







目录
一、Redis主从复制
一般来说,用将Redis运用于工程项目中,只使用一台Redis是万万不可能的,原因如下:
- 从结构上,单个Redis服务器会发生单点故障,并且一台服务器需要处理所有的请求负载,压力较大;
- 从容量上,单个Redis服务器内存容量有限,就算一台Redis服务器内存容量为256G,也不能将所有内存用作Redis存储数据,一般来说,单台Redis最大使用内存不应该超过20G。
因此,便出现了主从复制。
1.1 概念
主从复制:指的是将一个Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点 (master/leader),后者称为从节点(slave/follower)。 数据的复制是单向的 ,只能从主节点到从节 点。Master以写为主,Slave以读为主。 默认情况下,每台Redis服务器都是主节点,且一个主节点可以有多个从节点(或者没有从节点), 但一个从节点只能有一个主节点。从机只能读取数据不能写入,数据直接从主机得来!
1.2 主从复制的作用
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复,实际上是一种服务冗余
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务 (即 写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载。尤其是在写少读多的场景下,通过从节点分担读负载,可以大大提供Redis服务器的并发量。
- 高可用(集群)基石:除了上述作用以外,主从复制还是哨兵和集群能够实现的基础,因此说主从复制是Redis高可用的基础。
电商网站上的商品,一般都是一次上传,无数次浏览,也就是“多读少写”。对于这种场景,我们可 以使用如下的架构:
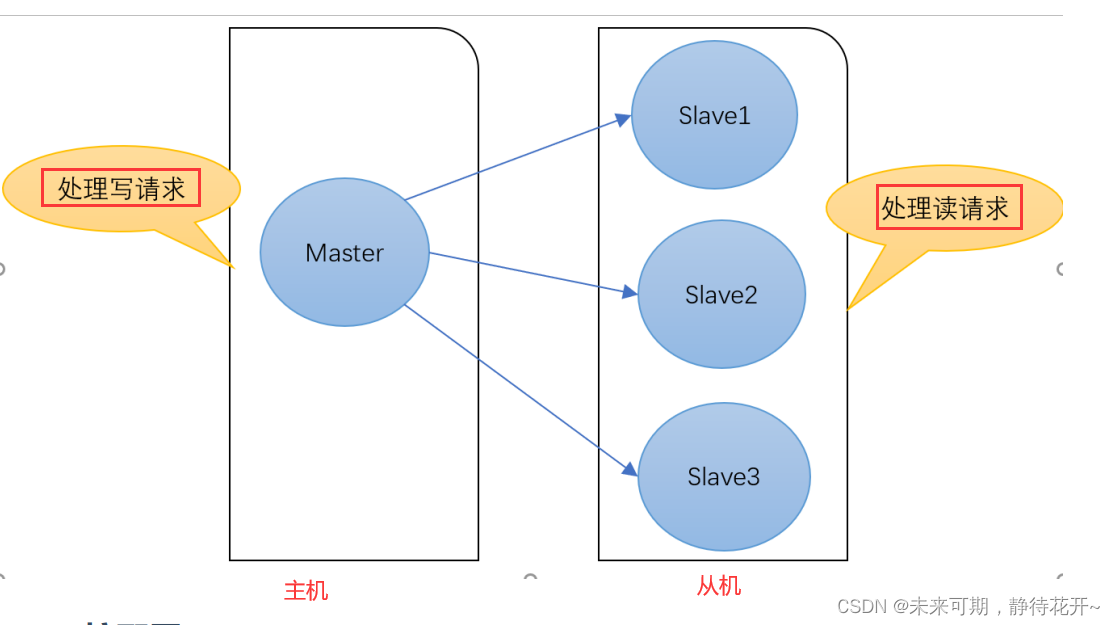
平时在redis数据库中设置的数据,关闭系统了,还能看见就是进行了持久化,把内存中的数据存到磁盘上,等重新启动数据库,再从磁盘中把数据拷到内存中。
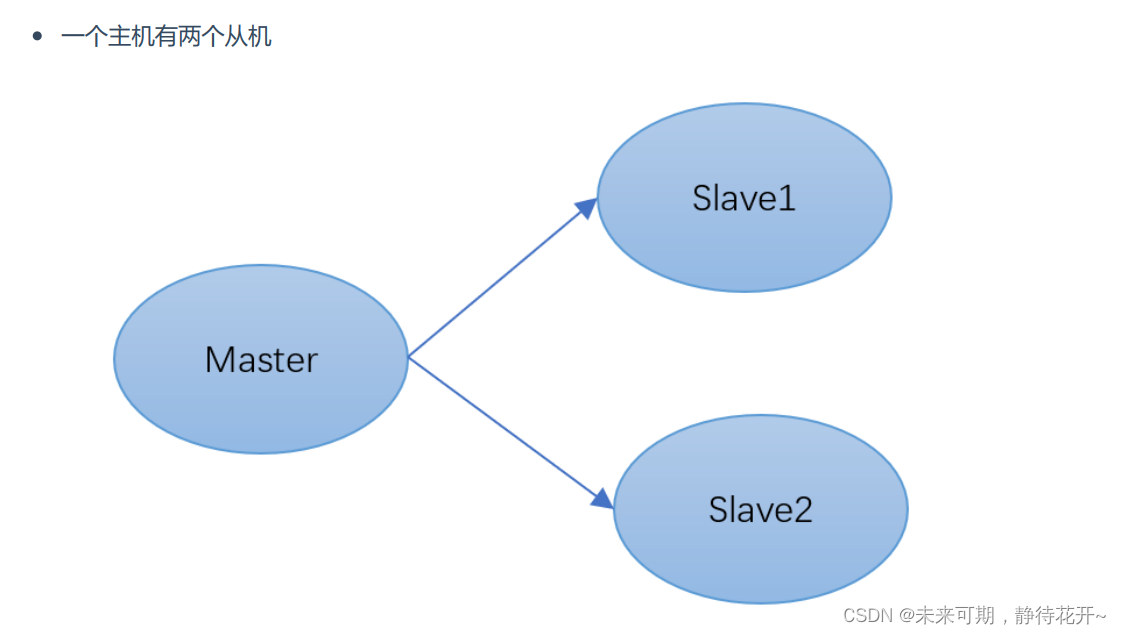
1.3 实现一主二从
默认情况下,每台Redis服务器都是主节点 ,主需要配置从机就行!
实现一个主机两个从机,如下图所示:
如何在一台电脑上产生3个服务器?
先拷贝一份redis.conf配置文件,把里面的端口改了,然后再让服务器端使用这个配置文件登录:redis-server ./redis1.conf,这样就是用别的端口号登录的服务器端。如下图所示:
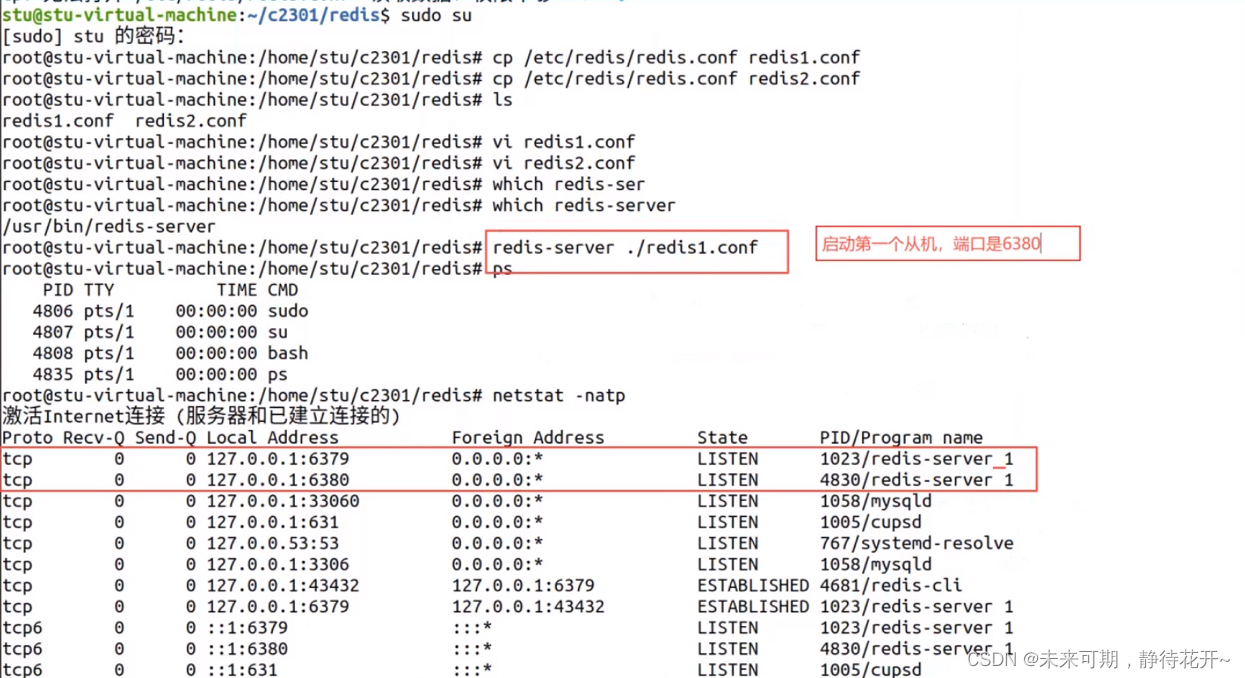

只配置从机,不需要配置主机!认老大!一主(6379)二从(6380,6381)
配置从机:
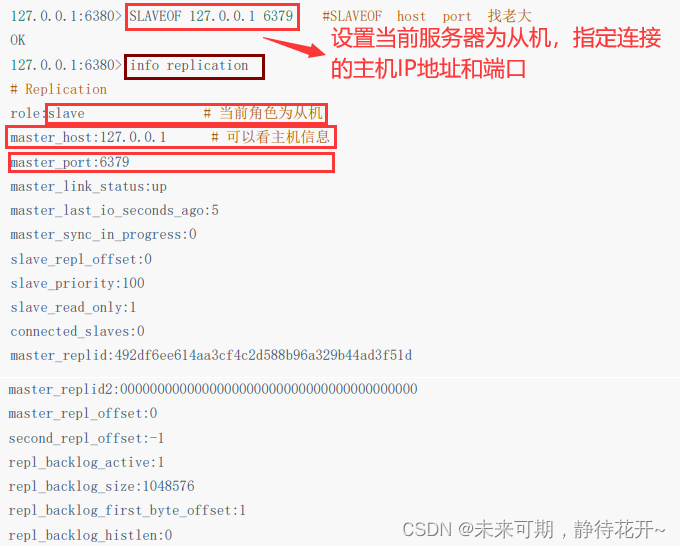
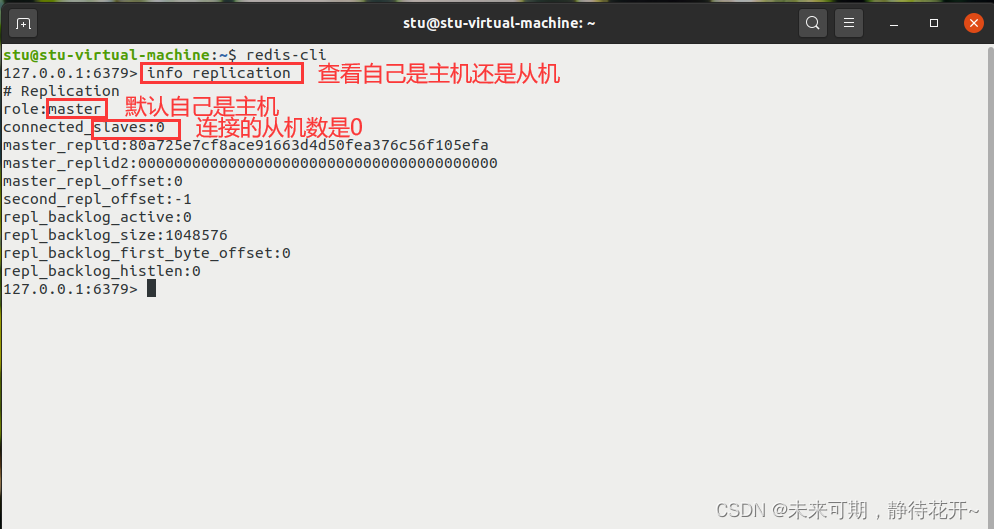
此时查看主机信息:
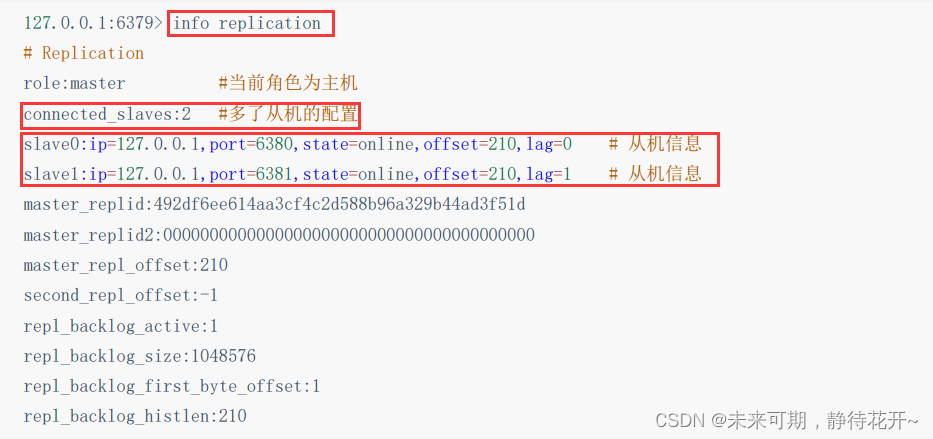
至此,便实现了一主两从的配置。真实的主从配置应该在配置文件中配置,这样的话是永久的,我们通过命令配置的是临时的!

1.4 哨兵模式
自动选举老大的模式!
引入的原因:主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。Redis从2.8开始正式提供了Sentinel(哨兵)架构来解决这个问题。
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个单独的进程,作为进程,他 会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
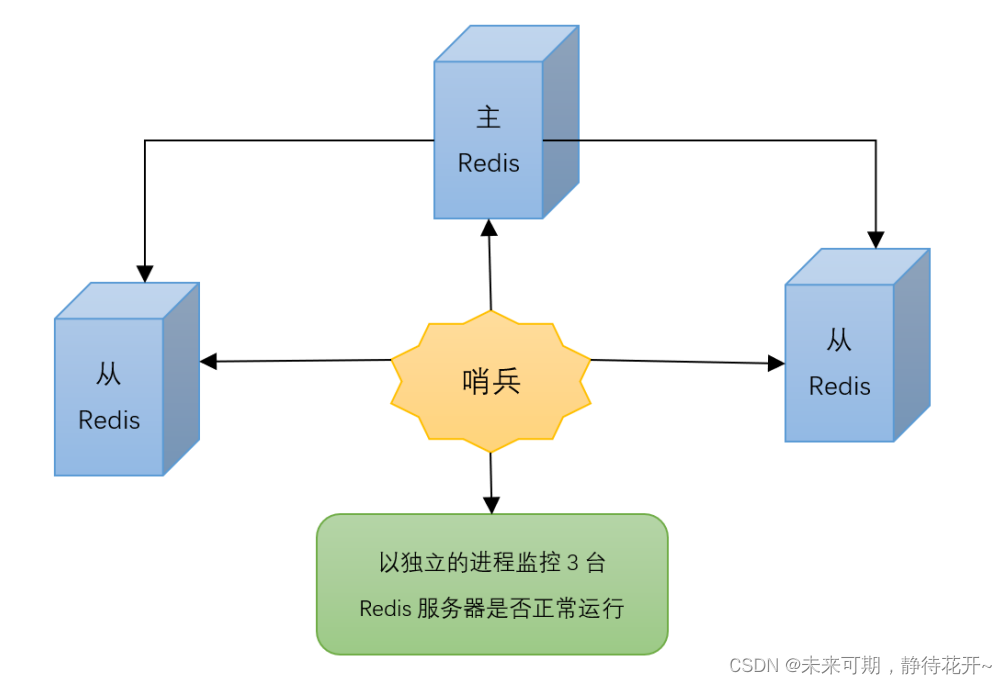
1.4.1 哨兵的作用
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器
- 当哨兵监测到Master宕机,会自动将Slave切换成Master,然后通过发布/订阅模式通知其他的从 服务器,修改配置文件,让它切换主机。
然而一个哨兵进程对Redis服务器进程监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
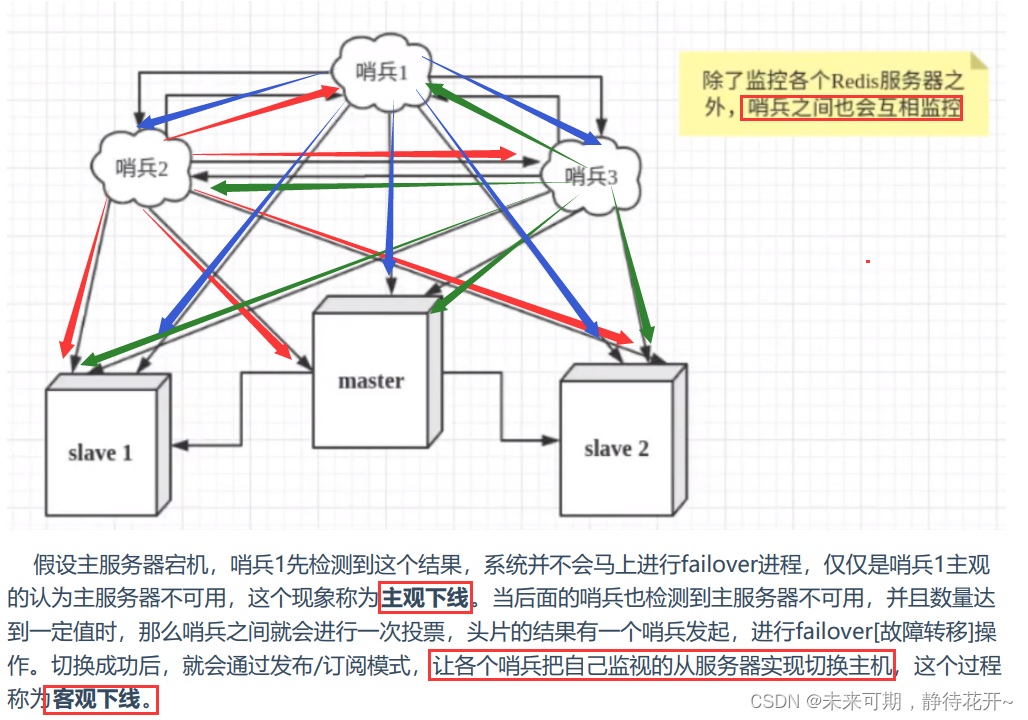
1.4.2 哨兵模式的优缺点

二、Redis缓存穿透和雪崩
2.1 缓存穿透——查不到
缓存穿透的就是用户想要查询一个数据,发现Redis中没有,也就是缓存没有命中,于是向持久层数据库发起查询,发现也没有这个数据,于是本次查询失败。当用户很多的情况下,缓存都没有命中,又 都去请求持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于缓存穿透。
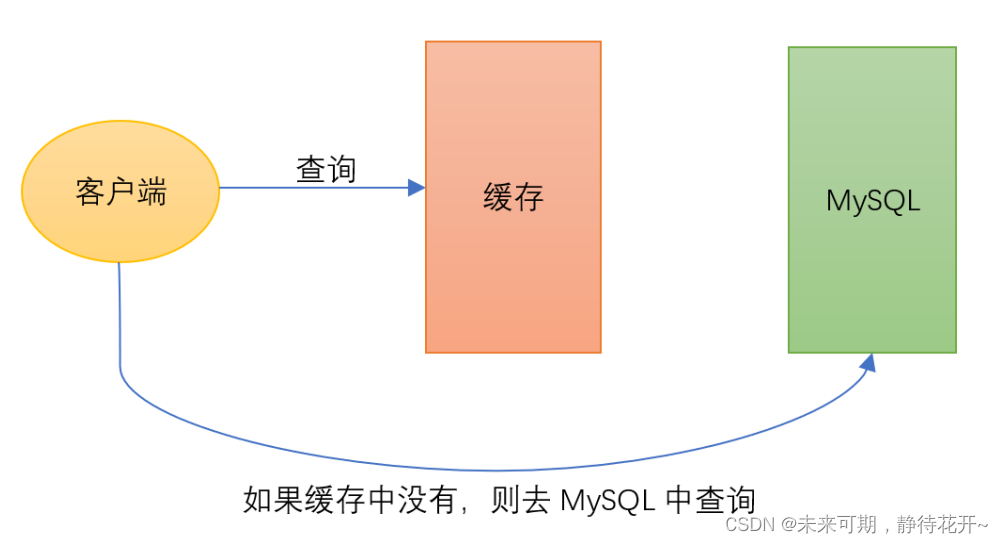
如上图:客户端请求的数据既不在缓存中,也不在数据库中,这样的请求会直接落到数据库上。当这种情况频繁发生时,会导致大量请求直接访问数据库,给数据库带来巨大的压力,甚至可能导致数据库崩溃。
2.1.1 缓存穿透解决办法
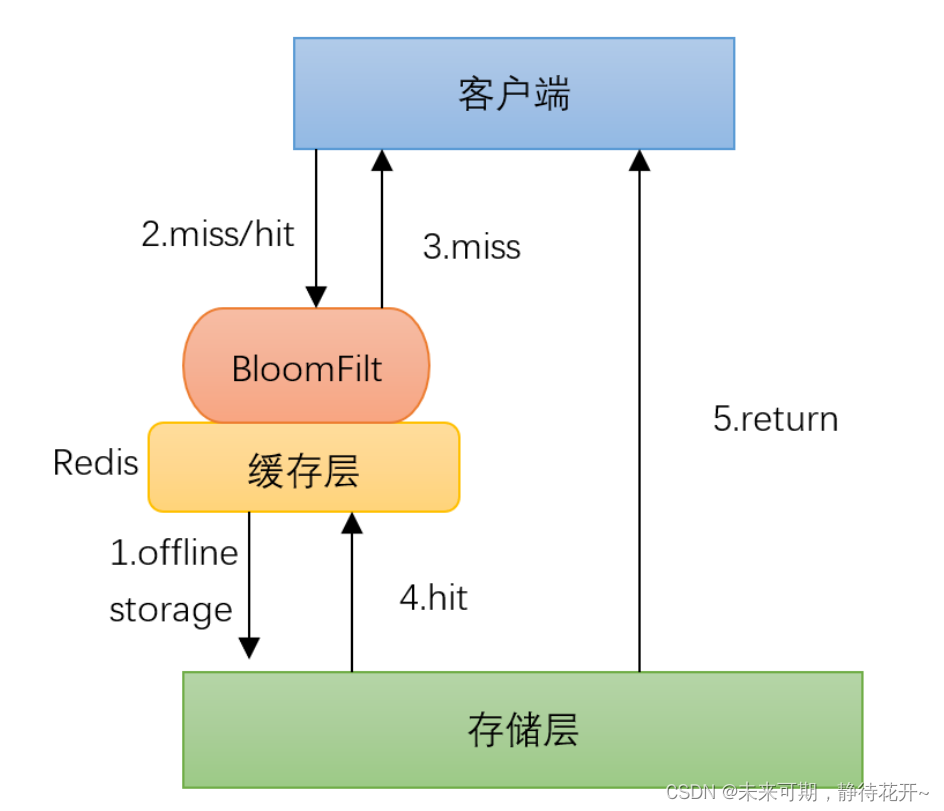
解决方案1 -- 布隆过滤器
在缓存之前增加布隆过滤器,以快速判断某个 key 是否可能存在,从而避免对不存在的 key 进行数据库查询。
实现方法:
- 在应用启动时,将所有可能存在的 key 加入布隆过滤器。
- 查询时,首先通过布隆过滤器判断 key 是否存在,如果不存在则直接返回。
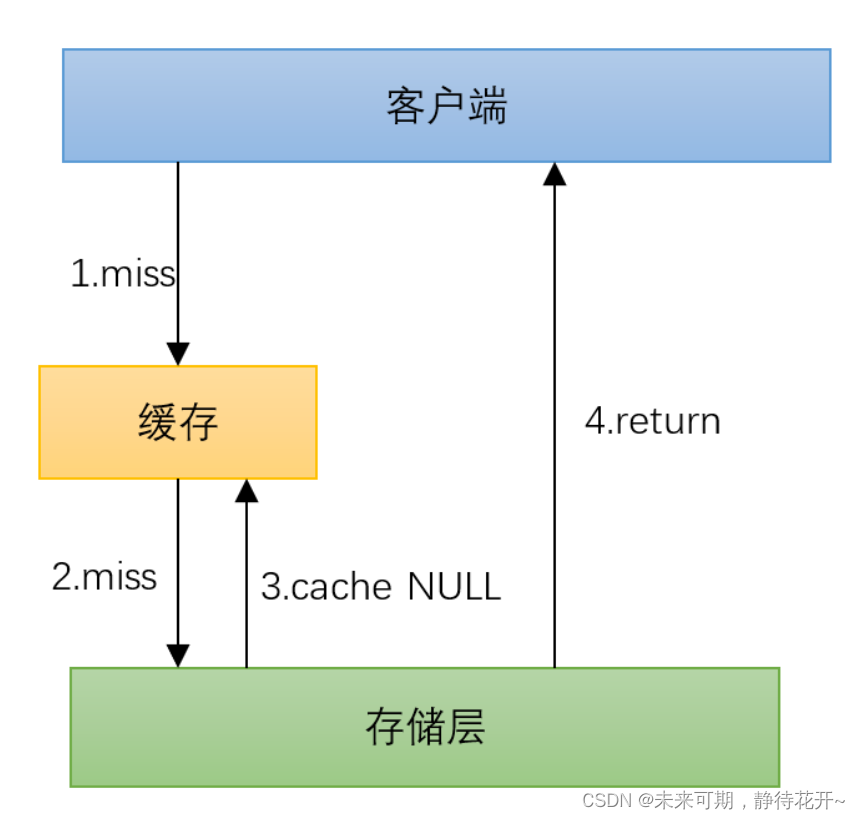
解决方案2--缓存空对象
将查询结果为空的数据也缓存起来,避免频繁查询同一个不存在的数据。
实现方法:
- 当数据库查询结果为空时,将结果(例如,
null或特殊值)缓存起来,并设置一个较短的过期时间(例如 5 分钟)。
2.2 缓存击穿 - 量太大,缓存过期
缓存击穿(Cache Breakdown)是指缓存中某个热点数据(即频繁访问的数据)在过期的瞬间,有大量请求同时访问该数据,导致这些请求直接打到数据库上,给数据库带来巨大压力。与缓存穿透不同,缓存击穿的问题在于某个特定的热点数据的失效,而不是请求不存在的数据。
2.2.1 缓存击穿的原因
缓存击穿通常由以下原因引起:
- 热点数据失效:某个被频繁访问的数据在缓存中过期失效,而在该数据失效的一瞬间,有大量请求涌入。
- 缓存设置不合理:没有合理地设置缓存的过期时间或者没有采取必要的保护措施,导致热点数据过期时引发大量访问。
2.2.2 缓存击穿解决办法
解决方法1 -- 热点数据永不过期
对于特别重要的热点数据,可以设置为永不过期,并通过异步线程或定时任务定期更新缓存中的数据。
实现方法:
- 设置缓存数据永不过期,同时通过异步线程或定时任务定期刷新缓存数据。
解决方案2 -- 加互斥锁
通过在缓存失效后,使用分布式锁或互斥锁来控制只有一个请求可以访问数据库并更新缓存,其他请求等待锁释放后再读取缓存。
实现方法:
- 当缓存失效时,尝试获取锁,如果获取成功则访问数据库并更新缓存。
- 其他请求等待锁释放后再读取缓存。
分布式锁: 使用分布式锁,保证对于每个key同时只有一个线程去查询后端服务,其他线程没有获得 分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,因此对分布式锁 的考验比较大
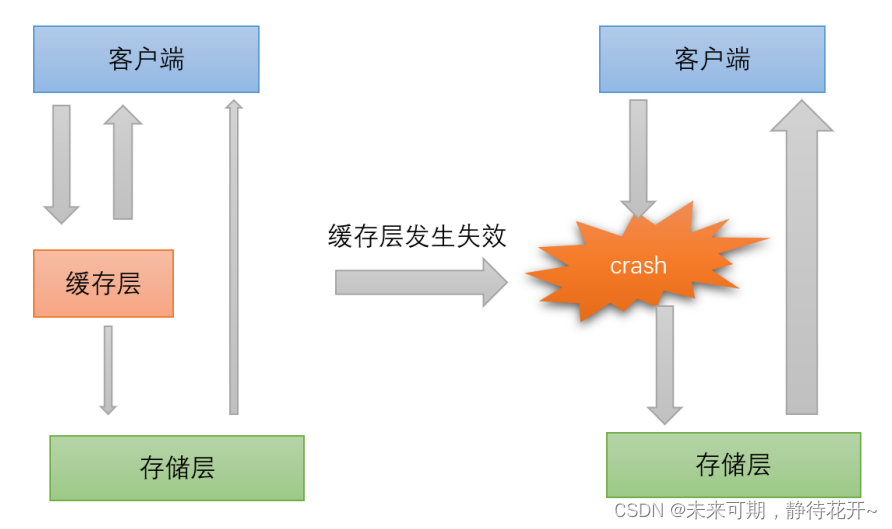
2.3 缓存雪崩
缓存雪崩(Cache Avalanche)是指缓存中的大量数据在同一时间过期或缓存服务器宕机,导致大量请求直接落到数据库上,给数据库带来巨大压力,可能导致数据库崩溃。与缓存穿透和缓存击穿不同,缓存雪崩的问题在于大量缓存数据同时失效。
举例理解:在写文本的时候,马上 要到双十一零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。 那么到了凌晨一点钟的时候,这批商品的缓存就过期了。从而对这批商品的访问查询,都落到了后台数据库上,对于数据库而言,就会产生周期性的压力波峰。于是所有的请求都会达到存储层,存储层的调 用量会暴增,造成存储层也会宕机的情况。
2.3.1 缓存雪崩成因
- 缓存集中失效:大量缓存数据在同一时间过期。
- 缓存服务器宕机:缓存服务器不可用,导致所有请求直接访问数据库。
其实集中过期,倒不是非常致命,比较致命的缓存雪崩,是缓存服务器某个节点宕机或断网。因为自 然形成的缓存雪崩,一定是在某个时间段集中创建缓存,这个时候,数据库也是可以顶住压力的。无非 就是对数据库产生周期性的压力而已。而缓存服务器节点的宕机,对数据服务器造成的压力是不可预估 的,很可能瞬间就把数据库压宕机。
2.3.2 缓存雪崩解决办法
解决方案1 -- Redis高可用
使用高可用的缓存架构,如 Redis 集群、主从复制和哨兵模式,保证缓存服务的高可用性。
实现方法:
- 部署 Redis 集群,实现数据分片和高可用。
- 使用 Redis 哨兵模式,实现自动故障转移和主从切换。
解决方案2 -- 限流降级
对请求进行限流保护,避免瞬间的大量请求打到数据库上。在必要时进行服务降级处理,返回默认值或错误信息。
实现方法:
- 使用限流算法(如令牌桶、漏桶)对请求进行限流保护。
- 在缓存失效或服务器压力过大时,进行服务降级处理。
解决方案3 -- 数据预热
在系统启动时,提前将热点数据加载到缓存中,避免在流量高峰期缓存失效。数据预热的含义就是在正式部署之前,先把可能的数据先预先访问一遍,这样部分可能大量访问的数 据就会加载到缓存中,在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间, 让缓存失效的时间点尽量均匀。
至此,Redis数据库的介绍就基本介绍完毕,感谢阅读本专栏,如果喜欢,点赞加关注!
















 1200
1200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











