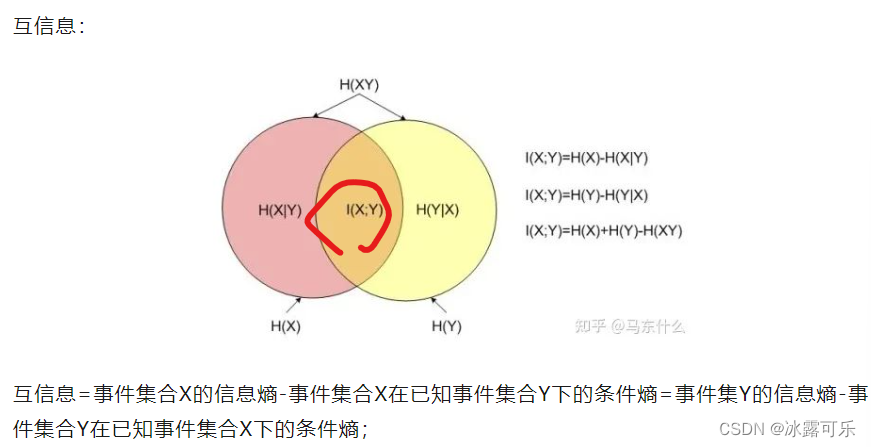
问:怎么衡量两个分布的差异?KL散度和交叉熵损失有什么不同?关系是啥?
kl散度,js散度,以及迁移学习里的许多更advanced的评估方式例如mmd,
交叉熵=真实的标签分布的信息熵+相对熵(kl散度)
问:距离的定义?哪些度量方法不符合距离的定义
距离的定义:在一个集合中,如果每一对元素均可唯一确定一个实数,使得三条距离公理(正定性,对称性,三角不等式)成立,则该实数可称为这对元素之间的距离。
1:正定性,d(x,y)>=0,仅当x=y则不等式等号成立,说白了就是如果样本A和样本B的距离为0,则样本A和样本B可以看作同一个样本;
2:对称性:d(x,y)=d(y,x),即样本A到样本B的距离等于样本B到样本A的距离;
3:**d(x,y)<d(x,z)+d(z,y),**即样本A到样本B的距离小于样本A到样本C的距离+样本B到样本C的距离
余弦距离不满足三角不等式,kl散度不满足对称性,因此二者都不是严格意义上的距离的定义;
问:交叉熵的设计思想是什么?
优化交叉熵等价于优化kl散度,

问:写 huber loss 公式,huber loss了解吗?和mse、比起来优势是啥?
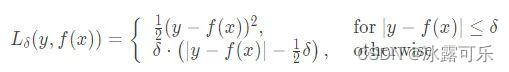
通过引入超参数sigma,huber loss可以灵活动态的调整模型使用的loss function是mse还是mae,
这确保了损失函数不会受到异常值的严重影响,同时不会完全忽略它们的影响
最优化方法:
推导梯度下降公式
这里问的是梯度下降的一般性的表达式
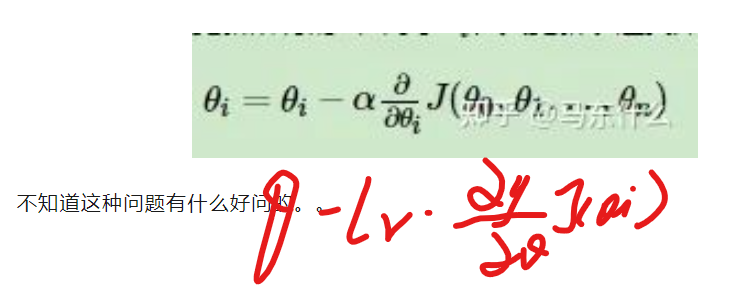
问:知道哪些常见的一、二阶优化方法?
牛顿法的收敛速度,是不是一定比梯度下降快(举反例),Hessian矩阵的求逆与计算量问题(正则化,Hessian矩阵的近似),牛顿下降的几个phase,KKT的仔细描述。拟牛顿法和牛顿法的关系,拟牛顿法解决了牛顿法哪个问题?推导下牛顿法。牛顿法在什么时候只需要迭代一次就能求解,什么时候牛顿法不能适用
问:极大似然估计,结构,经验风险最小化的关系,交叉熵和最大似然 损失函数的区别,讲一下极大似然估计,极大似然估计和最大后验估计的区别是什么?最小二乘与极大似然函数的关系?先验,后验,最大似然估计,最大后验估计?
问:讲一下jaccob矩阵和Hessian矩阵?Hessian矩阵是对称矩阵吗?
问:机器学习中的优化问题,哪些是凸优化问题,哪些是非凸优化问题?请各举 一个例子。
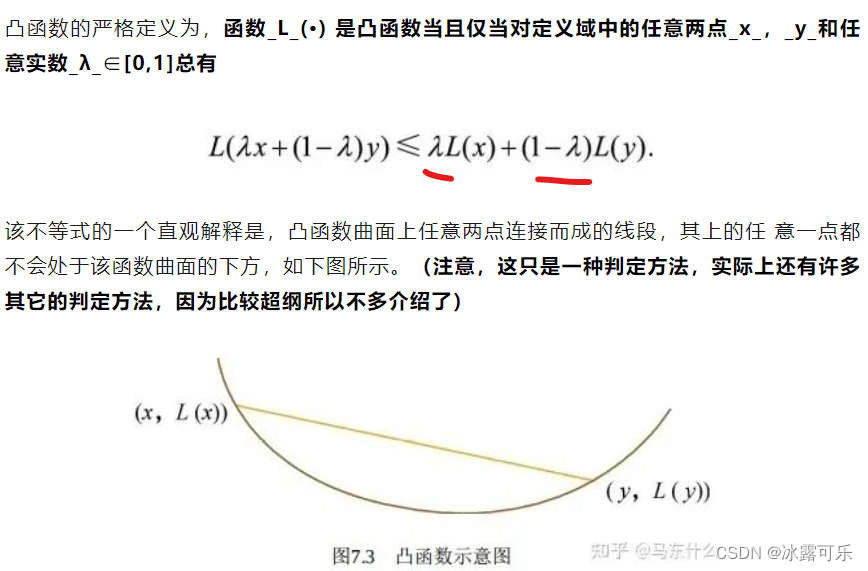
凸优化问题的例子包括支持向量机、线性回归等线性模型,
非凸优化问题的例子包括低秩模型(如矩阵分解)、深度神经网络模型等,
凸函数和优化算法没有直接的关系,
对于模型而言其目标函数是凸函数,不一定使用梯度下降法进行求解,
例如GMM的目标函数(带隐变量的极大似然函数)使用EM算法进行迭代求解。
自动化机器学习/模型应用和特征工程部分
问:模型和超参数有哪些自动化调优方法?它们各自有什么特点?
问:简述贝叶斯优化中用高斯过程回归计算目标函数后验分布的方法。高斯过程回归可以用于种类型或者层次型模型配置参数的优化吗?
问:贝叶斯优化中的获得函数是什么?起到什么作用?请介绍常用的获得函数。
……
总结
提示:重要经验:
1)史上最全的机器学习深度学习面经总结
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。


















 2031
2031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











