







 超级会员免费看
超级会员免费看
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
很高兴你打开了这篇博客,更多AI知识,请关注我、订阅专栏《AI知识图谱》,内容持续更新中…
一、Hugging Face平台简介
1. 什么是Hugging Face
Hugging Face是一个专注于自然语言处理(NLP)的开源平台,已发展成为全球机器学习和人工智能社区中最重要的资源中心之一。平台名称来源于拥抱脸的emoji表情(🤗),这也是其官方标志。
Hugging Face由法国企业家Clément Delangue、Julien Chaumond和Thomas Wolf于2016年在纽约创立,最初是一家开发面向青少年聊天机器人的公司,后来转型为专注于机器学习平台。
如今,它已成为开源AI模型的首选平台,被AI专家和爱好者称为"ChatGPT的开源替代品"和"AI的GitHub"。
作为一个开源平台,Hugging Face的核心使命是通过开源和开放科学来推进和民主化人工智能技术,让AI技术更加普及和易于获取。
2. Hugging Face的发展历程
Hugging Face的发展可以分为几个关键阶段:
- 2016年:作为聊天机器人应用创立
- 2018年:开源聊天机器人背后的模型,转型为机器学习平台
- 2021年3月:在B轮融资中筹集4000万美元
- 2021年4月:与多个研究团体合作启动BigScience研究工作坊
- 2022年7月:发布首个开源大型语言模型BLOOM
- 2023年2月:宣布与亚马逊网络服务(AWS)合作
- 2023年8月:完成D轮融资,筹集2.35亿美元,估值达45亿美元
- 2024年6月:与Meta和Scaleway一起为欧洲初创公司推出AI加速器计划
- 2025年4月:收购人形机器人创业公司Pollen Robotics
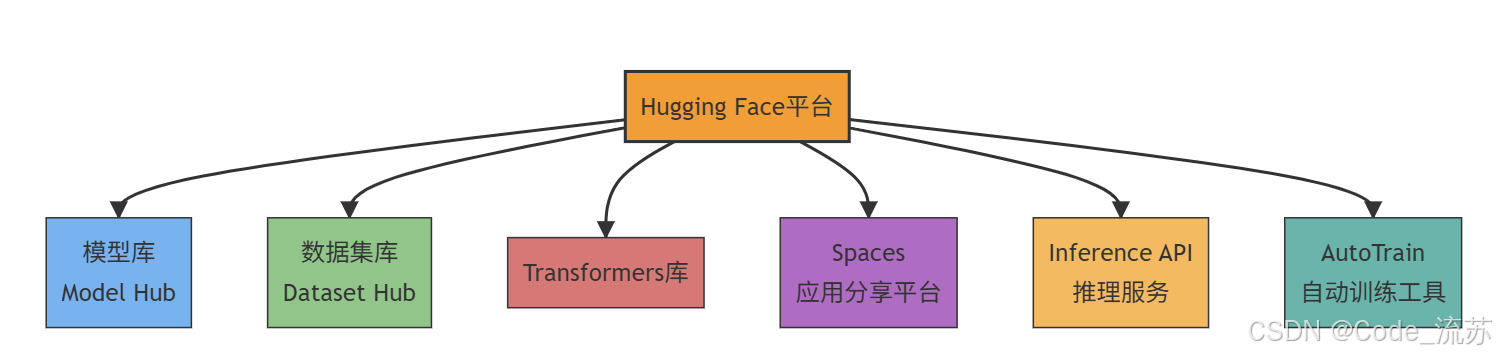
3. Hugging Face的核心功能
Hugging Face平台提供多种核心功能,使其成为AI开发者和研究人员的宝贵资源:
- 模型库(Model Hub):托管了超过30万个开源预训练模型,涵盖NLP、计算机视觉、音频处理等多个领域
- 数据集库(Dataset Hub):提供数千个用于训练和测试的数据集
- Transformers库:一个流行的Python库,让开发者能够轻松使用、微调和部署最先进的模型
- Spaces:允许用户创建和分享机器学习应用的Web界面
- Inference API:提供托管模型推理服务
- AutoTrain:无代码模型训练和部署工具
二、Hugging Face的技术架构
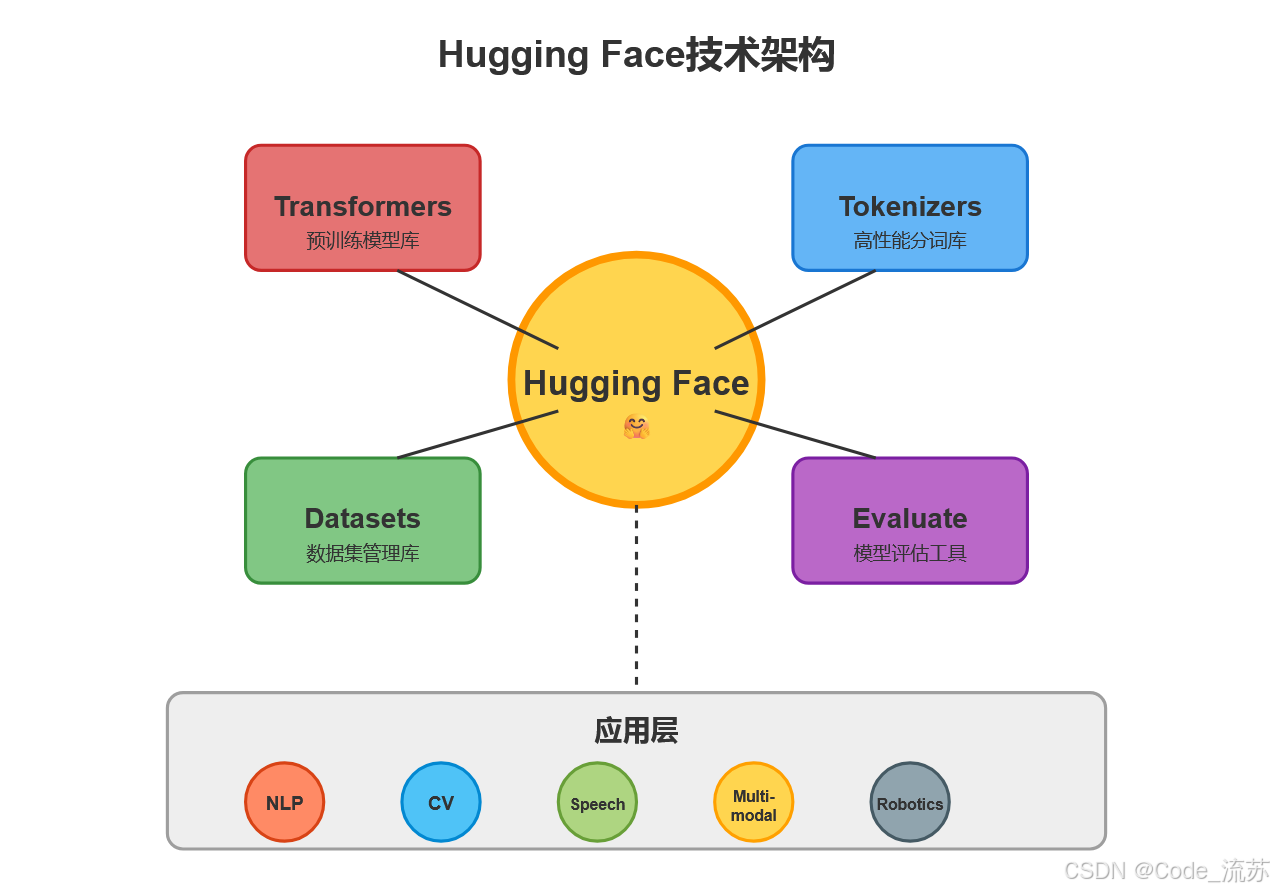
1. Transformers库
Transformers是Hugging Face的核心库,它提供了对预训练模型的便捷访问和使用。该库支持自然语言处理、计算机视觉、音频和多模态模型的推理和训练。
Transformers库的核心优势包括:
- 简单易用:只需几行代码即可使用最先进的模型
- 多框架支持:同时支持PyTorch、TensorFlow和JAX
- 丰富的预训练模型:包括BERT、GPT、T5、ViT等知名模型
- 任务多样性:支持文本生成、分类、翻译、摘要、问答等多种任务
基本使用示例:
# 使用pipeline快速实现文本生成
from transformers import pipeline
# 初始化一个文本生成pipeline
generator = pipeline("text-generation", model="distilbert/distilgpt2")
# 生成文本
result = generator("人工智能正在改变我们的生活方式,特别是", max_length=50)
print(result[0]['generated_text'])
2. Datasets库
Datasets库是Hugging Face生态系统的另一个重要组成部分,它允许用户一行代码加载数据集,并使用强大的数据处理方法快速准备训练数据。该库基于Apache Arrow格式,能够处理大型数据集,实现零拷贝读取,没有内存限制,确保最佳的速度和效率。
使用示例:
# 导入datasets库
from datasets import load_dataset
# 加载GLUE数据集中的MRPC任务数据
dataset = load_dataset("nyu-mll/glue", "mrpc", split="train")
# 查看数据集的前几个样本
print(dataset[:5])
3. 其他核心组件和工具
除了Transformers和Datasets库外,Hugging Face还提供了多种工具和组件:
- Tokenizers:高性能的分词库,支持多种分词策略
- Evaluate:模型评估工具库
- Gradio和Streamlit集成:用于创建交互式演示
- safetensors:一种更安全的模型权重保存格式
- Auto*类:自动选择合适的模型架构和配置的工具类
三、如何使用Hugging Face🤗
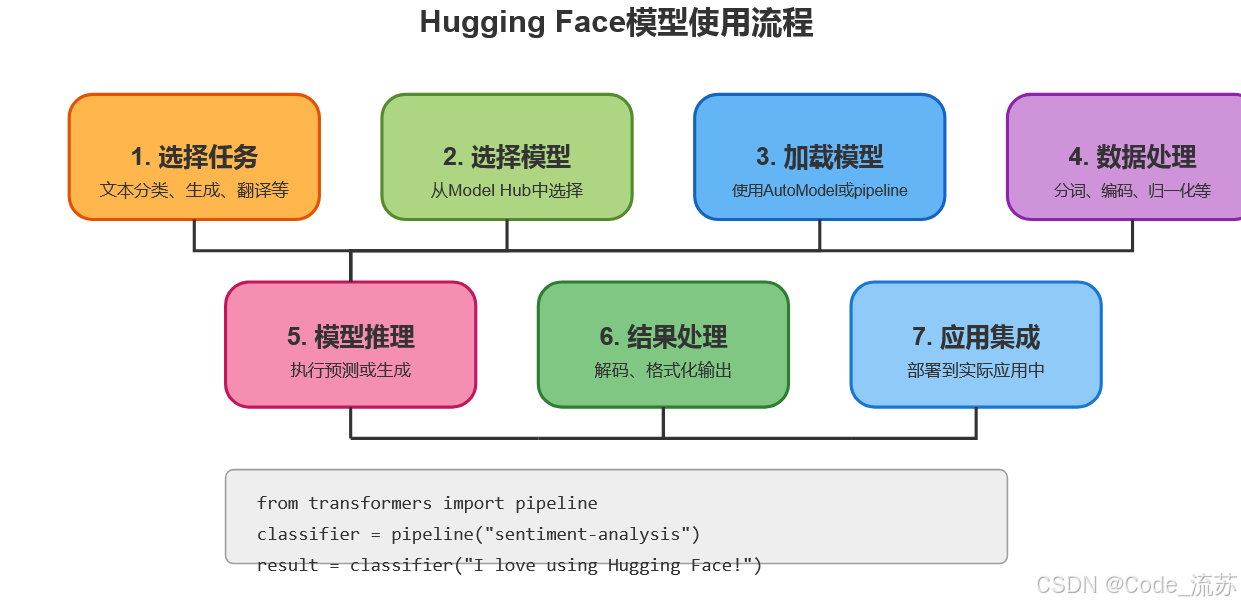
1. 创建账号和基本使用
要开始使用 Hugging Face ,首先需要在Hugging Face官网创建一个账号。
创建账号后,你可以:
- 浏览和下载模型
- 上传和分享自己的模型
- 使用Spaces创建应用
- 参与社区讨论和协作
2. 使用预训练模型
Hugging Face的主要优势之一是提供了大量预训练模型,只需几行代码即可使用。以下是一个使用预训练模型进行情感分析的示例:
from transformers import pipeline
# 初始化情感分析pipeline
sentiment_analyzer = pipeline("sentiment-analysis")
# 分析文本情感
result = sentiment_analyzer("我非常喜欢Hugging Face提供的工具,它们简单易用且功能强大!")
print(result)
# 输出: [{'label': 'POSITIVE', 'score': 0.9998}]
对于需要更多控制的情况,可以单独加载模型和分词器:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
# 加载预训练的情感分析模型和分词器
model_name = "distilbert/distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# 处理输入文本
text = "Hugging Face使机器学习变得更加容易!"
inputs = tokenizer(text, return_tensors="pt")
# 模型推理
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
3. 微调模型的基本步骤
当预训练模型不能完全满足特定任务需求时,可以对模型进行微调。微调可以使预训练模型适应特定任务,只需要使用一个较小的专门数据集。与从头训练模型相比,这种方法需要的数据和计算资源要少得多,这使得它成为许多用户更容易获得的选择。
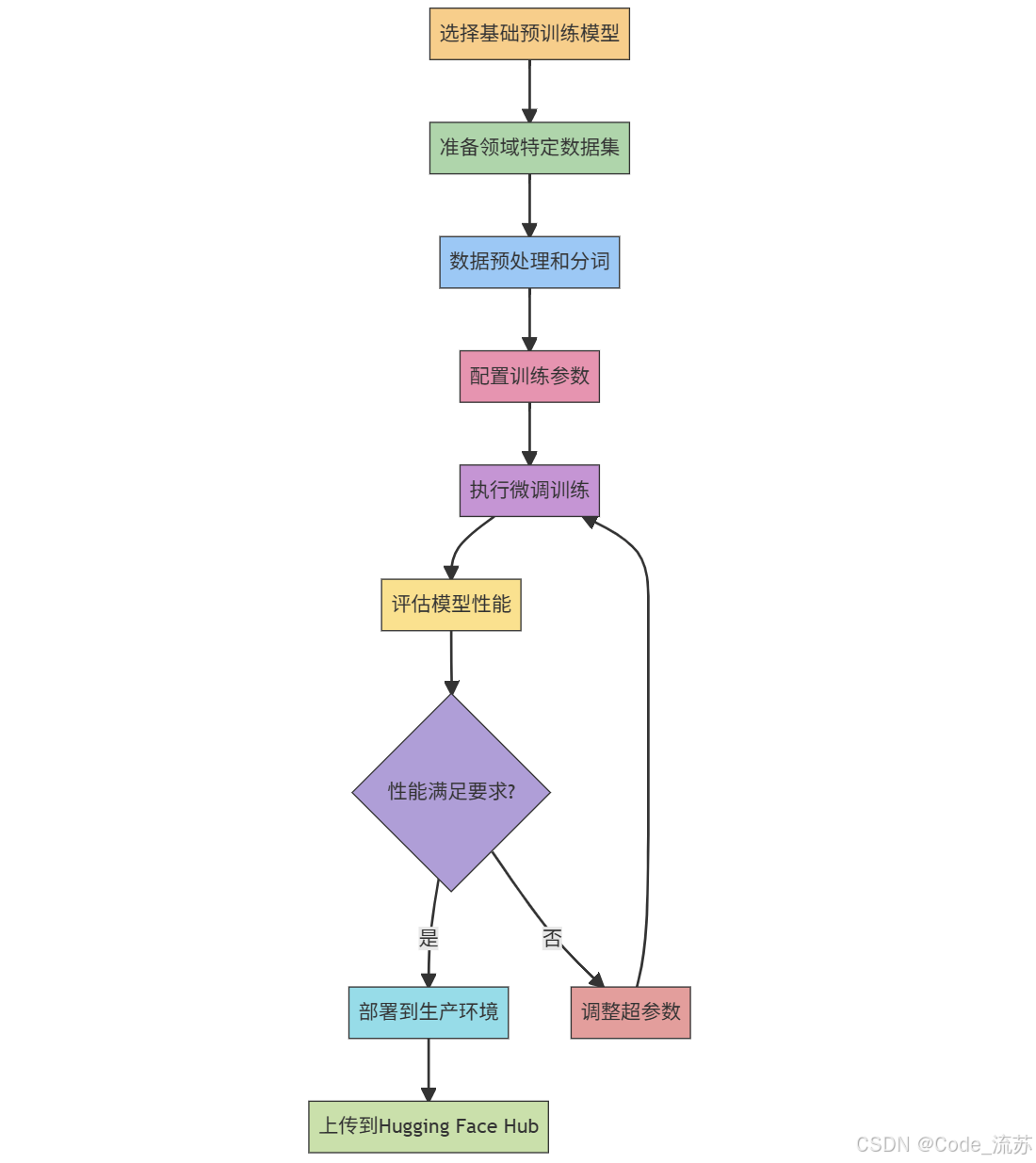
以下是使用Hugging Face的Trainer API微调模型的基本步骤:
from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments
from datasets import load_dataset
# 1. 加载数据集
dataset = load_dataset("yelp_review_full")
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
# 2. 数据预处理
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 3. 加载模型
model = AutoModelForSequenceClassification.from_pretrained(
"google-bert/bert-base-cased", num_labels=5
)
# 4. 定义训练参数
training_args = TrainingArguments(
output_dir="my_yelp_classifier",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
push_to_hub=True,
)
# 5. 创建Trainer实例并开始训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
)
trainer.train()
# 6. 保存模型到Hugging Face Hub
trainer.push_to_hub()
四、Hugging Face的应用场景
1. NLP应用
自然语言处理是Hugging Face最初和最强大的应用领域,包括:
- 文本生成:通过GPT等模型生成创意文本、故事或代码
- 文本分类:情感分析、主题分类、垃圾邮件识别等
- 问答系统:构建能够回答用户问题的AI系统
- 文本摘要:自动生成长文本的简洁摘要
- 机器翻译:实现跨语言的文本翻译
- 命名实体识别:识别文本中的人名、地名、组织名等实体
2. 计算机视觉应用
随着Hugging Face不断扩展,它的计算机视觉能力也在快速增长:
- 图像分类:识别图像中的对象或场景
- 目标检测:检测和定位图像中的多个对象
- 图像分割:将图像分割为不同的语义区域
- 图像生成:使用Stable Diffusion等模型生成图像
- 图像字幕生成:为图像生成描述性文本
使用示例:
from transformers import pipeline
# 初始化图像分类pipeline
image_classifier = pipeline("image-classification")
# 对图像进行分类
result = image_classifier("path/to/your/image.jpg")
print(result)
3. 多模态应用
多模态模型是Hugging Face平台上增长最快的领域之一,它们能够处理多种类型的数据:
- 图文理解:理解图像和相关文本之间的关系
- 视觉问答:回答关于图像内容的问题
- 文本到图像生成:根据文本描述生成对应的图像
- 音频转录:将语音转换为文本
- 多模态检索:根据一种模态查找另一种模态的内容
最近,Hugging Face推出了开源的SmolVLM视觉语言模型,专注于效率,SmolVLM-256M被称为世界上最小的视觉语言模型。这表明Hugging Face正在积极推动多模态AI的发展和普及。
五、Hugging Face的最新发展与未来趋势
1. 最新功能和模型
Hugging Face平台在2024-2025年推出了多项重要的功能和模型:
- 扩展了部署基础设施,简化了从实验模型到生产系统的转换。推理API通过标准化的REST端点提供基于云的模型访问
- 推出了SmolVLM-256M,这是世界上最小的视觉语言模型,大幅降低了计算成本
- 推出了Test-Time Compute Scaling技术,帮助小型语言模型超越更大的AI模型
- LeRobot平台扩展,为自动驾驶机器提供训练数据
2. 与行业巨头的合作
Hugging Face正与多家科技巨头建立战略合作关系:
- 2023年2月,宣布与亚马逊网络服务(AWS)合作,使AWS客户能够使用Hugging Face的产品
- 2023年8月的D轮融资中,Salesforce领投,Google、Amazon、Nvidia、AMD、Intel、IBM和Qualcomm等公司参与投资
- 2024年6月,与Meta和Scaleway一起为欧洲初创公司推出AI加速器计划
3. 未来发展方向
Hugging Face的未来发展方向包括:
- 深入扩展计算机视觉、多模态AI和强化学习等领域,同时加强企业解决方案
- 机器人技术领域的拓展,如收购Pollen Robotics
- 降低AI模型的计算需求,使其能在更多设备上运行
- 推动AI民主化,使更多人能够访问和使用AI技术
- 加强开源社区建设,促进知识共享和协作
六、总结与建议
Hugging Face已经成为AI领域最重要的开源平台之一,它通过提供易用的工具和丰富的资源,大大降低了AI技术的使用门槛。无论是AI研究人员、开发者,还是企业用户,都能从Hugging Face平台获益。
对于想要开始使用Hugging Face的开发者,我建议:
- 从pipeline开始:使用简单的pipeline API快速上手
- 探索模型库:浏览Model Hub找到适合自己任务的预训练模型
- 学习微调技术:通过微调使模型更好地适应特定任务
- 参与社区:加入Hugging Face社区,分享经验和学习他人的工作
- 关注新发展:持续关注Hugging Face的新模型和功能
随着AI技术的不断发展,Hugging Face平台也将持续演进。通过拥抱开源和协作,Hugging Face正在推动人工智能技术走向更加开放、普及和民主化的未来。
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)


















 3286
3286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











