










数据挖掘,计算机网络、操作系统刷题笔记52
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
考网警特招必然要考操作系统,计算机网络,由于备考时间不长,你可能需要速成,我就想办法自学速成了,课程太长没法玩
刷题系列文章
【1】Oracle数据库:刷题错题本,数据库的各种概念
【2】操作系统,计算机网络,数据库刷题笔记2
【3】数据库、计算机网络,操作系统刷题笔记3
【4】数据库、计算机网络,操作系统刷题笔记4
【5】数据库、计算机网络,操作系统刷题笔记5
【6】数据库、计算机网络,操作系统刷题笔记6
【7】数据库、计算机网络,操作系统刷题笔记7
【8】数据库、计算机网络,操作系统刷题笔记8
【9】操作系统,计算机网络,数据库刷题笔记9
【10】操作系统,计算机网络,数据库刷题笔记10
【11】操作系统,计算机网络,数据库刷题笔记11
【12】操作系统,计算机网络,数据库刷题笔记12
【13】操作系统,计算机网络,数据库刷题笔记13
【14】操作系统,计算机网络,数据库刷题笔记14
【15】计算机网络、操作系统刷题笔记15
【16】数据库,计算机网络、操作系统刷题笔记16
【17】数据库,计算机网络、操作系统刷题笔记17
【18】数据库,计算机网络、操作系统刷题笔记18
【19】数据库,计算机网络、操作系统刷题笔记19
【20】数据库,计算机网络、操作系统刷题笔记20
【21】数据库,计算机网络、操作系统刷题笔记21
【22】数据库,计算机网络、操作系统刷题笔记22
【23】数据库,计算机网络、操作系统刷题笔记23
【24】数据库,计算机网络、操作系统刷题笔记24
【25】数据库,计算机网络、操作系统刷题笔记25
【26】数据库,计算机网络、操作系统刷题笔记26
【27】数据库,计算机网络、操作系统刷题笔记27
【28】数据库,计算机网络、操作系统刷题笔记28
【29】数据库,计算机网络、操作系统刷题笔记29
【30】数据库,计算机网络、操作系统刷题笔记30
【31】数据库,计算机网络、操作系统刷题笔记31
【32】数据库,计算机网络、操作系统刷题笔记32
【33】数据库,计算机网络、操作系统刷题笔记33
【34】数据库,计算机网络、操作系统刷题笔记34
【35】数据挖掘,计算机网络、操作系统刷题笔记35
【36】数据挖掘,计算机网络、操作系统刷题笔记36
【37】数据挖掘,计算机网络、操作系统刷题笔记37
【38】数据挖掘,计算机网络、操作系统刷题笔记38
【39】数据挖掘,计算机网络、操作系统刷题笔记39
【40】数据挖掘,计算机网络、操作系统刷题笔记40
【41】数据挖掘,计算机网络、操作系统刷题笔记41
【42】数据挖掘,计算机网络、操作系统刷题笔记42
【43】数据挖掘,计算机网络、操作系统刷题笔记43
【44】数据挖掘,计算机网络、操作系统刷题笔记44
【45】数据挖掘,计算机网络、操作系统刷题笔记45
【46】数据挖掘,计算机网络、操作系统刷题笔记46
【47】数据挖掘,计算机网络、操作系统刷题笔记47
【48】数据挖掘,计算机网络、操作系统刷题笔记48
【49】数据挖掘,计算机网络、操作系统刷题笔记49
【50】数据挖掘,计算机网络、操作系统刷题笔记50
【51】数据挖掘,计算机网络、操作系统刷题笔记51
数据挖掘分析应用:回归树
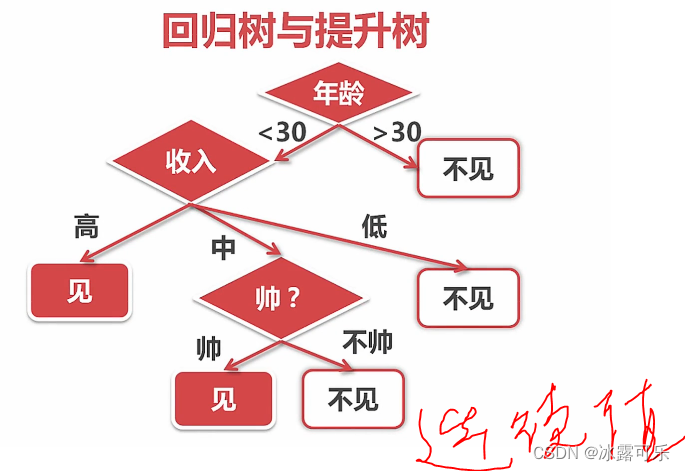
分类离散值
回归是连续值
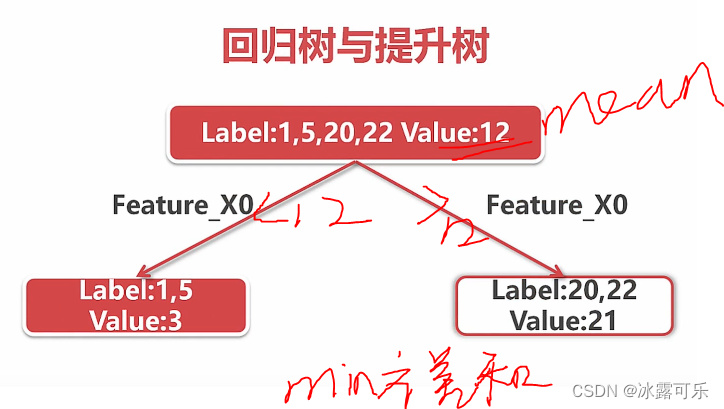
切分之后,俩方差和小
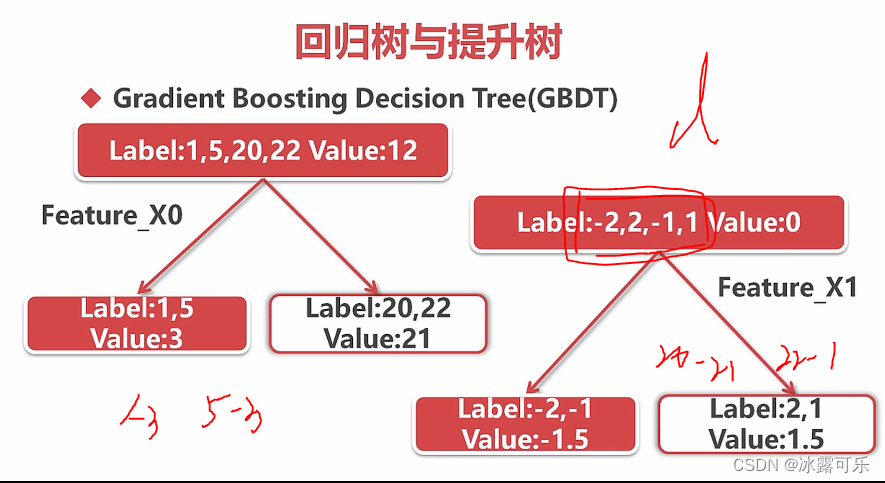


xgboost
高阶倒数也用
大规模并行运算
干

# 模型
def hr_modeling_all_saveDT_SVM_gbdt(features, label):
from sklearn.model_selection import train_test_split
# 切分函数
#DataFrame
feature_val = features.values
label_val = label
# 特征段
feature_name = features.columns
train_data, valid_data, y_train, y_valid = train_test_split(feature_val, label_val, test_size=0.2) # 20%验证集
train_data, test_data, y_train, y_test = train_test_split(train_data, y_train, test_size=0.25) # 25%测试集
print(len(train_data), len(valid_data), len(test_data))
# KNN分类
from sklearn.neighbors import NearestNeighbors, KNeighborsClassifier
from sklearn.metrics import accuracy_score, recall_score, f1_score # 模型评价
from sklearn.naive_bayes import GaussianNB, BernoulliNB # 高斯,伯努利,都是对特征有严格要求,离散值最好
from sklearn.tree import DecisionTreeClassifier, export_graphviz # 决策树
from io import StringIO
import pydotplus
import os
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier # 随机森林
from sklearn.ensemble import AdaBoostClassifier
from sklearn.linear_model import LogisticRegression
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from tensorflow.keras.optimizers import SGD
from sklearn.ensemble import GradientBoostingClassifier
os.environ["PATH"] += os.pathsep+r'D:\Program Files\Graphviz\bin'
models = [] # 申请模型,挨个验证好坏
knn_clf = KNeighborsClassifier(n_neighbors=3) # 5类
bys_clf = GaussianNB()
bnl_clf = BernoulliNB()
DT_clf = DecisionTreeClassifier()
SVC_clf = SVC()
rdn_clf = RandomForestClassifier()
adaboost_clf = AdaBoostClassifier(n_estimators=100)
logi_clf = LogisticRegression(C=1000, tol=1e-10, solver="sag", max_iter=10000)
gbdt_clf = GradientBoostingClassifier(max_depth=6, n_estimators=100) # 经验值,100颗树
# models.append(("KNN", knn_clf)) # 代码一个个模型测--放入的是元祖
# models.append(("GaussianNB", bys_clf)) # 代码一个个模型测--放入的是元祖
# models.append(("BernoulliNB", bnl_clf)) # 代码一个个模型测--放入的是元祖
# models.append(("Decision Tree", DT_clf)) # 代码一个个模型测--放入的是元祖
# models.append(("SVM classifier", SVC_clf)) # 代码一个个模型测--放入的是元祖
models.append(("Random classifier", rdn_clf)) # 代码一个个模型测--放入的是元祖
# models.append(("adaboost classifier", adaboost_clf)) # 代码一个个模型测--放入的是元祖
# models.append(("logistic classifier", logi_clf)) # 代码一个个模型测--放入的是元祖
models.append(("gbdt_clf classifier", gbdt_clf)) # 代码一个个模型测--放入的是元祖
# 不同的模型,依次验证
for modelName, model in models:
print(modelName)
model.fit(train_data, y_train) # 指定训练集
# 又集成化数据集
data = [(train_data, y_train), (valid_data, y_valid), (test_data, y_test)]
for i in range(len(data)):
print(i)
y_input = data[i][0]
y_label = data[i][1] # 输入输出预测
y_pred = model.predict(y_input)
print("acc:", accuracy_score(y_label, y_pred))
print("recall:", recall_score(y_label, y_pred))
print("F1:", f1_score(y_label, y_pred))
print("\n")
# 不考虑存储,你看看这个模型就会输出仨结果
if __name__ == '__main__':
features, label = pre_processing(sl=True, le=True, npr=True, amh=True, wacc=True, pla=True, dep=False, sal=True,
lower_d=False, ld_n=3)
# print(features, label)
# 灌入模型
# hr_modeling_all_saveDT_SVM(features, label)
hr_modeling_all_saveDT_SVM_gbdt(features, label)
# 回归分析
# regrfunc(features, label)
8999 3000 3000
Random classifier
0
acc: 1.0
recall: 1.0
F1: 1.0
1
acc: 0.9893333333333333
recall: 0.9621109607577808
F1: 0.9779917469050894
2
acc: 0.989
recall: 0.9607046070460704
F1: 0.9772570640937284
gbdt_clf classifier
0
acc: 0.993888209801089
recall: 0.9765998089780324
F1: 0.9867310012062727
1
acc: 0.987
recall: 0.9607577807848444
F1: 0.9732693625771077
2
acc: 0.983
recall: 0.9498644986449865
F1: 0.9649002064693738
Process finished with exit code 0
gbdt很强了
屌爆了
特征越多,效果越好,美滋滋
非监督学习:聚类
无监督学习是没有标注的
目的就是试图给数据加标注
类内间距近
类间间距宽
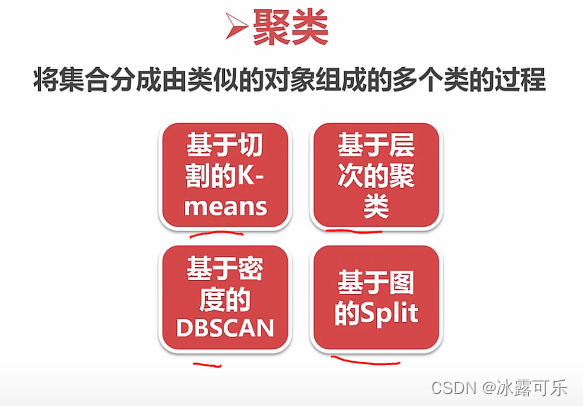
kmeans聚类算法
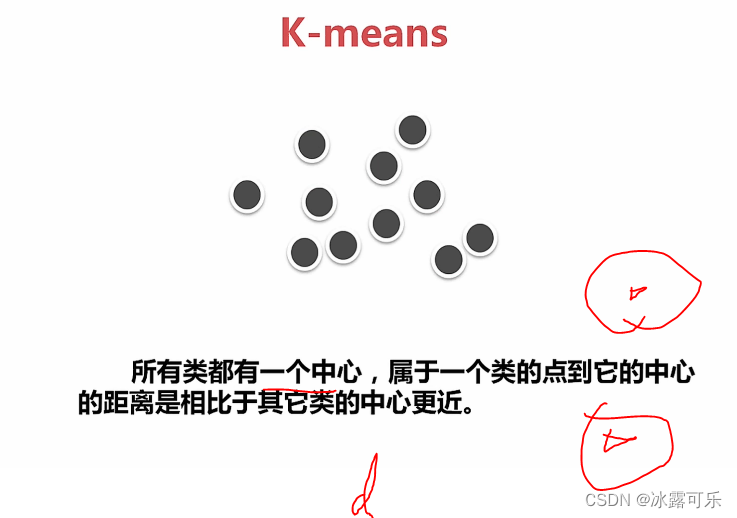
初始化质心,随机k个
归类
再计算质心
重新归类,重新计算质心

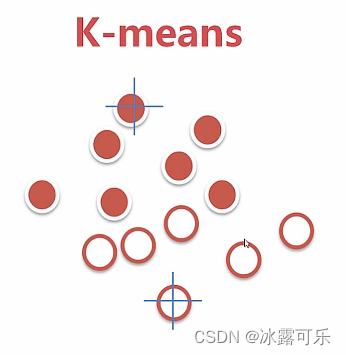
更新质心
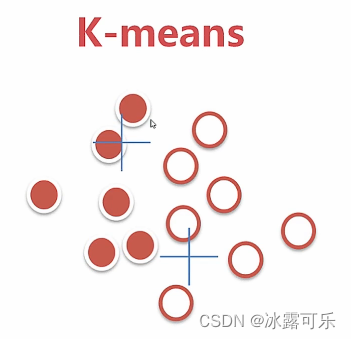
再继续更新质心
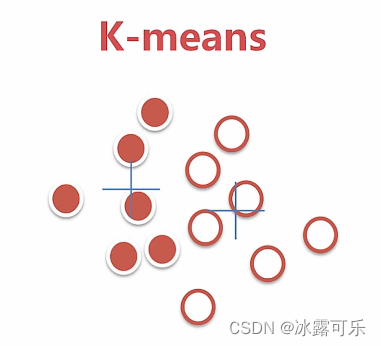
最终稳定,搞定


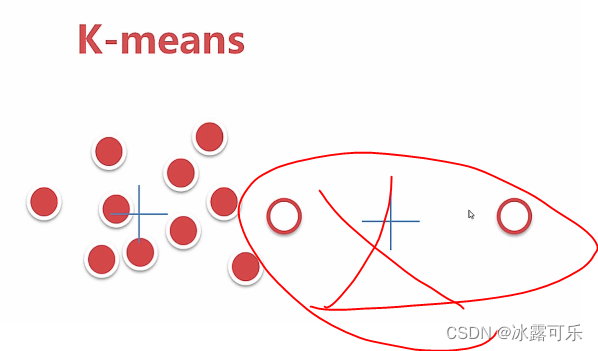
最好干掉异常值

这样容忍了异常值
k咋搞呢?
手肘法

import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles, make_blobs, make_moons
def kmeans():
n_samples = 1000 # 生成样本的个数
circles = make_circles(n_samples=n_samples, factor=0.5, noise=0.05) # factor一会看
moons = make_moons(n_samples=n_samples, noise=0.05)
blobs = make_blobs(n_samples=n_samples, random_state=8) # 避免位置变化
random_data = np.random.rand(n_samples, 2), None # 标注不使用
print(circles) # 样本点和标注,标注不需要
if __name__ == '__main__':
kmeans()
(array([[-0.43010488, -0.07524356],
[ 0.86393561, 0.13582871],
[ 0.06323255, -0.58554023],
...,
[-0.13980991, -0.39024888],
[ 0.52068248, -0.07947136],
[-0.22528083, 0.41497786]]), array([1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0,
0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1,
0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1,
0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0,
0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0,
0, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0,
0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 1,
0, 1, 1, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1,
1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1,
1, 1, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 1, 0,
0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1,
1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1,
0, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0,
0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0,
1, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0,
0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1,
0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0,
1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1, 1,
0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1,
0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 1, 0, 1,
0, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0,
1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1,
0, 1, 1, 1, 1, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1,
1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 0,
1, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0,
1, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 1, 1,
0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0,
0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1,
1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0,
1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1,
0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 0, 0, 0,
0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1,
1, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0,
1, 1, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0,
1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0,
0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0,
1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 1, 0, 1, 0, 1,
1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0,
1, 1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0,
0, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0,
1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0,
1, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 1,
1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 1, 0, 1, 1,
1, 0, 0, 0, 1, 1, 0, 1, 1, 1], dtype=int64))
Process finished with exit code 0
指定颜色
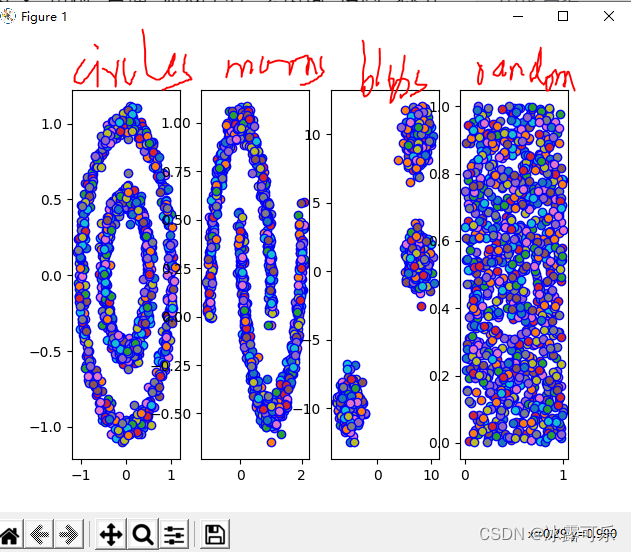
这样的话,模型聚类先不说
只看数据的话,就长这样
代码聚类
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles, make_blobs, make_moons
from sklearn.cluster import KMeans
def kmeans():
n_samples = 1000 # 生成样本的个数
circles = make_circles(n_samples=n_samples, factor=0.5, noise=0.05) # factor俩圆之间的间距
moons = make_moons(n_samples=n_samples, noise=0.05)
blobs = make_blobs(n_samples=n_samples, random_state=8) # 避免位置变化
random_data = np.random.rand(n_samples, 2), None # 标注不使用
# print(circles) # 样本点和标注,标注不需要
colors = "bgrcmyk"
data = [circles, moons, blobs, random_data] # 四个数据集
# 模型——随意添加
models = [("None", None), ("Kmeans", KMeans(n_clusters=2))]
# n分2类
f = plt.figure() # 给不同模型下,不同数据集的聚类情况画图
for index, clt in enumerate(models):
clt_name, clt_entity = clt # 前面是名字,后面是模型的实体
for i, dataset in enumerate(data):
X, Y = dataset # 生成好的数据集,后面标注不用
if not clt_entity:
clt_res = [0 for item in range(len(X))] # 数据中第一部分的维度
else:
# 有实体——拿着模型聚类去
clt_entity.fit(X) # 拟合
clt_res = clt_entity.labels_.astype(np.int) # 聚类之后,有自己的标签哦,拿出去展示,不同色
# 然后拿着结果作图去
f.add_subplot(len(models), len(data), index*len(data)+i+1) # 不同模型,多个数据
[plt.scatter(X[p, 0], X[p, 1], edgecolors=colors[clt_res[p]]) for p in range(len(X))]
# 每个数据都画出来
plt.show()
if __name__ == '__main__':
kmeans()
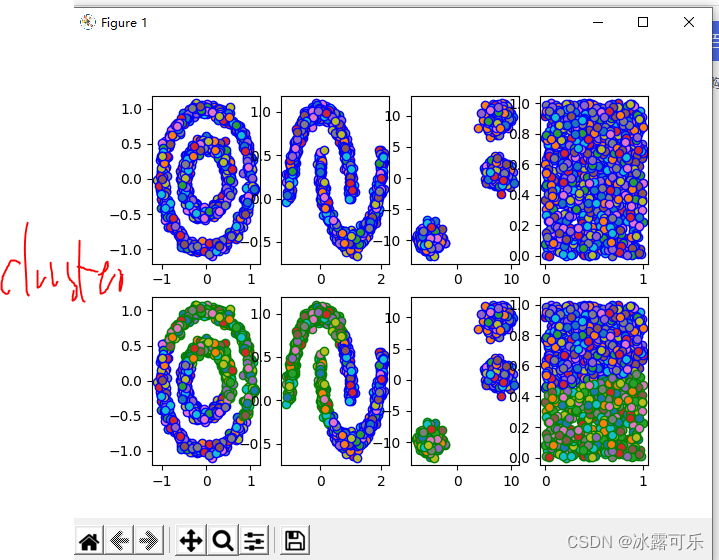
如果质心随机,结果可能不同哦
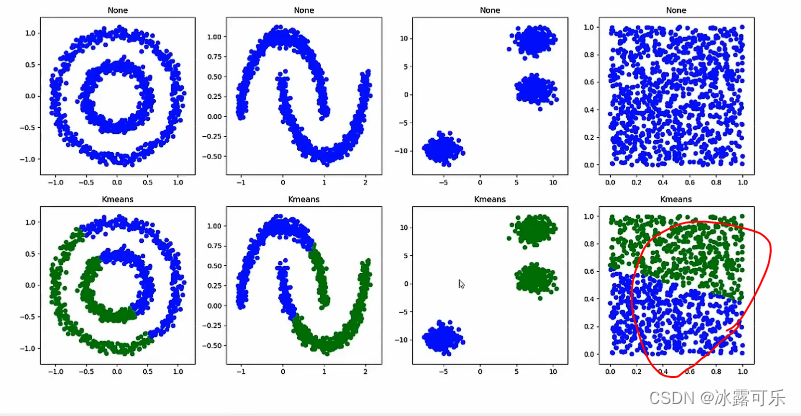
kmeans就是把最近的俩团当做一个类
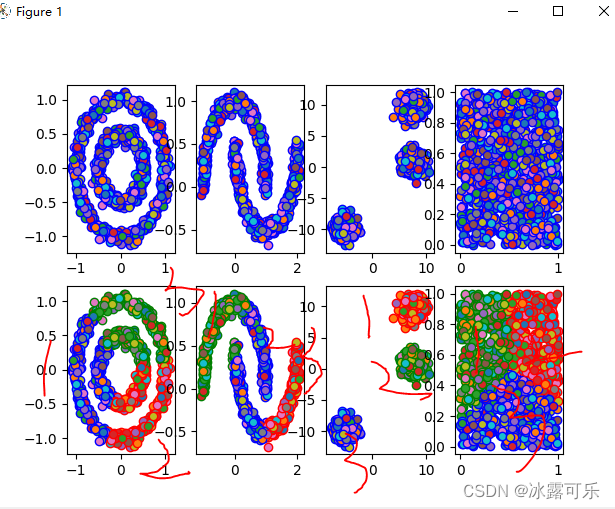
如果聚类成3类,那就不一样了
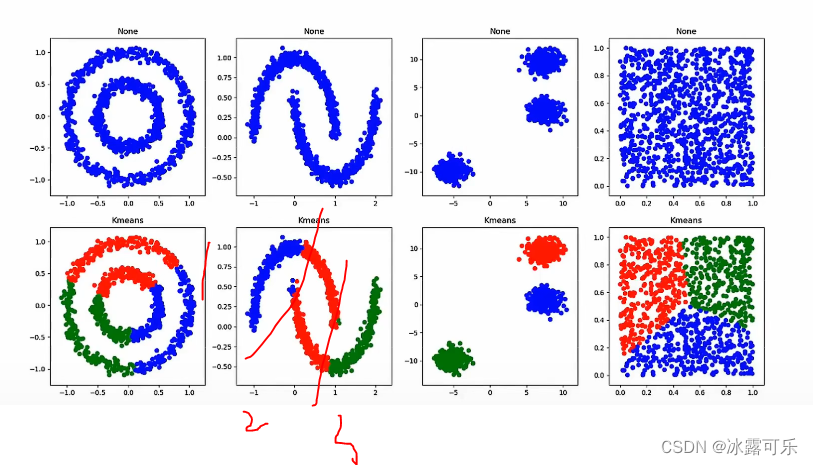
官网有很多数据集
反正不少
kmeans的模型也可以去了解一下
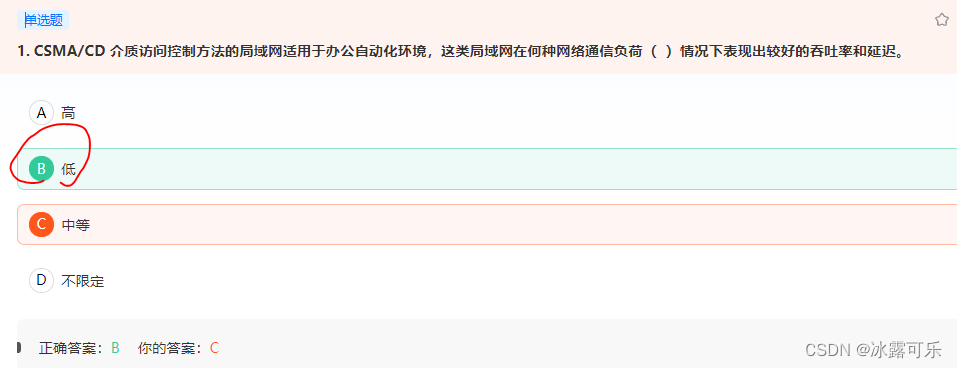
CSMA/CD 介质访问控制方法的局域网适用于办公自动化环境,这类局域网在何种网络通信负荷( )情况下表现出较好的吞吐率和延迟。
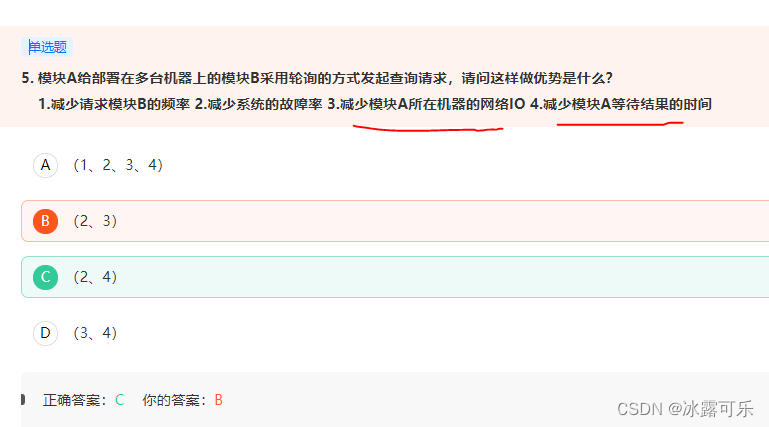
模块A给部署在多台机器上的模块B采用轮询的方式发起查询请求,请问这样做优势是什么?
IO是不可能减少的
总结
提示:重要经验:
1)
2)学好oracle,操作系统,计算机网络,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。















 614
614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











