







NumPy的应用(四)
向量
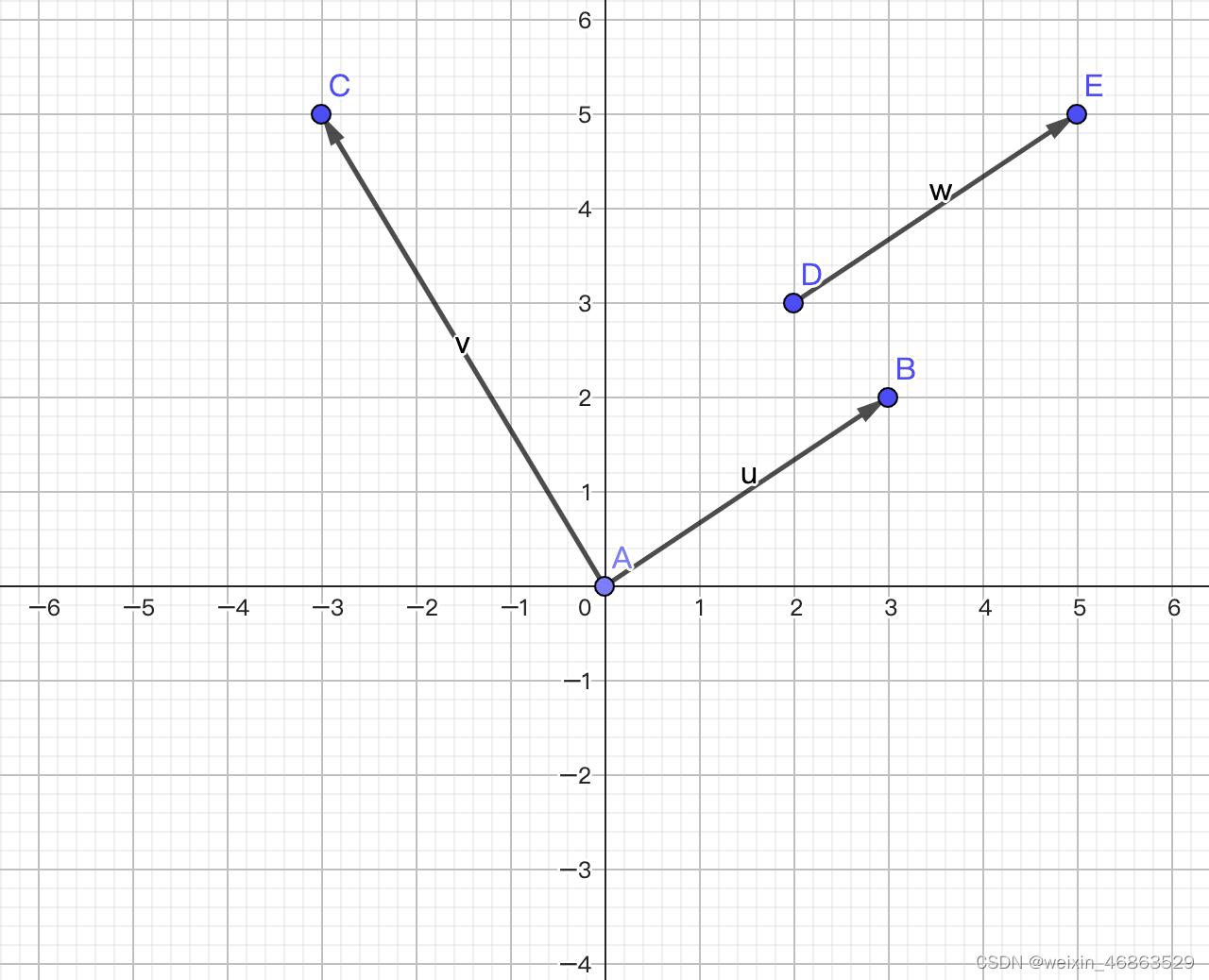
向量(vector)也叫矢量,是一个同时具有大小和方向,且满足平行四边形法则的几何对象。与向量相对的概念叫标量或数量,标量只有大小,绝大多数情况下没有方向。我们通常用带箭头的线段来表示向量,在平面直角坐标系中的向量如下图所示。需要注意的是,向量是表达大小和方向的量,并没有规定起点和终点,所以相同的向量可以画在任意位置,例如下图中 w \boldsymbol{w} w和 v \boldsymbol{v} v两个向量并没有什么区别。
向量有很多种代数表示法,对于二维空间的向量,下面几种写法都是可以的。
a
=
⟨
a
1
,
a
2
⟩
=
(
a
1
,
a
2
)
=
(
a
1
a
2
)
=
[
a
1
a
2
]
\boldsymbol{a} = \langle a_1, a_2 \rangle = (a_1, a_2) = \begin{pmatrix} a_1 \\ a_2 \end{pmatrix} = \begin{bmatrix} a_1 \\ a_2 \end{bmatrix}
a=⟨a1,a2⟩=(a1,a2)=(a1a2)=[a1a2]
向量的大小称为向量的模,它是一个标量,对于二维空间的向量,模可以通过下面的公式计算。
∣
a
∣
=
a
1
2
+
a
2
2
\lvert \boldsymbol{a} \rvert = \sqrt{a_{1}^{2} + a_{2}^{2}}
∣a∣=a12+a22
注意,这里的
∣
a
∣
\lvert \boldsymbol{a} \rvert
∣a∣并不是绝对值,你可以将其称为向量
a
\boldsymbol{a}
a的二范数,这是数学中的符号重用现象。上面的写法和概念也可以推广到
n
n
n维空间,我们通常用
R
n
\boldsymbol{R^n}
Rn表示
n
n
n维空间,我们刚才说的二维空间可以记为
R
2
\boldsymbol{R^2}
R2,三维空间可以记为
R
3
\boldsymbol{R^3}
R3。虽然生活在三维空间的我们很难想象四维空间、五维空间是什么样子,但是这并不影响我们探讨高维空间,机器学习中,我们经常把有
n
n
n个特征的训练样本称为一个
n
n
n维向量。
向量的加法
相同维度的向量可以相加得到一个新的向量,运算的方法是将向量的每个分量相加,如下所示。
u
=
[
u
1
u
2
⋮
u
n
]
,
v
=
[
v
1
v
2
⋮
v
n
]
,
u
+
v
=
[
u
1
+
v
1
u
2
+
v
2
⋮
u
n
+
v
n
]
\boldsymbol{u} = \begin{bmatrix} u_1 \\ u_2 \\ \vdots \\ u_n \end{bmatrix}, \quad \boldsymbol{v} = \begin{bmatrix} v_1 \\ v_2 \\ \vdots \\ v_n \end{bmatrix}, \quad \boldsymbol{u} + \boldsymbol{v} = \begin{bmatrix} u_1 + v_1 \\ u_2 + v_2 \\ \vdots \\ u_n + v_n \end{bmatrix}
u=
u1u2⋮un
,v=
v1v2⋮vn
,u+v=
u1+v1u2+v2⋮un+vn
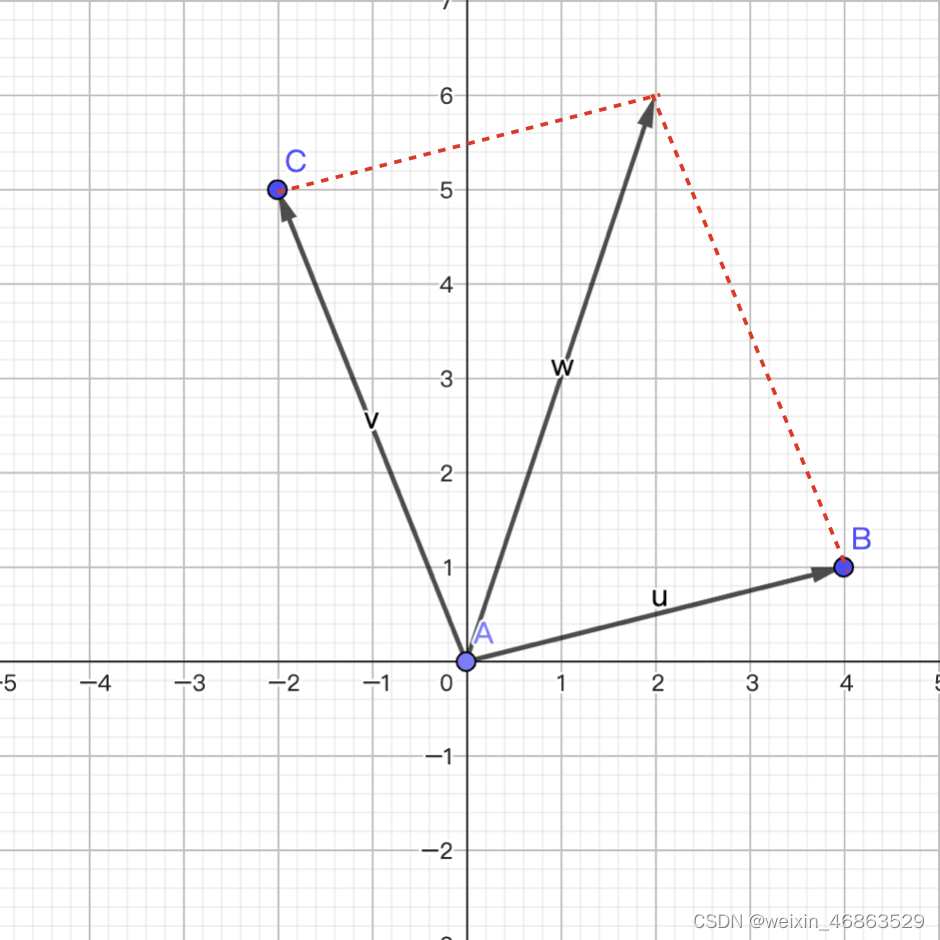
向量的加法满足“平行四边形法则”,即两个向量
u
\boldsymbol{u}
u和
v
\boldsymbol{v}
v构成了平行四边形的两条邻边,相加的结果是平行四边形的对角线,如下图所示。
向量的数乘
一个向量
v
\boldsymbol{v}
v可以和一个标量
k
k
k相乘,运算的方法是将向量中的每个分量与该标量相乘即可,如下所示。
v
=
[
v
1
v
2
⋮
v
n
]
,
k
⋅
v
=
[
k
⋅
v
1
k
⋅
v
2
⋮
k
⋅
v
n
]
\boldsymbol{v} = \begin{bmatrix} v_1 \\ v_2 \\ \vdots \\ v_n \end{bmatrix}, \quad k \cdot \boldsymbol{v} = \begin{bmatrix} k \cdot v_1 \\ k \cdot v_2 \\ \vdots \\ k \cdot v_n \end{bmatrix}
v=
v1v2⋮vn
,k⋅v=
k⋅v1k⋅v2⋮k⋅vn
我们可以用 NumPy 的数组来表示向量,向量的加法可以通过两个数组的加法来实现,向量的数乘可以通过数组和标量的乘法来实现,此处不再进行赘述。
向量的点积
点积(dot product)是两个向量之间最为重要的运算之一,运算的方法是将两个向量对应分量的乘积求和,所以点积的结果是一个标量,其几何意义是两个向量的模乘以二者夹角的余弦如下所示。
u
=
[
u
1
u
2
⋮
u
n
]
,
v
=
[
v
1
v
2
⋮
v
n
]
u
⋅
v
=
∑
i
=
1
n
u
i
v
i
=
∣
u
∣
∣
v
∣
c
o
s
θ
\boldsymbol{u} = \begin{bmatrix} u_1 \\ u_2 \\ \vdots \\ u_n \end{bmatrix}, \quad \boldsymbol{v} = \begin{bmatrix} v_1 \\ v_2 \\ \vdots \\ v_n \end{bmatrix} \quad \\ \boldsymbol{u} \cdot \boldsymbol{v} = \sum_{i=1}^{n}{u_iv_i} = \lvert \boldsymbol{u} \rvert \lvert \boldsymbol{v} \rvert cos\theta
u=
u1u2⋮un
,v=
v1v2⋮vn
u⋅v=i=1∑nuivi=∣u∣∣v∣cosθ
假如我们用3维向量来表示用户对喜剧片、言情片和动作片这三类电影的偏好,我们用1到5的数字来表示喜欢的程度,其中5表示非常喜欢,4表示比较喜欢,3表示无感,2表示比较反感,1表示特别反感。那么,下面的向量表示用户非常喜欢喜剧片,特别反感言情片,对动作片不喜欢也不反感。
u
=
(
5
1
3
)
\boldsymbol{u} = \begin{pmatrix} 5 \\ 1 \\ 3 \end{pmatrix}
u=
513
现在有两部电影上映了,一部属于言情喜剧片,一部属于喜剧动作片,我们把两部电影也通过3维向量的方式进行表示,如下所示。
m
1
=
(
4
5
1
)
,
m
2
=
(
5
1
5
)
\boldsymbol{m_1} = \begin{pmatrix} 4 \\ 5 \\ 1 \end{pmatrix}, \quad \boldsymbol{m_2} = \begin{pmatrix} 5 \\ 1 \\ 5 \end{pmatrix}
m1=
451
,m2=
515
如果现在我们需要向刚才的用户推荐一部电影,我们应该给他推荐哪一部呢?我们可以将代表用户的向量
u
\boldsymbol{u}
u和代表电影的向量
m
1
\boldsymbol{m_1}
m1和
m
2
\boldsymbol{m_2}
m2分别进行点积运算,再除以向量的模长,得到向量夹角的余弦值,余弦值越接近1,说明向量的夹角越接近0度,也就是两个向量的相似度越高。很显然,我们应该向用户推荐跟他观影喜好相似度更高的电影。
c
o
s
θ
1
=
u
⋅
m
1
∣
u
∣
∣
m
1
∣
≈
4
×
5
+
5
×
1
+
3
×
1
5.92
×
6.48
≈
0.73
c
o
s
θ
2
=
u
⋅
m
2
∣
u
∣
∣
m
2
∣
≈
5
×
5
+
1
×
1
+
3
×
5
5.92
×
7.14
≈
0.97
cos\theta_1 = \frac{\boldsymbol{u} \cdot \boldsymbol{m1}}{|\boldsymbol{u}||\boldsymbol{m1}|} \approx \frac{4 \times 5 + 5 \times 1 + 3 \times 1}{5.92 \times 6.48} \approx 0.73 \\ cos\theta_2 = \frac{\boldsymbol{u} \cdot \boldsymbol{m2}}{|\boldsymbol{u}||\boldsymbol{m2}|} \approx \frac{5 \times 5 + 1 \times 1 + 3 \times 5}{5.92 \times 7.14} \approx 0.97
cosθ1=∣u∣∣m1∣u⋅m1≈5.92×6.484×5+5×1+3×1≈0.73cosθ2=∣u∣∣m2∣u⋅m2≈5.92×7.145×5+1×1+3×5≈0.97
大家可能会说,向量
m
2
\boldsymbol{m_2}
m2代表的电影肉眼可见跟用户是更加匹配的。的确,对于一个三维向量我们凭借直觉也能够给出正确的答案,但是对于一个
n
n
n维向量,当
n
n
n的值非常大时,你还有信心凭借肉眼的观察和本能的直觉给出准确的答案吗?向量的点积可以通过dot函数来计算,而向量的模长可以通过 NumPy 的linalg模块中的norm函数来计算,代码如下所示。
u = np.array([5, 1, 3])
m1 = np.array([4, 5, 1])
m2 = np.array([5, 1, 5])
print(np.dot(u, m1) / (np.linalg.norm(u) * np.linalg.norm(m1))) # 0.7302967433402214
print(np.dot(u, m2) / (np.linalg.norm(u) * np.linalg.norm(m2))) # 0.9704311900788593
向量的叉积
在二维空间,两个向量的叉积是这样定义的:
A
=
(
a
1
a
2
)
,
B
=
(
b
1
b
2
)
A
×
B
=
∣
a
1
a
2
b
1
b
2
∣
=
a
1
b
2
−
a
2
b
1
\boldsymbol{A} = \begin{pmatrix} a_{1} \\ a_{2} \end{pmatrix}, \quad \boldsymbol{B} = \begin{pmatrix} b_{1} \\ b_{2} \end{pmatrix} \\ \boldsymbol{A} \times \boldsymbol{B} = \begin{vmatrix} a_{1} \quad a_{2} \\ b_{1} \quad b_{2} \end{vmatrix} = a_{1}b_{2} - a_{2}b_{1}
A=(a1a2),B=(b1b2)A×B=
a1a2b1b2
=a1b2−a2b1
对于三维空间,两个向量的叉积结果是一个向量,如下所示:
A
=
(
a
1
a
2
a
3
)
,
B
=
(
b
1
b
2
b
3
)
A
×
B
=
∣
i
^
j
^
k
^
a
1
a
2
a
3
b
1
b
2
b
3
∣
=
⟨
i
^
∣
a
2
a
3
b
2
b
3
∣
,
−
j
^
∣
a
1
a
3
b
1
b
3
∣
,
k
^
∣
a
1
a
2
b
1
b
2
∣
⟩
\boldsymbol{A} = \begin{pmatrix} a_{1} \\ a_{2} \\ a_{3} \end{pmatrix}, \quad \boldsymbol{B} = \begin{pmatrix} b_{1} \\ b_{2} \\ b_{3} \end{pmatrix} \\ \boldsymbol{A} \times \boldsymbol{B} = \begin{vmatrix} \boldsymbol{\hat{i}} \quad \boldsymbol{\hat{j}} \quad \boldsymbol{\hat{k}} \\ a_{1} \quad a_{2} \quad a_{3} \\ b_{1} \quad b_{2} \quad b_{3} \end{vmatrix} = \langle \boldsymbol{\hat{i}}\begin{vmatrix} a_{2} \quad a_{3} \\ b_{2} \quad b_{3} \end{vmatrix}, -\boldsymbol{\hat{j}}\begin{vmatrix} a_{1} \quad a_{3} \\ b_{1} \quad b_{3} \end{vmatrix}, \boldsymbol{\hat{k}}\begin{vmatrix} a_{1} \quad a_{2} \\ b_{1} \quad b_{2} \end{vmatrix} \rangle
A=
a1a2a3
,B=
b1b2b3
A×B=
i^j^k^a1a2a3b1b2b3
=⟨i^
a2a3b2b3
,−j^
a1a3b1b3
,k^
a1a2b1b2
⟩
因为叉积的结果是向量,所以
A
×
B
\boldsymbol{A} \times \boldsymbol{B}
A×B和
B
×
A
\boldsymbol{B} \times \boldsymbol{A}
B×A的结果并不相同,事实上:
A
×
B
=
−
(
B
×
A
)
\boldsymbol{A} \times \boldsymbol{B} = -(\boldsymbol{B} \times \boldsymbol{A})
A×B=−(B×A)
NumPy 中可以通过cross函数来计算向量的叉积,代码如下所示。
print(np.cross(u, m1)) # [-14 7 21]
print(np.cross(m1, u)) # [ 14 -7 -21]
行列式
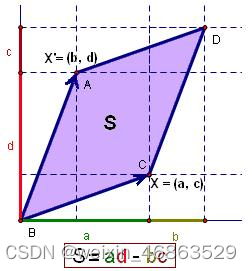
行列式(determinant)通常记作 d e t ( A ) det(\boldsymbol{A}) det(A)或 ∣ A ∣ |\boldsymbol{A}| ∣A∣,其中 A \boldsymbol{A} A是一个 n n n阶方阵。行列式可以看做是有向面积或体积的概念在一般欧几里得空间的推广,或者说行列式描述的是一个线性变换对“体积”所造成的影响。行列式的概念最早出现在解线性方程组的过程中,十七世纪晚期,关孝和(日本江户时代的数学家)与莱布尼茨的著作中已经使用行列式来确定线性方程组解的个数以及形式;十八世纪开始,行列式开始作为独立的数学概念被研究;十九世纪以后,行列式理论进一步得到发展和完善。
行列式的性质
行列式是由向量引出的,所以行列式解释的其实是向量的性质。
性质1:如果 d e t ( A ) det(\boldsymbol{A}) det(A)中某行(或某列)的元素全部为0,那么 d e t ( A ) = 0 det(\boldsymbol{A}) = 0 det(A)=0。
性质2:如果
d
e
t
(
A
)
det(\boldsymbol{A})
det(A)中某行(或某列)有公共因子
k
k
k,则可以提出
k
k
k,得到行列式
d
e
t
(
A
′
)
det(\boldsymbol{A^{'}})
det(A′),且
d
e
t
(
A
)
=
k
⋅
d
e
t
(
A
′
)
det(\boldsymbol{A}) = k \cdot det(\boldsymbol{A^{'}})
det(A)=k⋅det(A′)。
d
e
t
(
A
)
=
∣
a
11
a
12
…
a
1
n
⋮
⋮
⋱
⋮
k
a
i
1
k
a
i
2
…
k
a
i
n
⋮
⋮
⋱
⋮
a
n
1
a
n
2
…
a
n
n
∣
=
k
∣
a
11
a
12
…
a
1
n
⋮
⋮
⋱
⋮
a
i
1
a
i
2
…
a
i
n
⋮
⋮
⋱
⋮
a
n
1
a
n
2
…
a
n
n
∣
=
k
⋅
d
e
t
(
A
′
)
det(\boldsymbol{A})={\begin{vmatrix}a_{11}&a_{12}&\dots &a_{1n}\\\vdots &\vdots &\ddots &\vdots \\{\color {blue}k}a_{i1}&{\color {blue}k}a_{i2}&\dots &{\color {blue}k}a_{in}\\\vdots &\vdots &\ddots &\vdots \\a_{n1}&a_{n2}&\dots &a_{nn}\end{vmatrix}}={\color {blue}k}{\begin{vmatrix}a_{11}&a_{12}&\dots &a_{1n}\\\vdots &\vdots &\ddots &\vdots \\a_{i1}&a_{i2}&\dots &a_{in}\\\vdots &\vdots &\ddots &\vdots \\a_{n1}&a_{n2}&\dots &a_{nn}\end{vmatrix}}={\color {blue}k} \cdot det(\boldsymbol{A^{'}})
det(A)=
a11⋮kai1⋮an1a12⋮kai2⋮an2…⋱…⋱…a1n⋮kain⋮ann
=k
a11⋮ai1⋮an1a12⋮ai2⋮an2…⋱…⋱…a1n⋮ain⋮ann
=k⋅det(A′)
性质3:如果
d
e
t
(
A
)
det(\boldsymbol{A})
det(A)中某行(或某列)的每个元素是两数之和,则此行列式可拆分为两个行列式相加,如下所示。
∣
a
11
a
12
…
a
1
n
⋮
⋮
⋱
⋮
a
i
1
+
b
i
1
a
i
2
+
b
i
2
…
a
i
n
+
b
i
n
⋮
⋮
⋱
⋮
a
n
1
a
n
2
…
a
n
n
∣
=
∣
a
11
a
12
…
a
1
n
⋮
⋮
⋱
⋮
a
i
1
a
i
2
…
a
i
n
⋮
⋮
⋱
⋮
a
n
1
a
n
2
…
a
n
n
∣
+
∣
a
11
a
12
…
a
1
n
⋮
⋮
⋱
⋮
b
i
1
b
i
2
…
b
i
n
⋮
⋮
⋱
⋮
a
n
1
a
n
2
…
a
n
n
∣
{\begin{vmatrix}a_{11}&a_{12}&\dots &a_{1n}\\\vdots &\vdots &\ddots &\vdots \\{\color {blue}a_{i1}}+{\color {OliveGreen}b_{i1}}&{\color {blue}a_{i2}}+{\color {OliveGreen}b_{i2}}&\dots &{\color {blue}a_{in}}+{\color {OliveGreen}b_{in}}\\\vdots &\vdots &\ddots &\vdots \\a_{n1}&a_{n2}&\dots &a_{nn}\end{vmatrix}}={\begin{vmatrix}a_{11}&a_{12}&\dots &a_{1n}\\\vdots &\vdots &\ddots &\vdots \\{\color {blue}a_{i1}}&{\color {blue}a_{i2}}&\dots &{\color {blue}a_{in}}\\\vdots &\vdots &\ddots &\vdots \\a_{n1}&a_{n2}&\dots &a_{nn}\end{vmatrix}}+{\begin{vmatrix}a_{11}&a_{12}&\dots &a_{1n}\\\vdots &\vdots &\ddots &\vdots \\{\color {OliveGreen}b_{i1}}&{\color {OliveGreen}b_{i2}}&\dots &{\color {OliveGreen}b_{in}}\\\vdots &\vdots &\ddots &\vdots \\a_{n1}&a_{n2}&\dots &a_{nn}\end{vmatrix}}
a11⋮ai1+bi1⋮an1a12⋮ai2+bi2⋮an2…⋱…⋱…a1n⋮ain+bin⋮ann
=
a11⋮ai1⋮an1a12⋮ai2⋮an2…⋱…⋱…a1n⋮ain⋮ann
+
a11⋮bi1⋮an1a12⋮bi2⋮an2…⋱…⋱…a1n⋮bin⋮ann
性质4:如果
d
e
t
(
A
)
det(\boldsymbol{A})
det(A)中两行(或两列)元素对应成比例,那么
d
e
t
(
A
)
=
0
det(\boldsymbol{A}) = 0
det(A)=0。
性质5:如果 d e t ( A ) det(\boldsymbol{A}) det(A)中两行(或两列)互换得到 d e t ( A ′ ) det(\boldsymbol{A^{'}}) det(A′),那么 d e t ( A ) = − d e t ( A ′ ) det(\boldsymbol{A}) = -det(\boldsymbol{A^{'}}) det(A)=−det(A′)。
性质6:将
d
e
t
(
A
)
det(\boldsymbol{A})
det(A)中某行(或某列)的
k
k
k倍加进另一行(或另一列)里,行列式的值不变,如下所示。
∣
⋮
⋮
⋮
⋮
a
i
1
a
i
2
…
a
i
n
a
j
1
a
j
2
…
a
j
n
⋮
⋮
⋮
⋮
∣
=
∣
⋮
⋮
⋮
⋮
a
i
1
a
i
2
…
a
i
n
a
j
1
+
k
a
i
1
a
j
2
+
k
a
i
2
…
a
j
n
+
k
a
i
n
⋮
⋮
⋮
⋮
∣
{\begin{vmatrix}\vdots &\vdots &\vdots &\vdots \\a_{i1}&a_{i2}&\dots &a_{in}\\a_{j1}&a_{j2}&\dots &a_{jn}\\\vdots &\vdots &\vdots &\vdots \\\end{vmatrix}}={\begin{vmatrix}\vdots &\vdots &\vdots &\vdots \\a_{i1}&a_{i2}&\dots &a_{in}\\a_{j1}{\color {blue}+ka_{i1}}&a_{j2}{\color {blue}+ka_{i2}}&\dots &a_{jn}{\color {blue}+ka_{in}}\\\vdots &\vdots &\vdots &\vdots \\\end{vmatrix}}
⋮ai1aj1⋮⋮ai2aj2⋮⋮……⋮⋮ainajn⋮
=
⋮ai1aj1+kai1⋮⋮ai2aj2+kai2⋮⋮……⋮⋮ainajn+kain⋮
性质7:将行列式的行列互换,行列式的值不变,如下所示。
∣
a
11
a
12
…
a
1
n
a
21
a
22
…
a
2
n
⋮
⋮
⋱
⋮
a
n
1
a
n
2
…
a
n
n
∣
=
∣
a
11
a
21
…
a
n
1
a
12
a
22
…
a
n
2
⋮
⋮
⋱
⋮
a
1
n
a
2
n
…
a
n
n
∣
{\begin{vmatrix}a_{11}&a_{12}&\dots &a_{1n}\\a_{21}&a_{22}&\dots &a_{2n}\\\vdots &\vdots &\ddots &\vdots \\a_{n1}&a_{n2}&\dots &a_{nn}\end{vmatrix}}={\begin{vmatrix}a_{11}&a_{21}&\dots &a_{n1}\\a_{12}&a_{22}&\dots &a_{n2}\\\vdots &\vdots &\ddots &\vdots \\a_{1n}&a_{2n}&\dots &a_{nn}\end{vmatrix}}
a11a21⋮an1a12a22⋮an2……⋱…a1na2n⋮ann
=
a11a12⋮a1na21a22⋮a2n……⋱…an1an2⋮ann
性质8:方块矩阵
A
\boldsymbol{A}
A和
B
\boldsymbol{B}
B的乘积的行列式等于其行列式的乘积,即
d
e
t
(
A
B
)
=
d
e
t
(
A
)
d
e
t
(
B
)
det(\boldsymbol{A}\boldsymbol{B}) = det(\boldsymbol{A})det(\boldsymbol{B})
det(AB)=det(A)det(B)。特别的,若将矩阵中的每一行都乘以常数
r
r
r,那么行列式的值将是原来的
r
n
r^{n}
rn倍,即
d
e
t
(
r
A
)
=
d
e
t
(
r
I
n
⋅
A
)
=
r
n
d
e
t
(
A
)
det(r\boldsymbol{A}) = det(r\boldsymbol{I_{n}} \cdot \boldsymbol{A}) = r^{n}det(\boldsymbol{A})
det(rA)=det(rIn⋅A)=rndet(A),其中
I
n
\boldsymbol{I_{n}}
In是
n
n
n阶单位矩阵。
性质9:若 A \boldsymbol{A} A是可逆矩阵,那么 d e t ( A − 1 ) = ( d e t ( A ) ) − 1 det(\boldsymbol{A}^{-1}) = (det(\boldsymbol{A}))^{-1} det(A−1)=(det(A))−1。
行列式的计算
n
n
n阶行列式的计算公式如下所示:
d
e
t
(
A
)
=
∑
n
!
±
a
1
α
a
2
β
⋯
a
n
ω
det(\boldsymbol{A})=\sum_{n!} \pm {a_{1\alpha}a_{2\beta} \cdots a_{n\omega}}
det(A)=n!∑±a1αa2β⋯anω
对于二阶行列式,上面的公式相当于:
∣
a
11
a
12
a
21
a
22
∣
=
a
11
a
22
−
a
12
a
21
\begin{vmatrix} a_{11} \quad a_{12} \\ a_{21} \quad a_{22} \end{vmatrix} = a_{11}a_{22} - a_{12}a_{21}
a11a12a21a22
=a11a22−a12a21
对于三阶行列式,上面的计算公式相当于:
∣
a
11
a
12
a
13
a
21
a
22
a
23
a
31
a
32
a
33
∣
=
a
11
a
22
a
33
+
a
12
a
23
a
31
+
a
13
a
21
a
32
−
a
11
a
23
a
32
−
a
12
a
21
a
33
−
a
13
a
22
a
31
\begin{vmatrix} a_{11} \quad a_{12} \quad a_{13} \\ a_{21} \quad a_{22} \quad a_{23} \\ a_{31} \quad a_{32} \quad a_{33} \end{vmatrix} = a_{11}a_{22}a_{33} + a_{12}a_{23}a_{31} + a_{13}a_{21}a_{32} - a_{11}a_{23}a_{32} - a_{12}a_{21}a_{33} - a_{13}a_{22}a_{31}
a11a12a13a21a22a23a31a32a33
=a11a22a33+a12a23a31+a13a21a32−a11a23a32−a12a21a33−a13a22a31
高阶行列式可以用代数余子式(cofactor)展开成多个低阶行列式,如下所示:
d
e
t
(
A
)
=
a
11
C
11
+
a
12
C
12
+
⋯
+
a
1
n
C
1
n
=
∑
i
=
1
n
a
1
i
C
1
i
det(\boldsymbol{A})=a_{11}C_{11}+a_{12}C_{12}+ \cdots +a_{1n}C_{1n} = \sum_{i=1}^{n}{a_{1i}C_{1i}}
det(A)=a11C11+a12C12+⋯+a1nC1n=i=1∑na1iC1i
其中,
C
11
C_{11}
C11是原行列式去掉
a
11
a_{11}
a11所在行和列之后剩余的部分构成的行列式,以此类推。
矩阵
矩阵(matrix)是由一系列元素排成的矩形阵列,矩阵里的元素可以是数字、符号或数学公式。矩阵可以进行加法、减法、数乘、转置、矩阵乘法等运算,如下图所示。

值得一提的是矩阵乘法运算,该运算仅当第一个矩阵
A
\boldsymbol{A}
A的列数和另一个矩阵
B
\boldsymbol{B}
B的行数相等时才能定义。如果
A
\boldsymbol{A}
A是一个
m
×
n
m \times n
m×n的矩阵,
B
\boldsymbol{B}
B是一个
n
×
k
n \times k
n×k矩阵,它们的乘积是一个
m
×
k
m \times k
m×k的矩阵,其中元素的计算公式如下所示:
[
A
B
]
i
,
j
=
A
i
,
1
B
1
,
j
+
A
i
,
2
B
2
,
j
+
⋯
+
A
i
,
n
B
n
,
j
=
∑
r
=
1
n
A
i
,
r
B
r
,
j
[\mathbf{AB}]_{i,j} = A_{i,1}B_{1,j} + A_{i,2}B_{2,j} + \cdots + A_{i,n}B_{n,j} = \sum_{r=1}^n A_{i,r}B_{r,j}
[AB]i,j=Ai,1B1,j+Ai,2B2,j+⋯+Ai,nBn,j=r=1∑nAi,rBr,j
矩阵的乘法满足结合律和对矩阵加法的分配律:
结合律: ( A B ) C = A ( B C ) (\boldsymbol{AB})\boldsymbol{C} = \boldsymbol{A}(\boldsymbol{BC}) (AB)C=A(BC)。
左分配律: ( A + B ) C = A C + B C (\boldsymbol{A} + \boldsymbol{B})\boldsymbol{C} = \boldsymbol{AC} + \boldsymbol{BC} (A+B)C=AC+BC。
右分配律: C ( A + B ) = C A + C B \boldsymbol{C}(\boldsymbol{A} + \boldsymbol{B}) = \boldsymbol{CA} + \boldsymbol{CB} C(A+B)=CA+CB。
矩阵乘法不满足交换律。一般情况下,矩阵 A \boldsymbol{A} A和 B \boldsymbol{B} B的乘积 A B \boldsymbol{AB} AB存在,但 B A \boldsymbol{BA} BA不一定存在,即便 B A \boldsymbol{BA} BA存在,大多数时候 A B ≠ B A \boldsymbol{AB} \neq \boldsymbol{BA} AB=BA。
矩阵乘法的一个基本应用是在线性方程组上。线性方程组是方程组的一种,它符合以下的形式:
{
a
1
,
1
x
1
+
a
1
,
2
x
2
+
⋯
+
a
1
,
n
x
n
=
b
1
a
2
,
1
x
1
+
a
2
,
2
x
2
+
⋯
+
a
2
,
n
x
n
=
b
2
⋮
⋮
a
m
,
1
x
1
+
a
m
,
2
x
2
+
⋯
+
a
m
,
n
x
n
=
b
m
\begin{cases} a_{1,1}x_{1} + a_{1,2}x_{2} + \cdots + a_{1,n}x_{n}= b_{1} \\ a_{2,1}x_{1} + a_{2,2}x_{2} + \cdots + a_{2,n}x_{n}= b_{2} \\ \vdots \quad \quad \quad \vdots \\ a_{m,1}x_{1} + a_{m,2}x_{2} + \cdots + a_{m,n}x_{n}= b_{m} \end{cases}
⎩
⎨
⎧a1,1x1+a1,2x2+⋯+a1,nxn=b1a2,1x1+a2,2x2+⋯+a2,nxn=b2⋮⋮am,1x1+am,2x2+⋯+am,nxn=bm
运用矩阵的方式,可以将线性方程组写成一个向量方程:
A
x
=
b
\boldsymbol{Ax} = \boldsymbol{b}
Ax=b
其中,
A
\boldsymbol{A}
A是由方程组里未知数的系数排成的
m
×
n
m \times n
m×n矩阵,
x
\boldsymbol{x}
x是含有
n
n
n个元素的行向量,
b
\boldsymbol{b}
b是含有
m
m
m个元素的行向量。
矩阵是线性变换(保持向量加法和标量乘法的函数)的便利表达法。矩阵乘法的本质在联系到线性变换的时候最能体现,因为矩阵乘法和线性变换的合成有以下的联系,即每个 m × n m \times n m×n的矩阵 A \boldsymbol{A} A都代表了一个从 R n \boldsymbol{R}^{n} Rn射到 R m \boldsymbol{R}^{m} Rm的线性变换。如果无法理解上面这些内容,推荐大家看看B站上名为《线性代数的本质》的视频,相信这套视频会让你对线性代数有一个更好的认知。
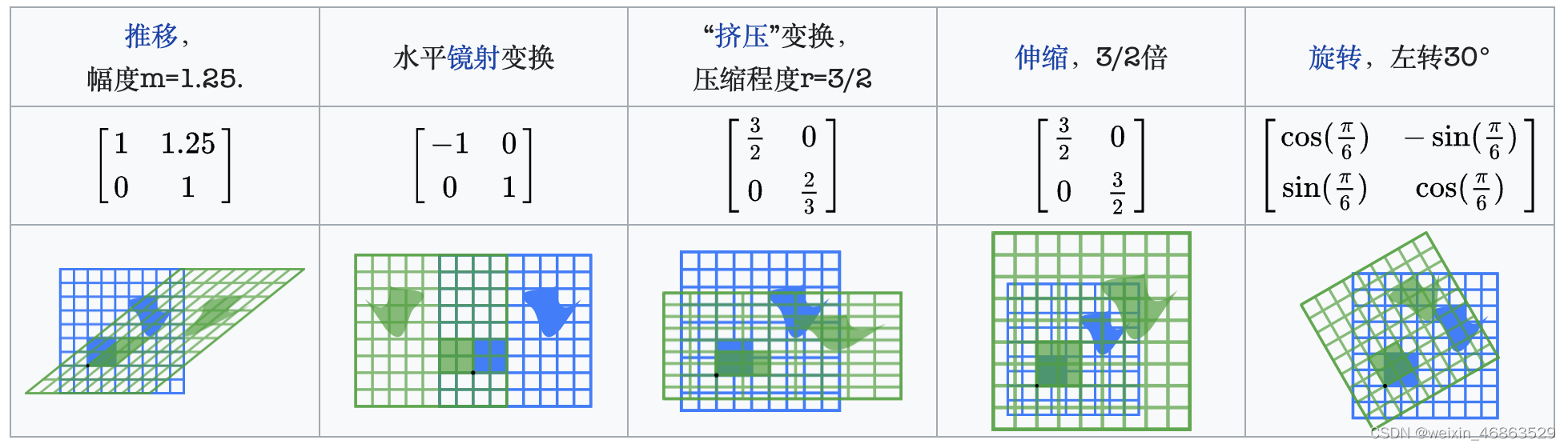
下图是一个来自于维基百科的例子,图中展示了一些典型的二维实平面上的线性变换对平面向量(图形)造成的效果以及它们对应的二维矩阵,其中每个线性变换将蓝色图形映射成绿色图形;平面的原点 ( 0 , 0 ) (0, 0) (0,0)用黑点表示。
矩阵对象
NumPy 中提供了专门用于线性代数(linear algebra)的模块和表示矩阵的类型matrix,当然我们通过二维数组也可以表示一个矩阵,官方并不推荐使用matrix类而是建议使用二维数组,而且有可能在将来的版本中会移除matrix类。无论如何,利用这些已经封装好的类和函数,我们可以轻松愉快的实现很多对矩阵的操作。
我们可以通过下面的代码来创建矩阵(matrix)对象。
代码:
m1 = np.matrix('1 2 3; 4 5 6')
m1
说明:
matrix构造器可以传入类数组对象也可以传入字符串来构造矩阵对象。
输出:
matrix([[1, 2, 3],
[4, 5, 6]])
代码:
m2 = np.asmatrix(np.array([[1, 1], [2, 2], [3, 3]]))
m2
说明:
asmatrix函数也可以用mat函数代替,这两个函数其实是同一个函数。
输出:
matrix([[1, 1],
[2, 2],
[3, 3]])
代码:
m1 * m2
输出:
matrix([[14, 14],
[32, 32]])
说明:注意
matrix对象和ndarray对象乘法运算的差别,matrix对象的*运算是矩阵乘法运算。如果两个二维数组要做矩阵乘法运算,应该使用@运算符或matmul函数,而不是*运算符。
矩阵对象的属性如下表所示。
| 属性 | 说明 |
|---|---|
A | 获取矩阵对象对应的ndarray对象 |
A1 | 获取矩阵对象对应的扁平化后的ndarray对象 |
I | 可逆矩阵的逆矩阵 |
T | 矩阵的转置 |
H | 矩阵的共轭转置 |
shape | 矩阵的形状 |
size | 矩阵元素的个数 |
矩阵对象的方法跟之前讲过的ndarray数组对象的方法基本差不多,此处不再进行赘述。
线性代数模块
NumPy 的linalg模块中有一组标准的矩阵分解运算以及诸如求逆和行列式之类的函数,它们跟 MATLAB 和 R 等语言所使用的是相同的行业标准线性代数库,下面的表格列出了numpy以及linalg模块中一些常用的线性代数相关函数。
| 函数 | 说明 |
|---|---|
diag | 以一维数组的形式返回方阵的对角线元素或将一维数组转换为方阵(非对角元素元素为0) |
matmul | 矩阵乘法运算 |
trace | 计算对角线元素的和 |
norm | 求矩阵或向量的范数 |
det | 计算行列式的值 |
matrix_rank | 计算矩阵的秩 |
eig | 计算矩阵的特征值(eigenvalue)和特征向量(eigenvector) |
inv | 计算非奇异矩阵( n n n阶方阵)的逆矩阵 |
pinv | 计算矩阵的摩尔-彭若斯(Moore-Penrose)广义逆 |
qr | QR分解(把矩阵分解成一个正交矩阵与一个上三角矩阵的积) |
svd | 计算奇异值分解(singular value decomposition) |
solve | 解线性方程组 A x = b \boldsymbol{Ax}=\boldsymbol{b} Ax=b,其中 A \boldsymbol{A} A是一个方阵 |
lstsq | 计算 A x = b \boldsymbol{Ax}=\boldsymbol{b} Ax=b的最小二乘解 |
下面我们简单尝试一下上面的函数,先试一试求逆矩阵。
代码:
m3 = np.array([[1., 2.], [3., 4.]])
m4 = np.linalg.inv(m3)
m4
输出:
array([[-2. , 1. ],
[ 1.5, -0.5]])
代码:
np.around(m3 @ m4)
说明:
around函数对数组元素进行四舍五入操作,默认小数点后面的位数为0。
输出:
array([[1., 0.],
[0., 1.]])
说明:矩阵和它的逆矩阵做矩阵乘法会得到单位矩阵。
计算行列式的值。
代码:
m5 = np.array([[1, 3, 5], [2, 4, 6], [4, 7, 9]])
np.linalg.det(m5)
输出:
2
计算矩阵的秩。
代码:
np.linalg.matrix_rank(m5)
输出:
3
求解线性方程组。
{
x
1
+
2
x
2
+
x
3
=
8
3
x
1
+
7
x
2
+
2
x
3
=
23
2
x
1
+
2
x
2
+
x
3
=
9
\begin{cases} x_1 + 2x_2 + x_3 = 8 \\ 3x_1 + 7x_2 + 2x_3 = 23 \\ 2x_1 + 2x_2 + x_3 = 9 \end{cases}
⎩
⎨
⎧x1+2x2+x3=83x1+7x2+2x3=232x1+2x2+x3=9
对于上面的线性方程组,我们可以用矩阵的形式来表示它,如下所示。
A
=
[
1
2
1
3
7
2
2
2
1
]
,
x
=
[
x
1
x
2
x
3
]
,
b
=
[
8
23
9
]
\boldsymbol{A} = \begin{bmatrix} 1 & 2 & 1\\ 3 & 7 & 2\\ 2 & 2 & 1 \end{bmatrix}, \quad \boldsymbol{x} = \begin{bmatrix} x_1 \\ x_2\\ x_3 \end{bmatrix}, \quad \boldsymbol{b} = \begin{bmatrix} 8 \\ 23\\ 9 \end{bmatrix}
A=
132272121
,x=
x1x2x3
,b=
8239
A x = b \boldsymbol{Ax} = \boldsymbol{b} Ax=b
线性方程组有唯一解的条件:系数矩阵 A \boldsymbol{A} A的秩等于增广矩阵 A b \boldsymbol{Ab} Ab的秩,而且跟未知数的个数相同。
代码:
A = np.array([[1, 2, 1], [3, 7, 2], [2, 2, 1]])
b = np.array([8, 23, 9]).reshape(-1, 1)
print(np.linalg.matrix_rank(A))
print(np.linalg.matrix_rank(np.hstack((A, b))))
说明:使用数组对象的
reshape方法调形时,如果其中一个参数为-1,那么该维度有多少个元素是通过数组元素个数(size属性)和其他维度的元素个数自动计算出来的。
输出:
3
3
代码:
np.linalg.solve(A, b)
输出:
array([[1.],
[2.],
[3.]])
说明:上面的结果表示,线性方程组的解为: x 1 = 1 , x 2 = 2 , x 3 = 3 x_1 = 1, x_2 = 2, x_3 = 3 x1=1,x2=2,x3=3。
下面是另一种求解线性方程组的方法,大家可以停下来思考下为什么。
x
=
A
−
1
⋅
b
\boldsymbol{x} = \boldsymbol{A}^{-1} \cdot \boldsymbol{b}
x=A−1⋅b
代码:
np.linalg.inv(A) @ b
输出:
array([[1.],
[2.],
[3.]])
多项式
除了数组,NumPy 中还封装了用于多项式(polynomial)运算的数据类型。多项式是变量的整数次幂与系数的乘积之和,形如:
f
(
x
)
=
a
n
x
n
+
a
n
−
1
x
n
−
1
+
⋯
+
a
1
x
1
+
a
0
x
0
f(x)=a_nx^n + a_{n-1}x^{n-1} + \cdots + a_1x^{1} + a_0x^{0}
f(x)=anxn+an−1xn−1+⋯+a1x1+a0x0
在 NumPy 1.4版本之前,我们可以用poly1d类型来表示多项式,目前它仍然可用,但是官方提供了新的模块numpy.polynomial,它除了支持基本的幂级数多项式外,还可以支持切比雪夫多项式、拉盖尔多项式等。
创建多项式对象
创建poly1d对象,例如:
f
(
x
)
=
3
x
2
+
2
x
+
1
\small{f(x)=3x^{2}+2x+1}
f(x)=3x2+2x+1。
代码:
p1 = np.poly1d([3, 2, 1])
p2 = np.poly1d([1, 2, 3])
print(p1)
print(p2)
输出:
2
3 x + 2 x + 1
2
1 x + 2 x + 3
多项式的操作
获取多项式的系数
代码:
print(p1.coefficients)
print(p2.coeffs)
输出:
[3 2 1]
[1 2 3]
两个多项式的四则运算
代码:
print(p1 + p2)
print(p1 * p2)
输出:
2
4 x + 4 x + 4
4 3 2
3 x + 8 x + 14 x + 8 x + 3
带入 x \small{x} x求多项式的值
代码:
print(p1(3))
print(p2(3))
输出:
34
18
多项式求导和不定积分
代码:
print(p1.deriv())
print(p1.integ())
输出:
6 x + 2
3 2
1 x + 1 x + 1 x
求多项式的根
例如有多项式 f ( x ) = x 2 + 3 x + 2 \small{f(x)=x^2+3x+2} f(x)=x2+3x+2,多项式的根即一元二次方程 x 2 + 3 x + 2 = 0 \small{x^2+3x+2=0} x2+3x+2=0的解。
代码:
p3 = np.poly1d([1, 3, 2])
print(p3.roots)
输出:
[-2. -1.]
如果使用numpy.polynomial模块的Polynomial类来表示多项式对象,那么对应的操作如下所示。
代码:
from numpy.polynomial import Polynomial
p3 = Polynomial((2, 3, 1))
print(p3) # 输出多项式
print(p3(3)) # 令x=3,计算多项式的值
print(p3.roots()) # 计算多项式的根
print(p3.degree()) # 获得多项式的次数
print(p3.deriv()) # 求导
print(p3.integ()) # 求不定积分
输出:
2.0 + 3.0·x + 1.0·x²
20.0
[-2. -1.]
2
3.0 + 2.0·x
0.0 + 2.0·x + 1.5·x² + 0.33333333·x³
最小二乘解
Polynomial类还有一个名为fit的类方法,它可以给多项式求最小二乘解。所谓最小二乘解(least-squares solution),是用最小二乘法通过最小化误差的平方和来寻找数据的最佳匹配函数的系数。假设多项式为
f
(
x
)
=
a
x
+
b
\small{f(x)=ax+b}
f(x)=ax+b,最小二乘解就是让下面的残差平方和
R
S
S
\small{RSS}
RSS达到最小的
a
\small{a}
a和
b
\small{b}
b。
R
S
S
=
∑
i
=
0
k
(
f
(
x
i
)
−
y
i
)
2
RSS = \sum_{i=0}^{k}(f(x_i) - y_i)^{2}
RSS=i=0∑k(f(xi)−yi)2
例如,我们想利用收集到的月收入和网购支出的历史数据来建立一个预测模型,以达到通过某人的月收入预测他网购支出金额的目标,下面是我们收集到的收入和网购支出的数据,保存在两个数组中。
x = np.array([
25000, 15850, 15500, 20500, 22000, 20010, 26050, 12500, 18500, 27300,
15000, 8300, 23320, 5250, 5800, 9100, 4800, 16000, 28500, 32000,
31300, 10800, 6750, 6020, 13300, 30020, 3200, 17300, 8835, 3500
])
y = np.array([
2599, 1400, 1120, 2560, 1900, 1200, 2320, 800, 1650, 2200,
980, 580, 1885, 600, 400, 800, 420, 1380, 1980, 3999,
3800, 725, 520, 420, 1200, 4020, 350, 1500, 560, 500
])
我们可以先绘制散点图来了解两组数据是否具有正相关或负相关关系。正相关意味着数组x中较大的值对应到数组y中也是较大的值,而负相关则意味着数组x中较大的值对应到数组y中较小的值。
import matplotlib.pyplot as plt
plt.figure(dpi=120)
plt.scatter(x, y, color='blue')
plt.show()
输出:
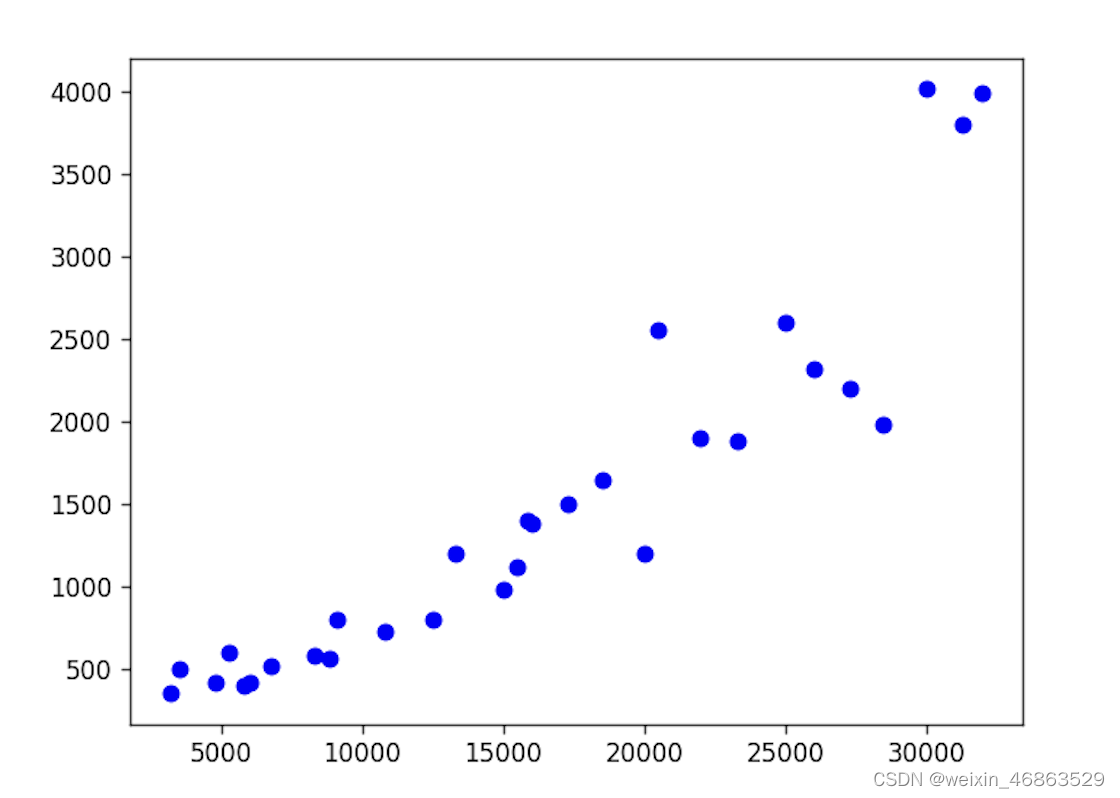
如果需要定量的研究两组数据的相关性,我们可以计算协方差或相关系数,对应的 NumPy 函数分别是cov和corrcoef。
代码:
np.corrcoef(x, y)
输出:
array([[1. , 0.92275889],
[0.92275889, 1. ]])
说明:相关系数是一个
-1到1之间的值,越靠近1说明正相关性越强,越靠近-1说明负相关性越强,靠近0则说明两组数据没有明显的相关性。上面月收入和网购支出之间的相关系数是0.92275889,说明二者是强正相关关系。
通过上面的操作,我们确定了收入和网购支出之前存在强正相关关系,于是我们用这些数据来创建一个回归模型,找出一条能够很好的拟合这些数据点的直线。这里,我们就可以用到上面提到的fit方法,具体的代码如下所示。
代码:
from numpy.polynomial import Polynomial
Polynomial.fit(x, y, deg=1).convert().coef
说明:
deg=1说明回归模型最高次项就是1次项,回归模型形如 y = a x + b \small{y=ax+b} y=ax+b;如果要生一个类似于 y = a x 2 + b x + c \small{y=ax^2+bx+c} y=ax2+bx+c的模型,就需要设置deg=2,以此类推。
输出:
array([-2.94883437e+02, 1.10333716e-01])
根据上面输出的结果,我们的回归方程应该是 y = 0.110333716 x − 294.883437 \small{y=0.110333716x-294.883437} y=0.110333716x−294.883437。我们将这个回归方程绘制到刚才的散点图上,红色的点是我们的预测值,蓝色的点是历史数据,也就是真实值。
代码:
import matplotlib.pyplot as plt
plt.scatter(x, y, color='blue')
plt.scatter(x, 0.110333716 * x - 294.883437, color='red')
plt.plot(x, 0.110333716 * x - 294.883437, color='darkcyan')
plt.show()
输出:
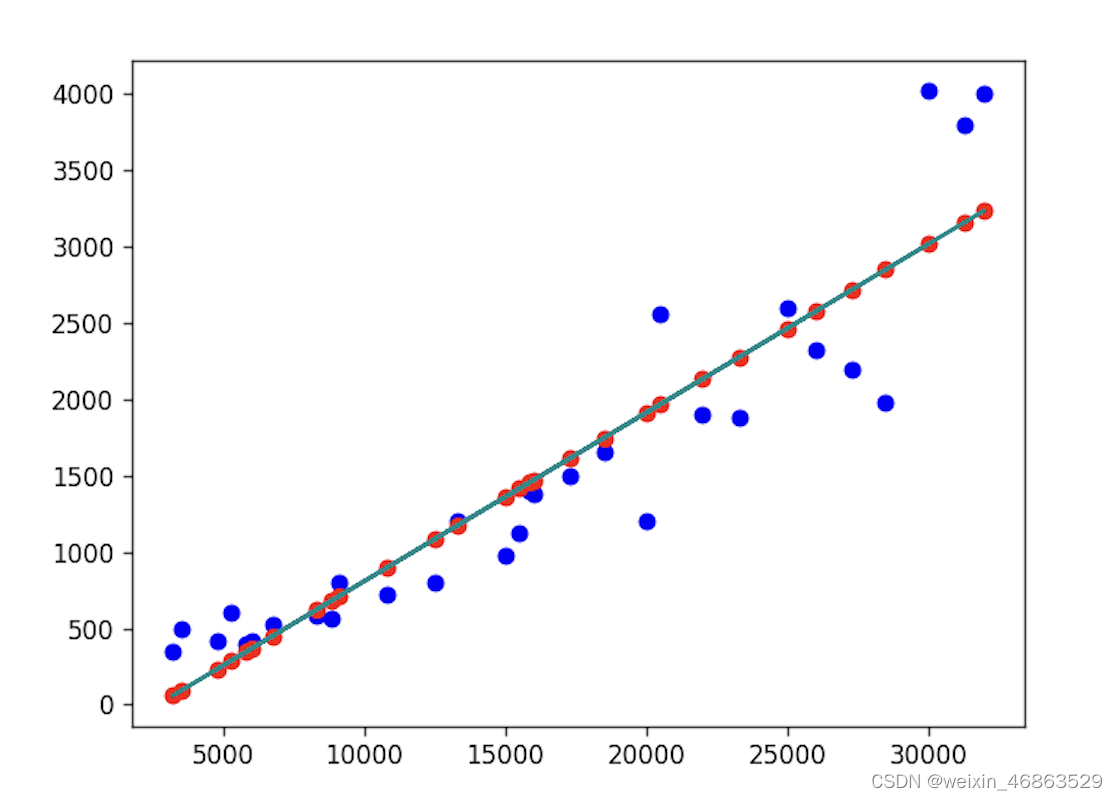
如果不使用Polynomial类型的fit方法,我们也可以通过 NumPy 提供的polyfit函数来完成同样的操作,有兴趣的读者可以自行研究。
















 810
810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











