






 本文探讨了如何使用LatentDiffusionModel进行图生成和图像去噪,通过condition编码器和UNet结构,结合concat操作,以及训练时对加噪图y_t和x_t的交替学习方法,实现在高噪声水平下图1生成图2的过程。
本文探讨了如何使用LatentDiffusionModel进行图生成和图像去噪,通过condition编码器和UNet结构,结合concat操作,以及训练时对加噪图y_t和x_t的交替学习方法,实现在高噪声水平下图1生成图2的过程。
想要实现图生图/文生图,DM具体怎么训练的呢?
学习的目标都是:你要生成内容的加噪版本
文生图,图加噪
图1生图2,图2加噪
latent diffusion model
‘生’字前面的就是condition了,通过condition的encoder给到UNet
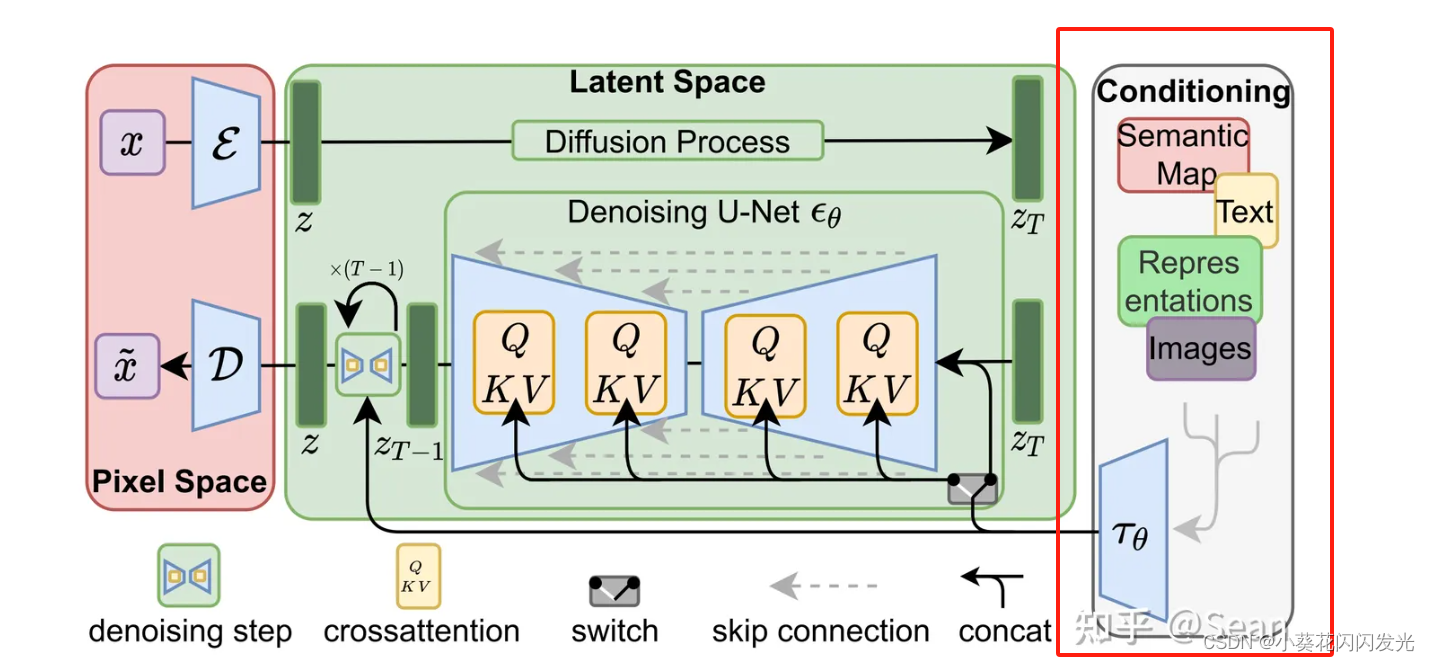
concat
把图1concat在噪声图中,从而实现图1生图2
典型就是SR3
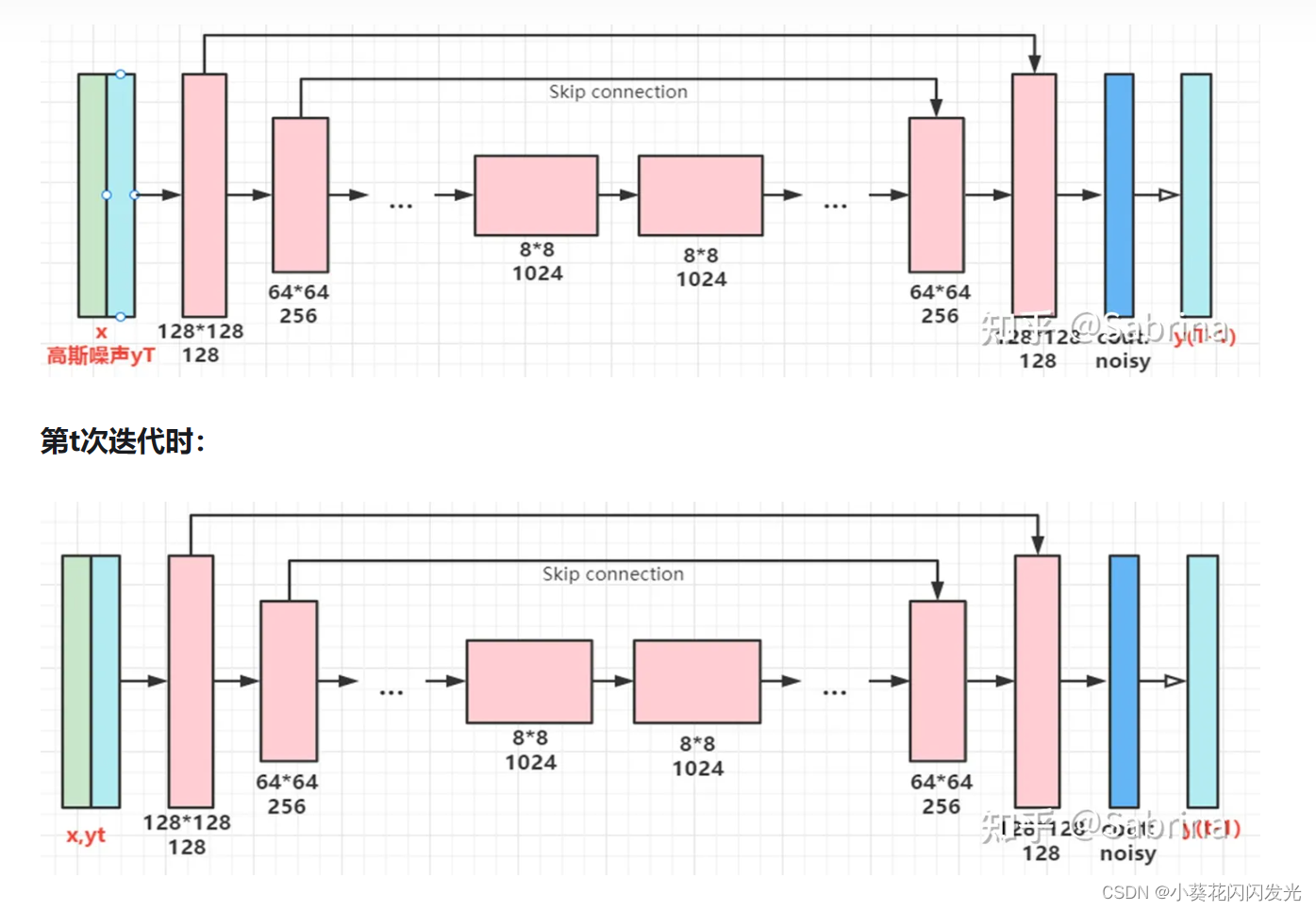
从加噪的图1开始去噪
记图1为y,图2为x,加噪图分别为y_t和x_t
训练的时候UNet学x_t的噪声,inference的时候不是从纯噪声而是从y_t开始进行去噪。
(认为在噪声水平够高的时候y_t和x_t都到了一个空间)
但是,训练的时候根本没见过y_t,所以训练的时候,可以交替/随机选学y_t还是x_t(得设置一个t的阈值,因为只有在t大的时候才能认为y_t和x_t在一个空间可以互相转换)















 6585
6585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









