










数据挖掘,计算机网络、操作系统刷题笔记45
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
考网警特招必然要考操作系统,计算机网络,由于备考时间不长,你可能需要速成,我就想办法自学速成了,课程太长没法玩
刷题系列文章
【1】Oracle数据库:刷题错题本,数据库的各种概念
【2】操作系统,计算机网络,数据库刷题笔记2
【3】数据库、计算机网络,操作系统刷题笔记3
【4】数据库、计算机网络,操作系统刷题笔记4
【5】数据库、计算机网络,操作系统刷题笔记5
【6】数据库、计算机网络,操作系统刷题笔记6
【7】数据库、计算机网络,操作系统刷题笔记7
【8】数据库、计算机网络,操作系统刷题笔记8
【9】操作系统,计算机网络,数据库刷题笔记9
【10】操作系统,计算机网络,数据库刷题笔记10
【11】操作系统,计算机网络,数据库刷题笔记11
【12】操作系统,计算机网络,数据库刷题笔记12
【13】操作系统,计算机网络,数据库刷题笔记13
【14】操作系统,计算机网络,数据库刷题笔记14
【15】计算机网络、操作系统刷题笔记15
【16】数据库,计算机网络、操作系统刷题笔记16
【17】数据库,计算机网络、操作系统刷题笔记17
【18】数据库,计算机网络、操作系统刷题笔记18
【19】数据库,计算机网络、操作系统刷题笔记19
【20】数据库,计算机网络、操作系统刷题笔记20
【21】数据库,计算机网络、操作系统刷题笔记21
【22】数据库,计算机网络、操作系统刷题笔记22
【23】数据库,计算机网络、操作系统刷题笔记23
【24】数据库,计算机网络、操作系统刷题笔记24
【25】数据库,计算机网络、操作系统刷题笔记25
【26】数据库,计算机网络、操作系统刷题笔记26
【27】数据库,计算机网络、操作系统刷题笔记27
【28】数据库,计算机网络、操作系统刷题笔记28
【29】数据库,计算机网络、操作系统刷题笔记29
【30】数据库,计算机网络、操作系统刷题笔记30
【31】数据库,计算机网络、操作系统刷题笔记31
【32】数据库,计算机网络、操作系统刷题笔记32
【33】数据库,计算机网络、操作系统刷题笔记33
【34】数据库,计算机网络、操作系统刷题笔记34
【35】数据挖掘,计算机网络、操作系统刷题笔记35
【36】数据挖掘,计算机网络、操作系统刷题笔记36
【37】数据挖掘,计算机网络、操作系统刷题笔记37
【38】数据挖掘,计算机网络、操作系统刷题笔记38
【39】数据挖掘,计算机网络、操作系统刷题笔记39
【40】数据挖掘,计算机网络、操作系统刷题笔记40
【41】数据挖掘,计算机网络、操作系统刷题笔记41
【42】数据挖掘,计算机网络、操作系统刷题笔记42
【43】数据挖掘,计算机网络、操作系统刷题笔记43
【44】数据挖掘,计算机网络、操作系统刷题笔记44
文章目录
- 数据挖掘,计算机网络、操作系统刷题笔记45
-
- 数据挖掘分析应用:特征衍生
- 特征工程的小结
- 有关路由器和二层交换机的区别,下述错误的是?
- 工作在应用层的协议,才有源端口与目的端口之分,FTP是应用层协议
- 目前普通家庭连接因特网,以下几种方式哪种传输速率最高 ( )
- 下列哪些http方法对于服务端和用户端一定是安全的?()
- IP 数据报穿越 Internet 过程中有可能被分片。在 IP 数据报分片以后,下列哪个设备负责数据报的重组( )?
- ICMP不是高层协议,而是IP层的协议,ICMP报文是装在IP数据报中,作为其中的数据部分
- 301,代表被请求的资源已永久移动到新位置,用于重定向
- 星形结构的网络采用的是广播式的传播方式。( )
- CPU,属于靠剥夺资源,因为CPU可以发生中断。中断,也就是资源的使用被打断了,也就是我们常说的可以被剥夺
- 联想存储器在计算机系统中是用于( )的。
- 线程间可以直接读写进程数据段(如全局变量)来进行通信
- 总结
文章目录
- 数据挖掘,计算机网络、操作系统刷题笔记45
- 数据挖掘分析应用:特征衍生
- 特征工程的小结
- 有关路由器和二层交换机的区别,下述错误的是?
- 工作在应用层的协议,才有源端口与目的端口之分,FTP是应用层协议
- 目前普通家庭连接因特网,以下几种方式哪种传输速率最高 ( )
- 下列哪些http方法对于服务端和用户端一定是安全的?()
- IP 数据报穿越 Internet 过程中有可能被分片。在 IP 数据报分片以后,下列哪个设备负责数据报的重组( )?
- ICMP不是高层协议,而是IP层的协议,ICMP报文是装在IP数据报中,作为其中的数据部分
- 301,代表被请求的资源已永久移动到新位置,用于重定向
- 星形结构的网络采用的是广播式的传播方式。( )
- CPU,属于靠剥夺资源,因为CPU可以发生中断。中断,也就是资源的使用被打断了,也就是我们常说的可以被剥夺
- 联想存储器在计算机系统中是用于( )的。
- 线程间可以直接读写进程数据段(如全局变量)来进行通信
- 总结
数据挖掘分析应用:特征衍生
现有的特征,经过组合,具有新的含义的特征
如果采集到的的特征不多,可能需要交叉一波?
没错,就是加减乘除
很骚

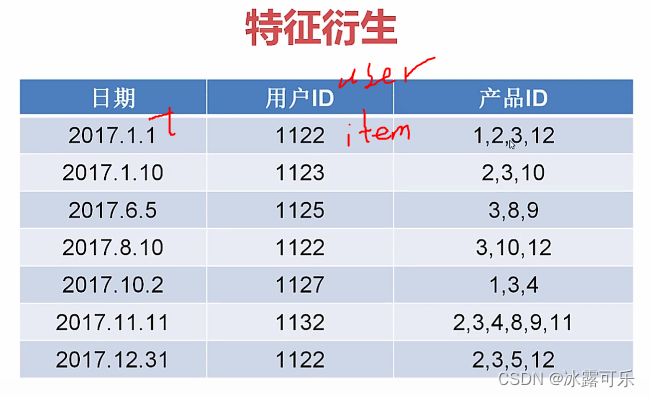

用户1122经常买
3产品快销
2是冬季
1122老是买特定的产品
这就是特征衍生
HR表的各个属性,我们来用特征处理玩一下
def f6(sl=False):
# 处理HR表
df = pd.read_csv('../HR_comma_sep.csv')
# 标注label就是离职率left
label = df['left']
df = df.drop('left', axis=1) # 删除left列,而不是行哦
# 清洗数据,除去异常值,抽样啥的
df = df.dropna(subset=['satisfaction_level', 'last_evaluation'])
df = df[df['satisfaction_level']<=1][df['salary']!='nme']
# 特征选择,之前我们见过,left与last_evaluetion,number_projection,是无关的
# 特征处理
# satisfaction_level处于0--1之间,这个可以保留不动,可以缩放到--1,可以标准化
# sl为True时,minmax化,False时,standard 处理
scalar_list = [sl]
column_list = ['satisfaction_level']
for i in range(len(scalar_list)):
if not scalar_list[i]:
df[column_list[i]] = MinMaxScaler().fit_transform(df[column_list[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
# 转换列--行,取0行
else:
df[column_list[i]] = StandardScaler().fit_transform(df[column_list[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
# 转换
print(df)
if __name__ == '__main__':
f6()
satisfaction_level last_evaluation ... department salary
0 0.38 0.53 ... sales low
1 0.80 0.86 ... sales medium
2 0.11 0.88 ... sales medium
3 0.72 0.87 ... sales low
4 0.37 0.52 ... sales low
... ... ... ... ... ...
14994 0.40 0.57 ... support low
14995 0.37 0.48 ... support low
14996 0.37 0.53 ... support low
14997 0.11 0.96 ... support low
14998 0.37 0.52 ... support low
[14999 rows x 10 columns]
satisfaction_level last_evaluation ... department salary
0 0.318681 0.53 ... sales low
1 0.780220 0.86 ... sales medium
2 0.021978 0.88 ... sales medium
3 0.692308 0.87 ... sales low
4 0.307692 0.52 ... sales low
... ... ... ... ... ...
14994 0.340659 0.57 ... support low
14995 0.307692 0.48 ... support low
14996 0.307692 0.53 ... support low
14997 0.021978 0.96 ... support low
14998 0.307692 0.52 ... support low
[14999 rows x 9 columns]
Process finished with exit code 0
将特征缩放之后的结果不同
scalar_list 里面放了第几个字段,第几个字段应该是true或者false
然后对应的column_list里面放着应该处理的HR表里面的第几个字段
这样对应两种处理器,按规则去处理即可
def f6(sl=False):
# 处理HR表
df = pd.read_csv('../HR_comma_sep.csv')
print(df)
# 标注label就是离职率left
label = df['left']
df = df.drop('left', axis=1) # 删除left列,而不是行哦
# 清洗数据,除去异常值,抽样啥的
df = df.dropna(subset=['satisfaction_level', 'last_evaluation'])
df = df[df['satisfaction_level']<=1][df['salary']!='nme']
# 特征选择,之前我们见过,left与last_evaluetion,number_projection,是无关的
# 特征处理
# satisfaction_level处于0--1之间,这个可以保留不动,可以缩放到--1,可以标准化
# sl为True时,minmax化,False时,standard 处理
scalar_list = [sl]
column_list = ['satisfaction_level']
for i in range(len(scalar_list)):
if not scalar_list[i]:
df[column_list[i]] = MinMaxScaler().fit_transform(df[column_list[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
# 转换列--行,取0行
else:
df[column_list[i]] = StandardScaler().fit_transform(df[column_list[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
# 转换
print(df)
if __name__ == '__main__':
f6(sl=True)
satisfaction_level last_evaluation ... department salary
0 0.38 0.53 ... sales low
1 0.80 0.86 ... sales medium
2 0.11 0.88 ... sales medium
3 0.72 0.87 ... sales low
4 0.37 0.52 ... sales low
... ... ... ... ... ...
14994 0.40 0.57 ... support low
14995 0.37 0.48 ... support low
14996 0.37 0.53 ... support low
14997 0.11 0.96 ... support low
14998 0.37 0.52 ... support low
[14999 rows x 10 columns]
satisfaction_level last_evaluation ... department salary
0 -0.936495 0.53 ... sales low
1 0.752814 0.86 ... sales medium
2 -2.022479 0.88 ... sales medium
3 0.431041 0.87 ... sales low
4 -0.976716 0.52 ... sales low
... ... ... ... ... ...
14994 -0.856051 0.57 ... support low
14995 -0.976716 0.48 ... support low
14996 -0.976716 0.53 ... support low
14997 -2.022479 0.96 ... support low
14998 -0.976716 0.52 ... support low
[14999 rows x 9 columns]
Process finished with exit code 0
当True时,就用的是均质化的归一化
有负值
懂?
搞定
来看第二个属性
last_evaluation和satisfaction类似
def f6(sl=False, le=False):
# 处理HR表
df = pd.read_csv('../HR_comma_sep.csv')
print(df)
# 标注label就是离职率left
label = df['left']
df = df.drop('left', axis=1) # 删除left列,而不是行哦
# 清洗数据,除去异常值,抽样啥的
df = df.dropna(subset=['satisfaction_level', 'last_evaluation'])
df = df[df['satisfaction_level']<=1][df['salary']!='nme']
# 特征选择,之前我们见过,left与last_evaluetion,number_projection,是无关的
# 特征处理
# satisfaction_level处于0--1之间,这个可以保留不动,可以缩放到--1,可以标准化
# sl为True时,minmax化,False时,standard 处理
scalar_list = [sl, le]
column_list = ['satisfaction_level', 'last_evaluation']
for i in range(len(scalar_list)):
if not scalar_list[i]:
df[column_list[i]] = MinMaxScaler().fit_transform(df[column_list[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
# 转换列--行,取0行
else:
df[column_list[i]] = StandardScaler().fit_transform(df[column_list[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
# 转换
# last_evaluation和satisfaction类似,le为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
print(df)
if __name__ == '__main__':
f6(sl=True, le=True)
satisfaction_level last_evaluation ... department salary
0 0.38 0.53 ... sales low
1 0.80 0.86 ... sales medium
2 0.11 0.88 ... sales medium
3 0.72 0.87 ... sales low
4 0.37 0.52 ... sales low
... ... ... ... ... ...
14994 0.40 0.57 ... support low
14995 0.37 0.48 ... support low
14996 0.37 0.53 ... support low
14997 0.11 0.96 ... support low
14998 0.37 0.52 ... support low
[14999 rows x 10 columns]
satisfaction_level last_evaluation ... department salary
0 -0.936495 -1.087275 ... sales low
1 0.752814 0.840707 ... sales medium
2 -2.022479 0.957554 ... sales medium
3 0.431041 0.899131 ... sales low
4 -0.976716 -1.145699 ... sales low
... ... ... ... ... ...
14994 -0.856051 -0.853580 ... support low
14995 -0.976716 -1.379394 ... support low
14996 -0.976716 -1.087275 ... support low
14997 -2.022479 1.424944 ... support low
14998 -0.976716 -1.145699 ... support low
[14999 rows x 9 columns]
Process finished with exit code 0
last_evaluation 也被处理过了
怎么说,你懂?
其实无所谓的
你只要是数值类型的,都可以这么归一化处理的
懂????
number_project不大于10
def f6(sl=False, le=False, npr=False):
# 处理HR表
df = pd.read_csv('../HR_comma_sep.csv')
print(df)
# 标注label就是离职率left
label = df['left']
df = df.drop('left', axis=1) # 删除left列,而不是行哦
# 清洗数据,除去异常值,抽样啥的
df = df.dropna(subset=['satisfaction_level', 'last_evaluation'])
df = df[df['satisfaction_level']<=1][df['salary']!='nme']
# 特征选择,之前我们见过,left与last_evaluetion,number_projection,是无关的
# 特征处理
# satisfaction_level处于0--1之间,这个可以保留不动,可以缩放到--1,可以标准化
# sl为True时,minmax化,False时,standard 处理
scalar_list = [sl, le, npr]
column_list = ['satisfaction_level', 'last_evaluation', 'number_project']
for i in range(len(scalar_list)):
if not scalar_list[i]:
df[column_list[i]] = MinMaxScaler().fit_transform(df[column_list[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
# 转换列--行,取0行
else:
df[column_list[i]] = StandardScaler().fit_transform(df[column_list[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
# 转换
# last_evaluation和satisfaction类似,le为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# number_project不大于10,npr为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
print(df)
if __name__ == '__main__':
f6(sl=True, le=True, npr=False)
pd.set_option('display.max_columns', None) # 展示所有列
satisfaction_level last_evaluation number_project \
0 0.38 0.53 2
1 0.80 0.86 5
2 0.11 0.88 7
3 0.72 0.87 5
4 0.37 0.52 2
... ... ... ...
14994 0.40 0.57 2
14995 0.37 0.48 2
14996 0.37 0.53 2
14997 0.11 0.96 6
14998 0.37 0.52 2
average_montly_hours time_spend_company Work_accident left \
0 157 3 0 1
1 262 6 0 1
2 272 4 0 1
3 223 5 0 1
4 159 3 0 1
... ... ... ... ...
14994 151 3 0 1
14995 160 3 0 1
14996 143 3 0 1
14997 280 4 0 1
14998 158 3 0 1
promotion_last_5years department salary
0 0 sales low
1 0 sales medium
2 0 sales medium
3 0 sales low
4 0 sales low
... ... ... ...
14994 0 support low
14995 0 support low
14996 0 support low
14997 0 support low
14998 0 support low
[14999 rows x 10 columns]
satisfaction_level last_evaluation number_project \
0 -0.936495 -1.087275 0.0
1 0.752814 0.840707 0.6
2 -2.022479 0.957554 1.0
3 0.431041 0.899131 0.6
4 -0.976716 -1.145699 0.0
... ... ... ...
14994 -0.856051 -0.853580 0.0
14995 -0.976716 -1.379394 0.0
14996 -0.976716 -1.087275 0.0
14997 -2.022479 1.424944 0.8
14998 -0.976716 -1.145699 0.0
average_montly_hours time_spend_company Work_accident \
0 157 3 0
1 262 6 0
2 272 4 0
3 223 5 0
4 159 3 0
... ... ... ...
14994 151 3 0
14995 160 3 0
14996 143 3 0
14997 280 4 0
14998 158 3 0
promotion_last_5years department salary
0 0 sales low
1 0 sales medium
2 0 sales medium
3 0 sales low
4 0 sales low
... ... ... ...
14994 0 support low
14995 0 support low
14996 0 support low
14997 0 support low
14998 0 support low
[14999 rows x 9 columns]
Process finished with exit code 0
展示所有列之后,npr就变化了
其他的字段,都类似
只要是数值,都可以这么玩
pd.set_option('display.max_columns', None) # 展示所有列
def f6(sl=False, le=False, npr=False, amh=False, tsc=False, wacc=False, pla=False):
# 处理HR表
df = pd.read_csv('../HR_comma_sep.csv')
print(df)
# 标注label就是离职率left
label = df['left']
df = df.drop('left', axis=1) # 删除left列,而不是行哦
# 清洗数据,除去异常值,抽样啥的
df = df.dropna(subset=['satisfaction_level', 'last_evaluation'])
df = df[df['satisfaction_level']<=1][df['salary']!='nme']
# 特征选择,之前我们见过,left与last_evaluetion,number_projection,是无关的
# 特征处理
# satisfaction_level处于0--1之间,这个可以保留不动,可以缩放到--1,可以标准化
# sl为True时,minmax化,False时,standard 处理
scalar_list = [sl, le, npr, amh, tsc, wacc, pla]
column_list = ['satisfaction_level', 'last_evaluation', 'number_project', 'average_montly_hours',
'time_spend_company', 'Work_accident', 'promotion_last_5years']
for i in range(len(scalar_list)):
if not scalar_list[i]:
df[column_list[i]] = MinMaxScaler().fit_transform(df[column_list[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
# 转换列--行,取0行
else:
df[column_list[i]] = StandardScaler().fit_transform(df[column_list[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
# 转换
# last_evaluation和satisfaction类似,le为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# number_project不大于10,npr为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# time_spend_company不大于10,tsc为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# average_montly_hours范围很大,我们最好将其离散化,由于数据不大,最好保留
# 当然也能处理,average_montly_hours,amh为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# Work_accident和promotion_last_5years是0-1的
# Work_accident不大于10,wacc为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# promotion_last_5years不大于10,pla为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
print(df)
if __name__ == '__main__':
f6(sl=True, le=True, npr=False, amh=False, wacc=True, pla=False)
satisfaction_level last_evaluation number_project \
0 0.38 0.53 2
1 0.80 0.86 5
2 0.11 0.88 7
3 0.72 0.87 5
4 0.37 0.52 2
... ... ... ...
14994 0.40 0.57 2
14995 0.37 0.48 2
14996 0.37 0.53 2
14997 0.11 0.96 6
14998 0.37 0.52 2
average_montly_hours time_spend_company Work_accident left \
0 157 3 0 1
1 262 6 0 1
2 272 4 0 1
3 223 5 0 1
4 159 3 0 1
... ... ... ... ...
14994 151 3 0 1
14995 160 3 0 1
14996 143 3 0 1
14997 280 4 0 1
14998 158 3 0 1
promotion_last_5years department salary
0 0 sales low
1 0 sales medium
2 0 sales medium
3 0 sales low
4 0 sales low
... ... ... ...
14994 0 support low
14995 0 support low
14996 0 support low
14997 0 support low
14998 0 support low
[14999 rows x 10 columns]
satisfaction_level last_evaluation number_project \
0 -0.936495 -1.087275 0.0
1 0.752814 0.840707 0.6
2 -2.022479 0.957554 1.0
3 0.431041 0.899131 0.6
4 -0.976716 -1.145699 0.0
... ... ... ...
14994 -0.856051 -0.853580 0.0
14995 -0.976716 -1.379394 0.0
14996 -0.976716 -1.087275 0.0
14997 -2.022479 1.424944 0.8
14998 -0.976716 -1.145699 0.0
average_montly_hours time_spend_company Work_accident \
0 0.285047 0.125 -0.411165
1 0.775701 0.500 -0.411165
2 0.822430 0.250 -0.411165
3 0.593458 0.375 -0.411165
4 0.294393 0.125 -0.411165
... ... ... ...
14994 0.257009 0.125 -0.411165
14995 0.299065 0.125 -0.411165
14996 0.219626 0.125 -0.411165
14997 0.859813 0.250 -0.411165
14998 0.289720 0.125 -0.411165
promotion_last_5years department salary
0 0.0 sales low
1 0.0 sales medium
2 0.0 sales medium
3 0.0 sales low
4 0.0 sales low
... ... ... ...
14994 0.0 support low
14995 0.0 support low
14996 0.0 support low
14997 0.0 support low
14998 0.0 support low
[14999 rows x 9 columns]
Process finished with exit code 0
最后来看俩离散的类别值
pd.set_option('display.max_columns', None) # 展示所有列
def f6(sl=False, le=False, npr=False, amh=False, tsc=False,
wacc=False, pla=False, dep=False, sal=False):
# 处理HR表
df = pd.read_csv('../HR_comma_sep.csv')
print(df)
# 标注label就是离职率left
label = df['left']
df = df.drop('left', axis=1) # 删除left列,而不是行哦
# 清洗数据,除去异常值,抽样啥的
df = df.dropna(subset=['satisfaction_level', 'last_evaluation'])
df = df[df['satisfaction_level']<=1][df['salary']!='nme']
# 特征选择,之前我们见过,left与last_evaluetion,number_projection,是无关的
# 特征处理
# satisfaction_level处于0--1之间,这个可以保留不动,可以缩放到--1,可以标准化
# sl为True时,minmax化,False时,standard 处理
scalar_list = [sl, le, npr, amh, tsc, wacc, pla]
column_list = ['satisfaction_level', 'last_evaluation', 'number_project', 'average_montly_hours',
'time_spend_company', 'Work_accident', 'promotion_last_5years']
for i in range(len(scalar_list)):
if not scalar_list[i]:
df[column_list[i]] = MinMaxScaler().fit_transform(df[column_list[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
# 转换列--行,取0行
else:
df[column_list[i]] = StandardScaler().fit_transform(df[column_list[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
# 转换
# last_evaluation和satisfaction类似,le为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# number_project不大于10,npr为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# time_spend_company不大于10,tsc为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# average_montly_hours范围很大,我们最好将其离散化,由于数据不大,最好保留
# 当然也能处理,average_montly_hours,amh为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# Work_accident和promotion_last_5years是0-1的
# Work_accident不大于10,wacc为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# promotion_last_5years不大于10,pla为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# department,将其数值化,dep,True:LabelEncoding,False:OneHotEncoding
# salary,将其数值化,sal,True:LabelEncoding,False:OneHotEncoding
scalar_list = [dep, sal]
column_list = ['department', 'salary']
for i in range(len(scalar_list)):
if not scalar_list[i]:
#建议salary是按照0 1 2低中去编码
if column_list[i] == "salary":
df[column_list[i]] = [map_salary(s) for s in df['salary'].values] # 字段所有行都去遍历处理
else:
df[column_list[i]] = LabelEncoder().fit_transform(df[column_list[i]]) # department是按照字母排序编码
else:
df = pd.get_dummies(df, columns=[column_list[i]]) # 这是onehot编码
print(df)
def map_salary(s):
d = dict([('low', 0), ('medium', 1), ('high', 2)])
return d.get(s, 0) # 有s,就返回其value,否则返回默认0
if __name__ == '__main__':
f6(sl=True, le=True, npr=False, amh=False, wacc=True, pla=False)
satisfaction_level last_evaluation number_project \
0 0.38 0.53 2
1 0.80 0.86 5
2 0.11 0.88 7
3 0.72 0.87 5
4 0.37 0.52 2
... ... ... ...
14994 0.40 0.57 2
14995 0.37 0.48 2
14996 0.37 0.53 2
14997 0.11 0.96 6
14998 0.37 0.52 2
average_montly_hours time_spend_company Work_accident left \
0 157 3 0 1
1 262 6 0 1
2 272 4 0 1
3 223 5 0 1
4 159 3 0 1
... ... ... ... ...
14994 151 3 0 1
14995 160 3 0 1
14996 143 3 0 1
14997 280 4 0 1
14998 158 3 0 1
promotion_last_5years department salary
0 0 sales low
1 0 sales medium
2 0 sales medium
3 0 sales low
4 0 sales low
... ... ... ...
14994 0 support low
14995 0 support low
14996 0 support low
14997 0 support low
14998 0 support low
[14999 rows x 10 columns]
satisfaction_level last_evaluation number_project \
0 -0.936495 -1.087275 0.0
1 0.752814 0.840707 0.6
2 -2.022479 0.957554 1.0
3 0.431041 0.899131 0.6
4 -0.976716 -1.145699 0.0
... ... ... ...
14994 -0.856051 -0.853580 0.0
14995 -0.976716 -1.379394 0.0
14996 -0.976716 -1.087275 0.0
14997 -2.022479 1.424944 0.8
14998 -0.976716 -1.145699 0.0
average_montly_hours time_spend_company Work_accident \
0 0.285047 0.125 -0.411165
1 0.775701 0.500 -0.411165
2 0.822430 0.250 -0.411165
3 0.593458 0.375 -0.411165
4 0.294393 0.125 -0.411165
... ... ... ...
14994 0.257009 0.125 -0.411165
14995 0.299065 0.125 -0.411165
14996 0.219626 0.125 -0.411165
14997 0.859813 0.250 -0.411165
14998 0.289720 0.125 -0.411165
promotion_last_5years department salary
0 0.0 7 0
1 0.0 7 1
2 0.0 7 1
3 0.0 7 0
4 0.0 7 0
... ... ... ...
14994 0.0 8 0
14995 0.0 8 0
14996 0.0 8 0
14997 0.0 8 0
14998 0.0 8 0
[14999 rows x 9 columns]
Process finished with exit code 0
你看类别文字就编码好了
OK
反过来呢
if __name__ == '__main__':
f6(sl=True, le=True, npr=False, amh=False, wacc=True, pla=False, dep=True, sal=True)
satisfaction_level last_evaluation number_project \
0 0.38 0.53 2
1 0.80 0.86 5
2 0.11 0.88 7
3 0.72 0.87 5
4 0.37 0.52 2
... ... ... ...
14994 0.40 0.57 2
14995 0.37 0.48 2
14996 0.37 0.53 2
14997 0.11 0.96 6
14998 0.37 0.52 2
average_montly_hours time_spend_company Work_accident left \
0 157 3 0 1
1 262 6 0 1
2 272 4 0 1
3 223 5 0 1
4 159 3 0 1
... ... ... ... ...
14994 151 3 0 1
14995 160 3 0 1
14996 143 3 0 1
14997 280 4 0 1
14998 158 3 0 1
promotion_last_5years department salary
0 0 sales low
1 0 sales medium
2 0 sales medium
3 0 sales low
4 0 sales low
... ... ... ...
14994 0 support low
14995 0 support low
14996 0 support low
14997 0 support low
14998 0 support low
[14999 rows x 10 columns]
satisfaction_level last_evaluation number_project \
0 -0.936495 -1.087275 0.0
1 0.752814 0.840707 0.6
2 -2.022479 0.957554 1.0
3 0.431041 0.899131 0.6
4 -0.976716 -1.145699 0.0
... ... ... ...
14994 -0.856051 -0.853580 0.0
14995 -0.976716 -1.379394 0.0
14996 -0.976716 -1.087275 0.0
14997 -2.022479 1.424944 0.8
14998 -0.976716 -1.145699 0.0
average_montly_hours time_spend_company Work_accident \
0 0.285047 0.125 -0.411165
1 0.775701 0.500 -0.411165
2 0.822430 0.250 -0.411165
3 0.593458 0.375 -0.411165
4 0.294393 0.125 -0.411165
... ... ... ...
14994 0.257009 0.125 -0.411165
14995 0.299065 0.125 -0.411165
14996 0.219626 0.125 -0.411165
14997 0.859813 0.250 -0.411165
14998 0.289720 0.125 -0.411165
promotion_last_5years department_IT department_RandD \
0 0.0 0 0
1 0.0 0 0
2 0.0 0 0
3 0.0 0 0
4 0.0 0 0
... ... ... ...
14994 0.0 0 0
14995 0.0 0 0
14996 0.0 0 0
14997 0.0 0 0
14998 0.0 0 0
department_accounting department_hr department_management \
0 0 0 0
1 0 0 0
2 0 0 0
3 0 0 0
4 0 0 0
... ... ... ...
14994 0 0 0
14995 0 0 0
14996 0 0 0
14997 0 0 0
14998 0 0 0
department_marketing department_product_mng department_sales \
0 0 0 1
1 0 0 1
2 0 0 1
3 0 0 1
4 0 0 1
... ... ... ...
14994 0 0 0
14995 0 0 0
14996 0 0 0
14997 0 0 0
14998 0 0 0
department_support department_technical salary_high salary_low \
0 0 0 0 1
1 0 0 0 0
2 0 0 0 0
3 0 0 0 1
4 0 0 0 1
... ... ... ... ...
14994 1 0 0 1
14995 1 0 0 1
14996 1 0 0 1
14997 1 0 0 1
14998 1 0 0 1
salary_medium
0 0
1 1
2 1
3 0
4 0
... ...
14994 0
14995 0
14996 0
14997 0
14998 0
[14999 rows x 20 columns]
Process finished with exit code 0
你瞅瞅,衍生出了很多属性哦
相当于搞了一个向量
懂?
稀疏化了
这种方式一般般的,后面都是embedding了
pd.set_option('display.max_columns', None) # 展示所有列
def f6(sl=False, le=False, npr=False, amh=False, tsc=False,
wacc=False, pla=False, dep=False, sal=False,
lower_d=False, ld_n=1):
# 处理HR表
df = pd.read_csv('../HR_comma_sep.csv')
print(df)
# 标注label就是离职率left
label = df['left']
df = df.drop('left', axis=1) # 删除left列,而不是行哦
# 清洗数据,除去异常值,抽样啥的
df = df.dropna(subset=['satisfaction_level', 'last_evaluation'])
df = df[df['satisfaction_level']<=1][df['salary']!='nme']
# 特征选择,之前我们见过,left与last_evaluetion,number_projection,是无关的
# 特征处理
# satisfaction_level处于0--1之间,这个可以保留不动,可以缩放到--1,可以标准化
# sl为True时,minmax化,False时,standard 处理
scalar_list = [sl, le, npr, amh, tsc, wacc, pla]
column_list = ['satisfaction_level', 'last_evaluation', 'number_project', 'average_montly_hours',
'time_spend_company', 'Work_accident', 'promotion_last_5years']
for i in range(len(scalar_list)):
if not scalar_list[i]:
df[column_list[i]] = MinMaxScaler().fit_transform(df[column_list[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
# 转换列--行,取0行
else:
df[column_list[i]] = StandardScaler().fit_transform(df[column_list[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
# 转换
# last_evaluation和satisfaction类似,le为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# number_project不大于10,npr为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# time_spend_company不大于10,tsc为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# average_montly_hours范围很大,我们最好将其离散化,由于数据不大,最好保留
# 当然也能处理,average_montly_hours,amh为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# Work_accident和promotion_last_5years是0-1的
# Work_accident不大于10,wacc为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# promotion_last_5years不大于10,pla为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# department,将其数值化,dep,True:LabelEncoding,False:OneHotEncoding
# salary,将其数值化,sal,True:LabelEncoding,False:OneHotEncoding
scalar_list = [dep, sal]
column_list = ['department', 'salary']
for i in range(len(scalar_list)):
if not scalar_list[i]:
#建议salary是按照0 1 2低中去编码
if column_list[i] == "salary":
df[column_list[i]] = [map_salary(s) for s in df['salary'].values] # 字段所有行都去遍历处理
else:
df[column_list[i]] = LabelEncoder().fit_transform(df[column_list[i]]) # department是按照字母排序编码
else:
df = pd.get_dummies(df, columns=[column_list[i]]) # 这是onehot编码
# lower_d降维?
if lower_d:
df = PCA(n_components=ld_n).fit_transform(df.values) # 对整个表降维
print(df)
def map_salary(s):
d = dict([('low', 0), ('medium', 1), ('high', 2)])
return d.get(s, 0) # 有s,就返回其value,否则返回默认0
if __name__ == '__main__':
f6(sl=True, le=True, npr=False, amh=False, wacc=True, pla=False, dep=True, sal=True,
lower_d=True, ld_n=3)
satisfaction_level last_evaluation number_project \
0 0.38 0.53 2
1 0.80 0.86 5
2 0.11 0.88 7
3 0.72 0.87 5
4 0.37 0.52 2
... ... ... ...
14994 0.40 0.57 2
14995 0.37 0.48 2
14996 0.37 0.53 2
14997 0.11 0.96 6
14998 0.37 0.52 2
average_montly_hours time_spend_company Work_accident left \
0 157 3 0 1
1 262 6 0 1
2 272 4 0 1
3 223 5 0 1
4 159 3 0 1
... ... ... ... ...
14994 151 3 0 1
14995 160 3 0 1
14996 143 3 0 1
14997 280 4 0 1
14998 158 3 0 1
promotion_last_5years department salary
0 0 sales low
1 0 sales medium
2 0 sales medium
3 0 sales low
4 0 sales low
... ... ... ...
14994 0 support low
14995 0 support low
14996 0 support low
14997 0 support low
14998 0 support low
[14999 rows x 10 columns]
[[-1.52711959 0.13000352 -0.15611432]
[ 0.98061312 -0.72450564 -0.21259596]
[-0.87721205 -1.04746416 1.83619143]
...
[-1.54345458 0.12593844 -0.11512819]
[-0.61050862 -1.28738167 2.16083294]
[-1.57784711 0.15182675 -0.1441186 ]]
Process finished with exit code 0
这就是降维到3维的结果
怎么样,这种美滋滋不
pd.set_option('display.max_columns', None) # 展示所有列
def f6(sl=False, le=False, npr=False, amh=False, tsc=False,
wacc=False, pla=False, dep=False, sal=False,
lower_d=False, ld_n=1):
# 处理HR表
df = pd.read_csv('../HR_comma_sep.csv')
print(df)
# 清洗数据,除去异常值,抽样啥的
df = df.dropna(subset=['satisfaction_level', 'last_evaluation'])
df = df[df['satisfaction_level']<=1][df['salary']!='nme']
# 标注label就是离职率left——顺序放后面哦
label = df['left']
df = df.drop('left', axis=1) # 删除left列,而不是行哦
# 特征选择,之前我们见过,left与last_evaluetion,number_projection,是无关的
# 特征处理
# satisfaction_level处于0--1之间,这个可以保留不动,可以缩放到--1,可以标准化
# sl为True时,minmax化,False时,standard 处理
scalar_list = [sl, le, npr, amh, tsc, wacc, pla]
column_list = ['satisfaction_level', 'last_evaluation', 'number_project', 'average_montly_hours',
'time_spend_company', 'Work_accident', 'promotion_last_5years']
for i in range(len(scalar_list)):
if not scalar_list[i]:
df[column_list[i]] = MinMaxScaler().fit_transform(df[column_list[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
# 转换列--行,取0行
else:
df[column_list[i]] = StandardScaler().fit_transform(df[column_list[i]].values.reshape(-1, 1)).reshape(1, -1)[0]
# 转换
# last_evaluation和satisfaction类似,le为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# number_project不大于10,npr为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# time_spend_company不大于10,tsc为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# average_montly_hours范围很大,我们最好将其离散化,由于数据不大,最好保留
# 当然也能处理,average_montly_hours,amh为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# Work_accident和promotion_last_5years是0-1的
# Work_accident不大于10,wacc为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# promotion_last_5years不大于10,pla为True时,minmax化,False时,standard 处理,自hi今儿上面列表里面加入即可
# department,将其数值化,dep,True:LabelEncoding,False:OneHotEncoding
# salary,将其数值化,sal,True:LabelEncoding,False:OneHotEncoding
scalar_list = [dep, sal]
column_list = ['department', 'salary']
for i in range(len(scalar_list)):
if not scalar_list[i]:
#建议salary是按照0 1 2低中去编码
if column_list[i] == "salary":
df[column_list[i]] = [map_salary(s) for s in df['salary'].values] # 字段所有行都去遍历处理
else:
df[column_list[i]] = LabelEncoder().fit_transform(df[column_list[i]]) # department是按照字母排序编码
else:
df = pd.get_dummies(df, columns=[column_list[i]]) # 这是onehot编码
# lower_d降维?
if lower_d:
df = PCA(n_components=ld_n).fit_transform(df.values) # 对整个表降维
return df, label
def map_salary(s):
d = dict([('low', 0), ('medium', 1), ('high', 2)])
return d.get(s, 0) # 有s,就返回其value,否则返回默认0
if __name__ == '__main__':
df, label = f6(sl=True, le=True, npr=False, amh=False, wacc=True, pla=False, dep=True, sal=True,
lower_d=True, ld_n=3)
print(df, label)
加上标签即可
特征工程的小结
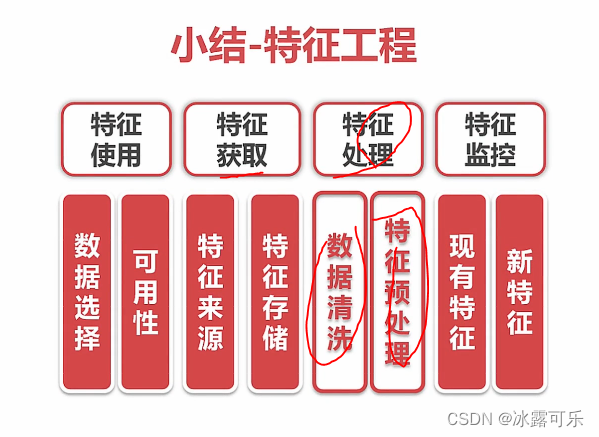


特征处理的方法很多,反正模型效果好,就选择这种方式即可
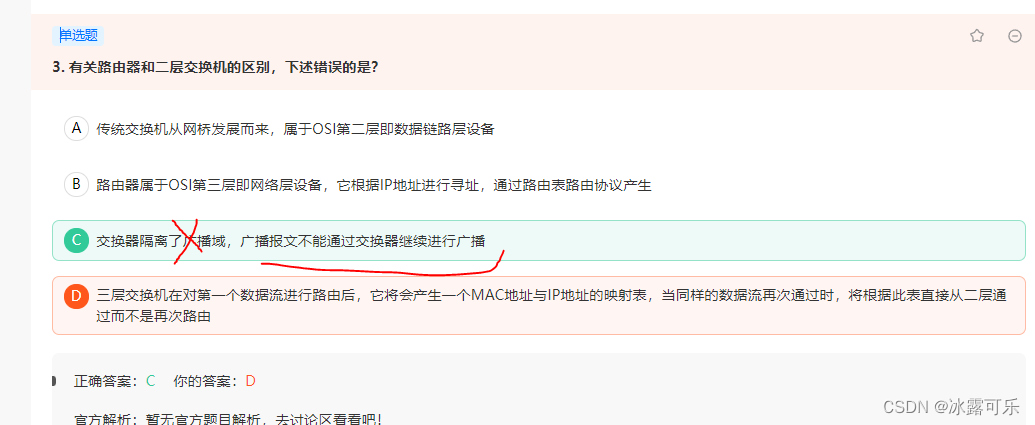
有关路由器和二层交换机的区别,下述错误的是?
工作在应用层的协议,才有源端口与目的端口之分,FTP是应用层协议

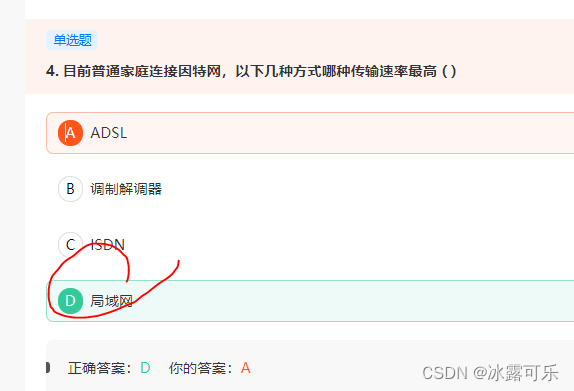
目前普通家庭连接因特网,以下几种方式哪种传输速率最高 ( )
下列哪些http方法对于服务端和用户端一定是安全的?()
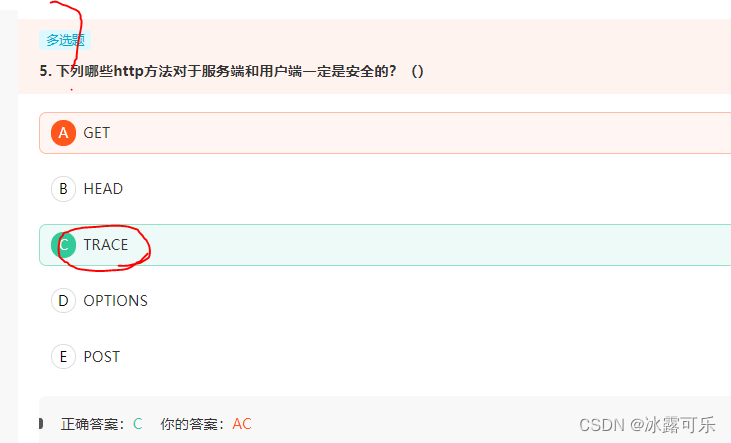
GET:通过请求URI得到资源,
POST:用于添加新的内容,
OPTIONS:询问可以执行哪些方法,
TRACE:用于远程 诊断服务器,
HEAD:类似于GET, 但是不返回body信息,用于检查对象是否存在,以及得到对象的元数据 HEAD,
GET,OPTIONS和TRACE视为安全的方法,因为它们只是从服务器获得资源而不对服务器做任何修改, 但是HEAD,GET,OPTIONS在用户端不安全。
而POST则影响服务器上的资源。
维度trace安全
……
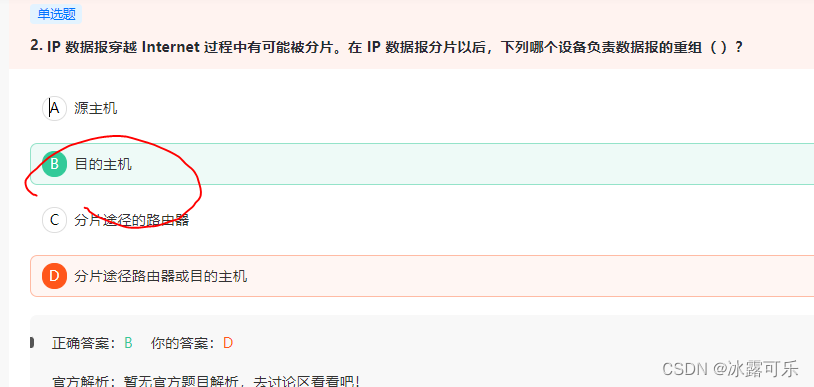
IP 数据报穿越 Internet 过程中有可能被分片。在 IP 数据报分片以后,下列哪个设备负责数据报的重组( )?
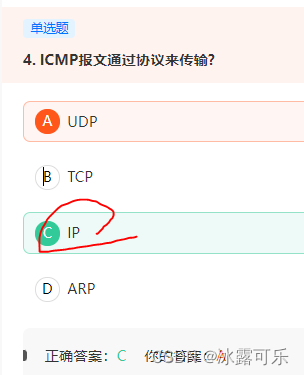
ICMP不是高层协议,而是IP层的协议,ICMP报文是装在IP数据报中,作为其中的数据部分
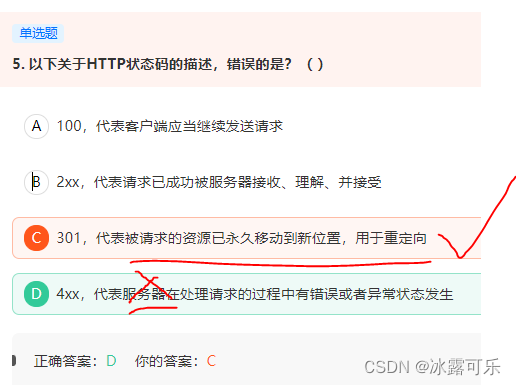
301,代表被请求的资源已永久移动到新位置,用于重定向
400-499 指定客服端错误 500-599 服务端错误
星形结构的网络采用的是广播式的传播方式。( )
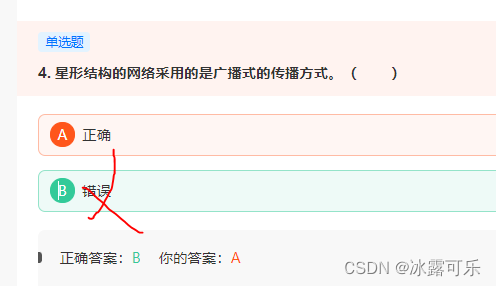
星型拓扑图:点到点式;
总线型:广播式;
环形式:点到点;
树形式:点到点;
网状:点到点和广播式
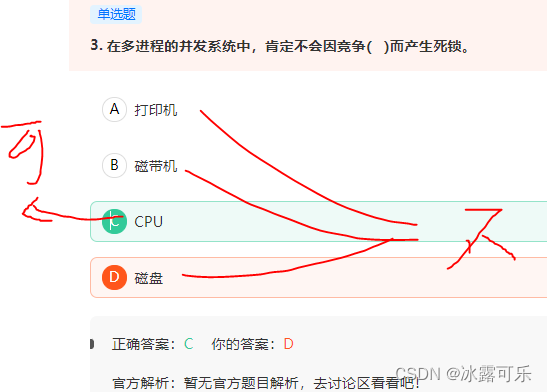
CPU,属于靠剥夺资源,因为CPU可以发生中断。中断,也就是资源的使用被打断了,也就是我们常说的可以被剥夺
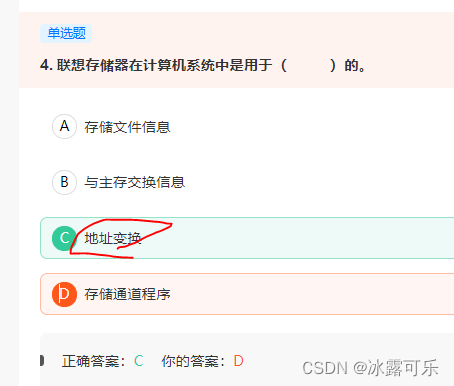
联想存储器在计算机系统中是用于( )的。
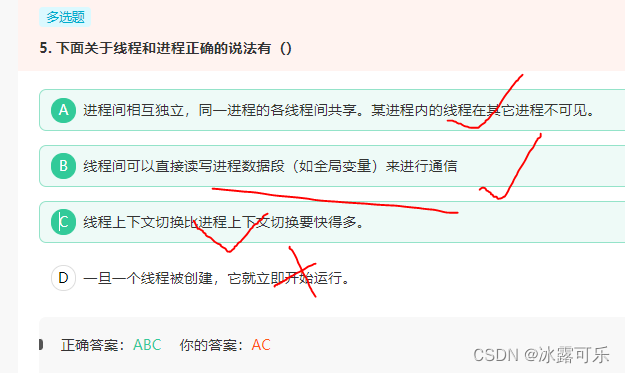
线程间可以直接读写进程数据段(如全局变量)来进行通信
总结
提示:重要经验:
1)
2)学好oracle,操作系统,计算机网络,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。















 614
614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











