






前言
生成模型现在主要分为两类,分别是GAN和Diffusion Model,但是GAN存在一个很棘手的问题就是训练不稳定,这也是Diffusion Model相比之下的优势。DDPM是基于Markovian扩散过程的模型,虽然在生成模型上取得了不错的效果,但是同时也存在一个大缺点,就是由于在重建生成阶段是需要一步步进行,步数通常为2000,导致推理时间非常长,需要多次迭代才能产生高质量的生成样本。基于以上问题,论文提出了基于DDPM改进的模型DDIM,这是一个Non-Markovian过程,并且可以加速采样重建过程同时牺牲较小的图像质量。
理论推导

先上结论,上面那条公式就是DDIM的基于Non-Markovian过程推导出来的公式,主要分为三个部分,第一个部分是在第步预测的
,即在
预测的
;第二部分是基于
采样的噪声;第三部分是加上一个随机的噪声扰动。从上面的公式可以得到当
,
时,也就是说不是固定的t和t-1的关系,可以从任意的
推理得到
。区别于DDPM中只能一步步进行逆重建,DDIM可以重建至任意步,于是可以加速重建过程。比如,在t=2000时,对于DDPM模型必须得计算2000次,然而对于DDIM模型来说,可以每100步做一次计算,只用计算20次就够了,加速了100倍,当然重建的图片也会相应损失质量。
下面展示上述公式的推理过程,主要参考B站上的一位up主,讲得非常透彻,链接如下:
扩散模型 Diffusion Model 2-3 DDIM_哔哩哔哩_bilibili
区别于DDPM用贝叶斯公式进行推导时需要条件,DDIM不需要这个条件直接推导,通过下图的假设和已知条件进行带入,最后得到了结论的式子。

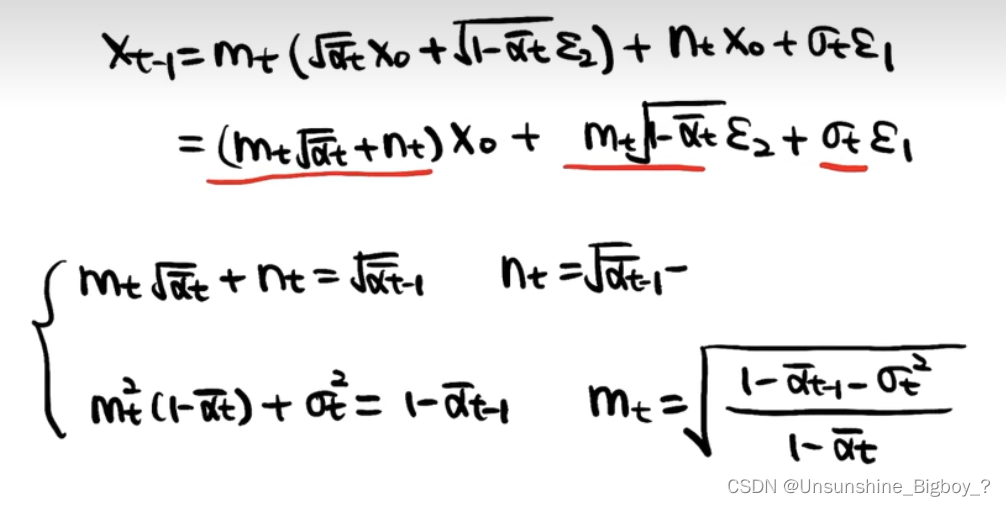
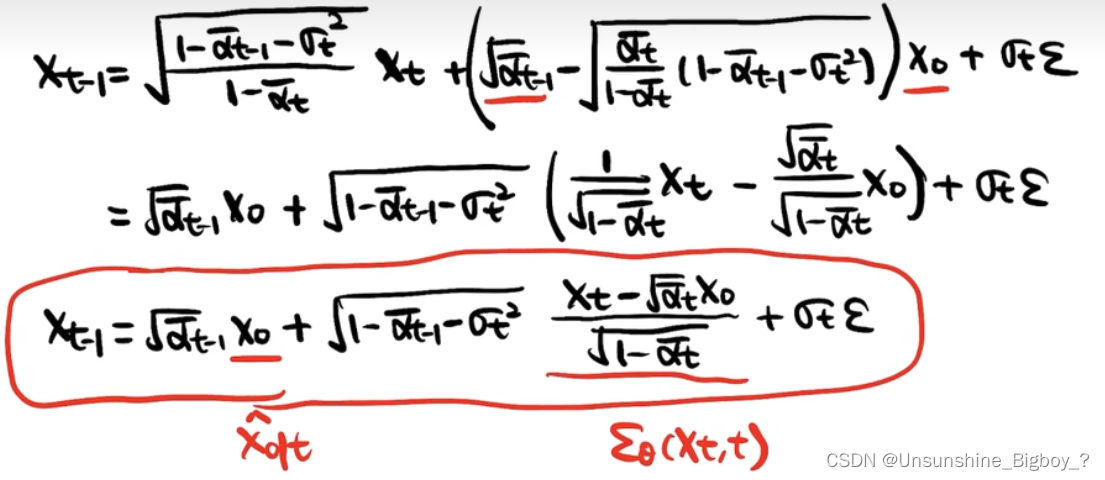
论文中还有常微分方程的推导,这里略过。
实验
步数和噪声程度的实验

上图就是在设置DDIM不同的step时用FID来衡量采样的质量,同时也改变不同的参数,这是一个加噪参数,
时代表的是第t步的添加的随机噪声为0,指的就是DDIM模型;当
时,就是DDPM模型,这里想表达就是当
时的DDIM模型就是一个隐式概率模型,也就是说一个确定的
会推导出一个确定的结果,在语义上基本不会有区别,但是对于DDPM模型来说,由于需要加入了随机的噪声,因而会导致最后结果具有一定的随机性。由上图可以观察到,step越多,重建的质量是越高的;同时
越大,质量也会下降。在Figure3的
就是step的间隔。
重建时间和质量实验
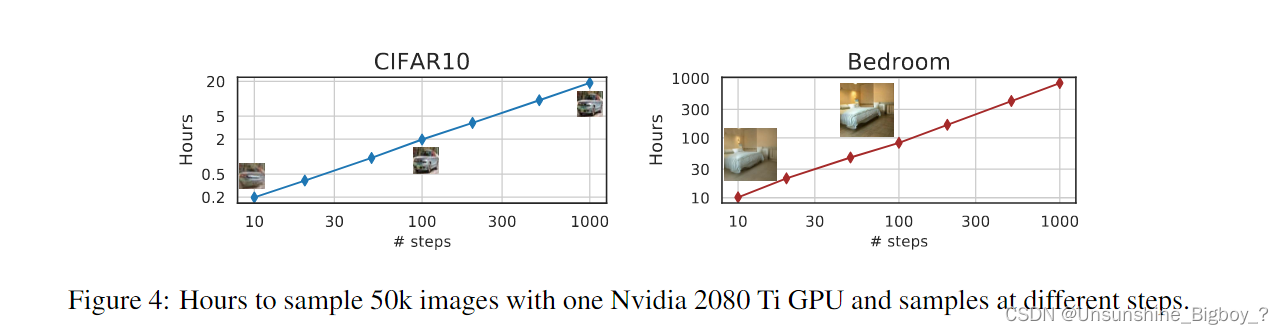
上图可以看出steps越多,需要重建生成的时间就越长,而且接近于线性的关系。

在上图可以观察到,steps越多,人眼感受到的图像的重建质量也越好,即细节信息更清楚。
插值实验
对DDIM模型的进行不同类型的插值,例如以下的公式进行插值或者线性插值,比如生成图像时对
进行第一次采样生成的图像,然后对
第二次采样生成另外一幅图像,观察在这两次采样结果中进行插值后的点得到生成图像的结果。
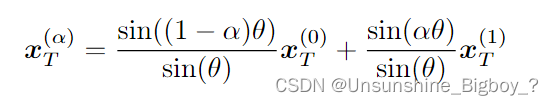
以下为简单的插值实验结果,证明了xT中的简单插值可以导致两个样本之间的语义上有意义的插值。这允许DDIM直接通过潜在变量在高级别上控制生成的图像,而DDPM无法做到这一点。

总结
相较于DDPM来说,DDIM更具更加确定性的结果,并且可以减少一定的计算时间。DDPM是可以通过改变一定的参数比如论文中的是可以互相转化的,其实也提供了另外一种模型的思路,比如也可以只用DDIM中论文的一部分来减少DDPM模型的计算时间,或者直接应用DDIM在参数
上改变,看看能否对超分辨或者图像降噪等问题有新的实验发现。注意:DDIM只是在重建阶段使用,Unet训练的参数和DDPM是一样的,也就是说是通过DDPM训练参数得到的Unet模型应用到DDIM上的,这点是不变的。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









