






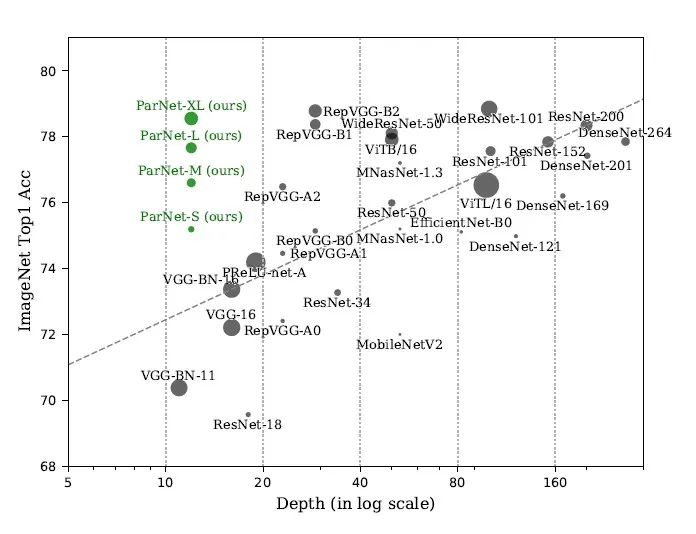
【导读】自从2012年深度学习兴起以来,深度,宽度,多尺度,分辨率,group数目,注意力模块等等都是影响卷积神经网络性能的关键因素。因此,后面大多网络比如:VGGNet、HighwayNet、ResNet、IResNet等通过增加网络的深度来提高性能,而Inception系列则是从宽度层面逐渐提高卷积神经网络性能. 详细解读见一文详解Inception家族的前世今生(从InceptionV1-V4、Xception)附全部代码实现 ResNeXt则从增加Group数量的方法来提高网络模型性能。SENet、CBAM、SKNet则是引入注意力模块来提升卷积神经网络模型性能。而本文将主要介绍首个仅需12层(从depth维度来看)的网络就能在ImageNet上达到80.7%的Top-1准确率,它通过利用并行子结构成功地构建了一个高性能的「非深度」神经网络,该网络在 ImageNet上Top-1 Acc 达到了80.7%、在 CIFAR10 上达到96.12%、在 CIFAR100 上达到了81.35%的top-1 准确率。在进一步迁移到下游任务时,它在标准公开数据集MS-COCO 上达到 48% AP .

论文地址:https://arxiv.org/abs/2110.07641
代码地址:https://github.com/murufeng/awesome_lightweight_networks/blob/main/light_cnns/mobile_real_time_network/parnet.py
本文提出了一种新架构ParNet:用较浅的网络层数实现了较高的模型性能 。ParNet包含用于处理不同分辨率输入的并行子结构,我们将这些并行子结构称之为streams 。不同streams的特征在网络的后期进行融合,融合的特征将用于下游任务。另外,在ParNet block中,作者为了解决原始的3x3卷积感受野范围受限的问题,主要提出了以下两点方案:
使用类似Rep-VGG的block模块,并构建SSE 模块来增强感受野.
为了增强网络的非线性表达能力,使用SiLU激活函数替代了ReLU.
ParNet架构示意图如下:
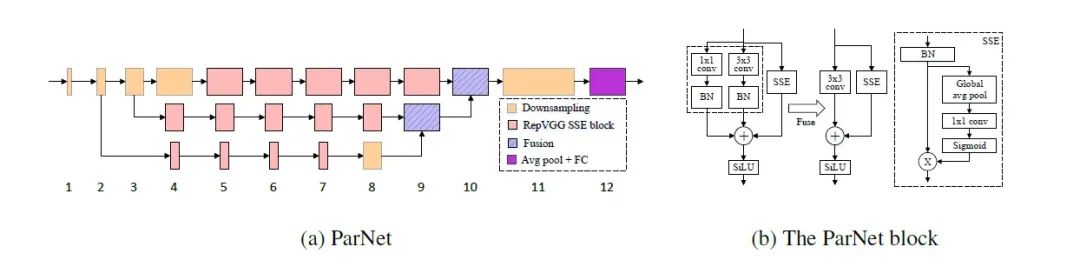
除了RepVGG-SSE块的输入和输出具有相同的大小外,ParNet还包含下采样和融合块。模块降低分辨率并增加宽度以实现多尺度(multi-scale)处理,而融合块主要用来组合来自多个分辨率的信息,有助于减少推理期间的延迟。为了在小深度下实现高性能,作者采用并行计算的方式来加快神经网络的推理过程,具体表现为:通过增加宽度、分辨率和流数量来扩展ParNet的结构。具体如下:
在降采样 block 中添加了一个与卷积层并行的单层 SE 模块。
在 1×1 卷积分支中添加了 2D 平均池化。
融合 block 额外包含了一个串联(concatenation)层。由于串联,融合 block 的输入通道数是降采样 block 的两倍。
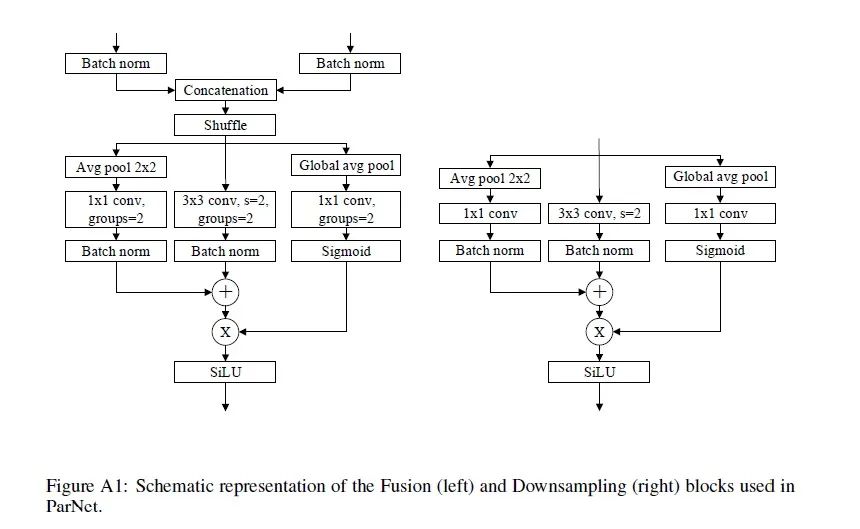
其中降采样和融合 block 的示意图如下所示。
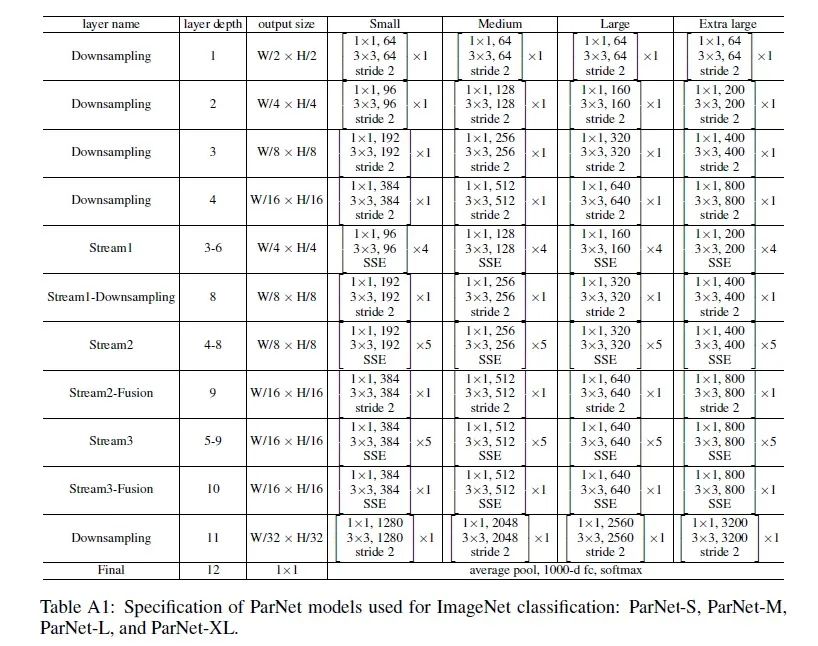
网络结构如下:
代码实现如下:
import torch
from light_cnns import parnet_s
model = parnet_s()
model.eval()
print(model)
input = torch.randn(1, 3, 256, 256)
y = model(input)
print(y.size())实验结果展示
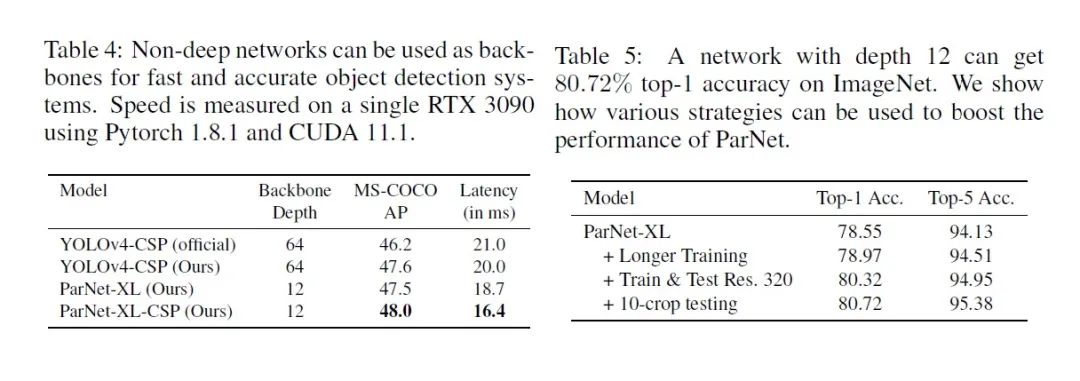
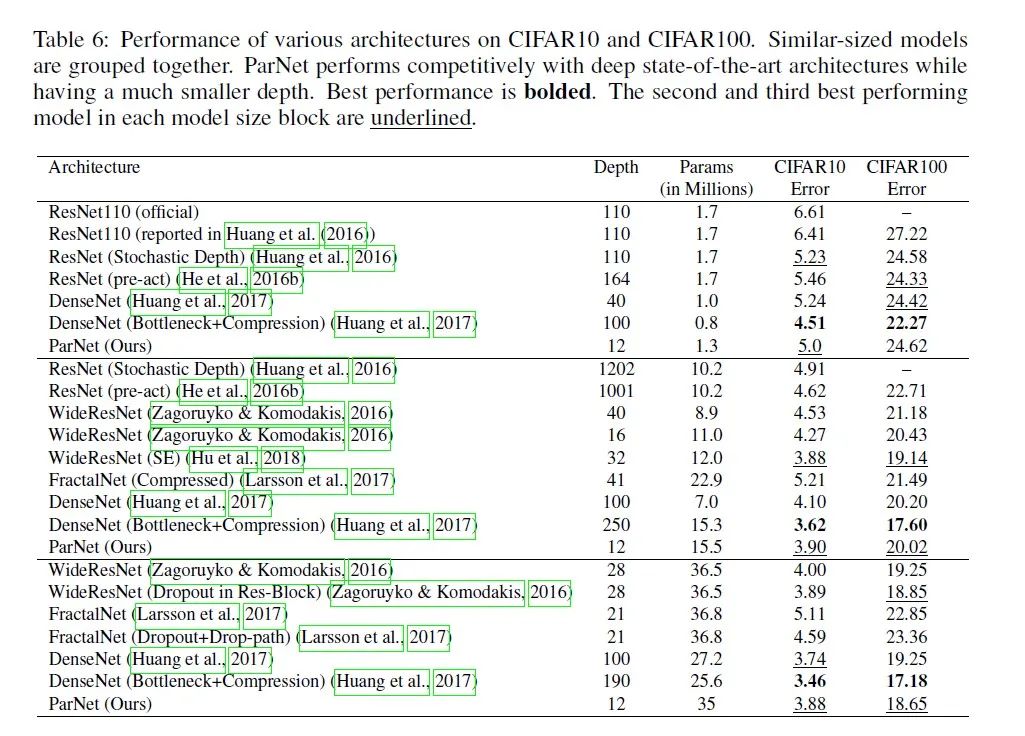
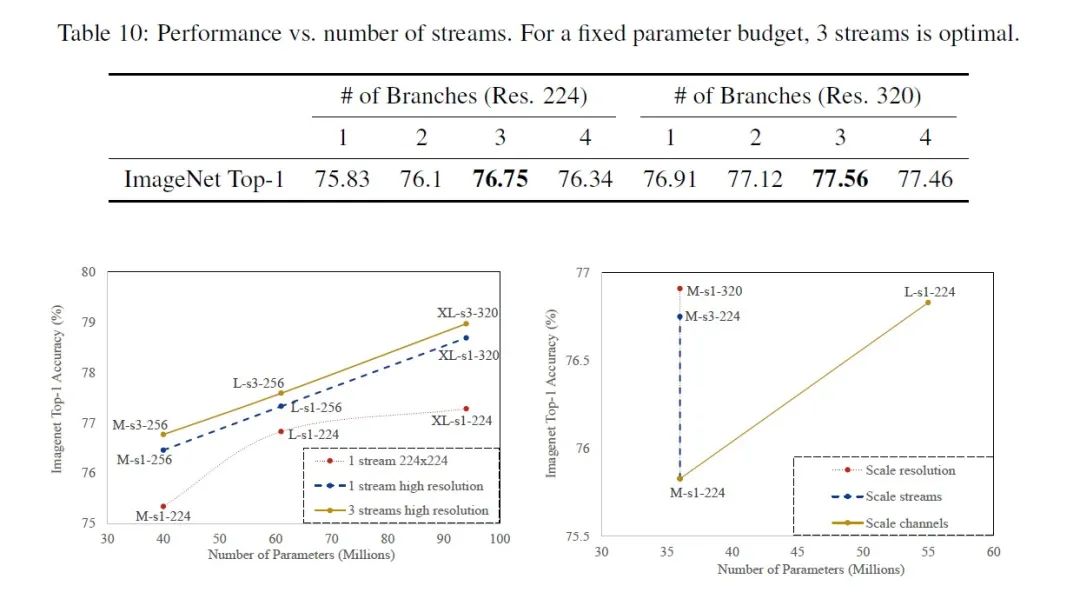
后续我们将针对具体视觉任务集成更多的轻量级网络架构。希望本项目既能让深度学习初学者快速入门,又能更好地服务科研学术和工业研发社区。
后续将持续更新模型轻量化处理的一系列方法,包括:剪枝,量化,知识蒸馏等等,欢迎大家Star和Follow.
Github地址:https://github.com/murufeng/awesome_lightweight_networks
推荐阅读
欢迎大家加入DLer-计算机视觉&Transformer群!
大家好,这是计算机视觉&Transformer论文分享群里,群里会第一时间发布最新的Transformer前沿论文解读及交流分享会,主要设计方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、视频超分、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如Transformer+上交+小明)

👆 长按识别,邀请您进群!















 2178
2178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









