







目录
引言
在自然语言处理(NLP)、计算机视觉(CV)等领域,预训练(Pre-training)已成为构建高性能模型的 “黄金法则”。
从 BERT 到 GPT-4,从 ViT 到 CLIP,预训练技术推动着人工智能的边界不断拓展。
一、预训练是什么?
1.1 定义
预训练(Pre-training)指在大规模无标注或弱标注数据集上,通过自监督学习(Self-supervised Learning)或弱监督学习(Weakly-supervised Learning)的方式,预先训练一个通用模型,使其学习到数据的内在规律与特征表示能力。
随后,该模型可通过微调(Fine-tuning)或提示(Prompting)适配到下游任务。

预训练与微调
1.2 核心思想
- 知识蒸馏:模型通过海量数据学习通用知识(如语言结构、视觉概念)。
- 迁移学习:将通用知识迁移到特定任务,减少对标注数据的依赖。
1.3 典型案例
- NLP:BERT(掩码语言模型)、GPT(自回归语言模型)
- CV:ViT(图像块重建)、CLIP(图文对比学习)
- 多模态:Flamingo(视频 - 文本对齐)
二、为什么要预训练?
2.1 解决数据稀缺问题
- 标注成本高:人工标注大规模数据集耗时费力(如医学图像标注)。
- 长尾任务需求:许多任务(如小语种翻译)缺乏足够标注数据。
2.2 提升模型泛化能力
- 学习通用特征:通过大规模数据捕捉数据分布规律(如词语共现、物体纹理)。
- 避免过拟合:预训练模型参数初始化更优,微调时需更少样本。
2.3 实现参数高效复用
- 参数共享:同一预训练模型可服务于多个下游任务(如文本分类、实体识别)。
- 降低计算成本:微调预训练模型比从头训练节省 90% 以上算力。
三、预训练方法论
3.1 模型架构选择
- Transformer:主流架构(如 BERT、GPT),擅长捕捉长距离依赖。
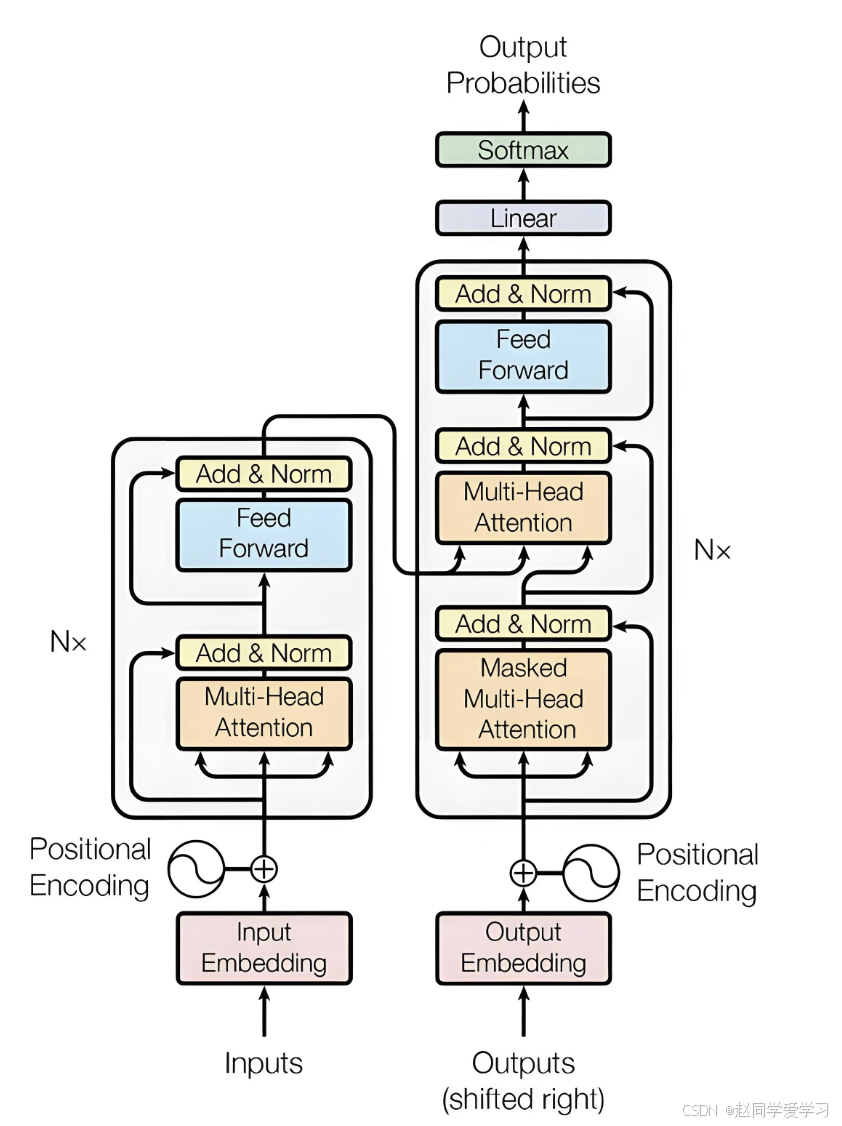
transformer架构图
- 卷积网络:CV 领域常用(如 ResNet 预训练用于图像分类)。
- 混合架构:如 Vision Transformer(ViT)结合 CNN 与 Transformer。
3.2 训练任务设计
- 掩码语言建模(MLM):随机遮盖文本片段,预测被遮盖内容(BERT)。
- 自回归预测(AR):根据上文预测下一个词(GPT 系列)。
- 对比学习(Contrastive Learning):拉近正样本对,推开负样本对(CLIP)。
- 多任务学习:联合优化多个预训练目标(如 T5 同时处理翻译、摘要等)。
3.3 优化策略
- 动态掩码:避免模型记忆固定掩码模式。
- 梯度累积:解决显存不足问题。
- 混合精度训练:FP16/FP32 混合加速训练。
四、数据来源与处理
4.1 数据来源
- 互联网文本:Common Crawl(GPT-3 数据源)、Wikipedia、社交媒体。
- 书籍与论文:如 BookCorpus(BERT 训练数据)。
- 多模态数据:LAION-5B(图文对)、YouTube 视频(含音频与字幕)。
- 合成数据:使用规则或模型生成(如代码数据 GitHub Copilot)。
4.2 数据预处理

典型的预训练数据预处理流程图
- 清洗:去除重复、低质、有害内容(如暴力、歧视文本)。
- 分词:Byte-Pair Encoding(BPE)、SentencePiece。
- 去噪:过滤乱码、广告、非目标语言内容。
- 平衡:避免数据偏向某些领域(如科技类文本过多)。
4.3 数据规模与模型性能
- Scaling Law:模型性能随数据量、参数量、计算量呈幂律提升。
- 临界点效应:小规模数据下性能提升快,后期需指数级数据增长。
五、预训练的应用与挑战
5.1 典型应用场景
- NLP:文本生成、问答系统、情感分析。
- CV:图像分类、目标检测、视频理解。
- 跨模态:图文检索、视频字幕生成。
5.2 前沿挑战
- 数据偏差:预训练数据可能隐含社会偏见(如性别、种族)。
- 能耗问题:千亿参数模型训练需数万 GPU 小时。
- 知识更新:如何让模型持续学习新知识(如 ChatGPT 知识截止 2023 年)。
六、未来趋势
- 更大规模与稀疏化:MoE(Mixture of Experts)架构降低计算成本。
- 多模态统一建模:如谷歌 PaLM-E 实现视觉 - 语言 - 机器人控制联合训练。
- 高效微调技术:LoRA、Adapter 减少微调参数量。
- 可解释性与伦理:构建透明、可控的预训练模型。
结语
预训练技术正推动 AI 从 “任务专用” 迈向 “通用智能”。尽管面临数据、算力、伦理等挑战,其在降低 AI 应用门槛、释放数据价值方面的潜力无可替代。未来,随着多模态学习、高效训练算法的进步,预训练将继续引领深度学习的新范式。
参考资料
- [1] Devlin et al. "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding", 2018.
- [2] Brown et al. "Language Models are Few-Shot Learners", 2020.
- [3] Radford et al. "Learning Transferable Visual Models From Natural Language Supervision", 2021.


















 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











