







1.分析网站
在这个页面获取第1-10集的URL地址和名称:第01集-第10集,因为存在多个播放路径,所有URL和名称也都是多个,直接获取前10就行
2. 分析每集
2.1 在浏览器打开第一集,直接点击播放后
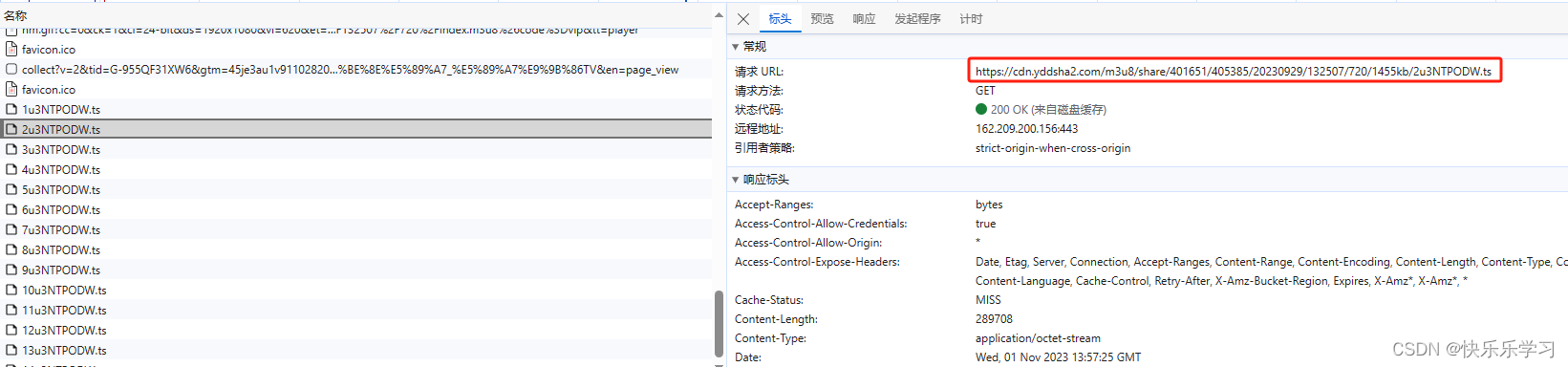
点击播放视频后,抓包抓到了多个ts请求,这个ts请求就是获取每一段小视频,然后组成了一集电视剧,这个时间就需要获取到每个ts请求的url
2.2 分析打开第一集后那些请求是需要使用的
打开抓捕工具,查看页面的HTML信息,发现iframe元素的src的url地址与此地址的前半部分相似,所有我们需要获取到这个url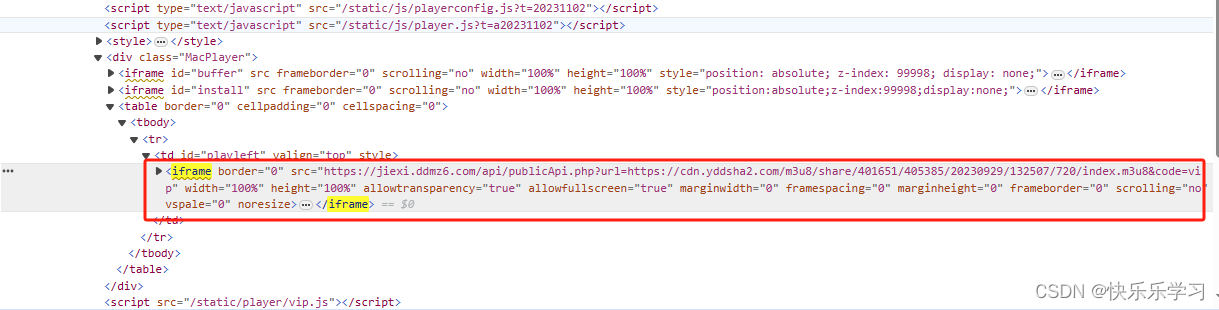
当查看到这个index请求时,发现它的响应数据与前面每个ts的名称一直,所有就需要找到这个请求的URL和携带的数据
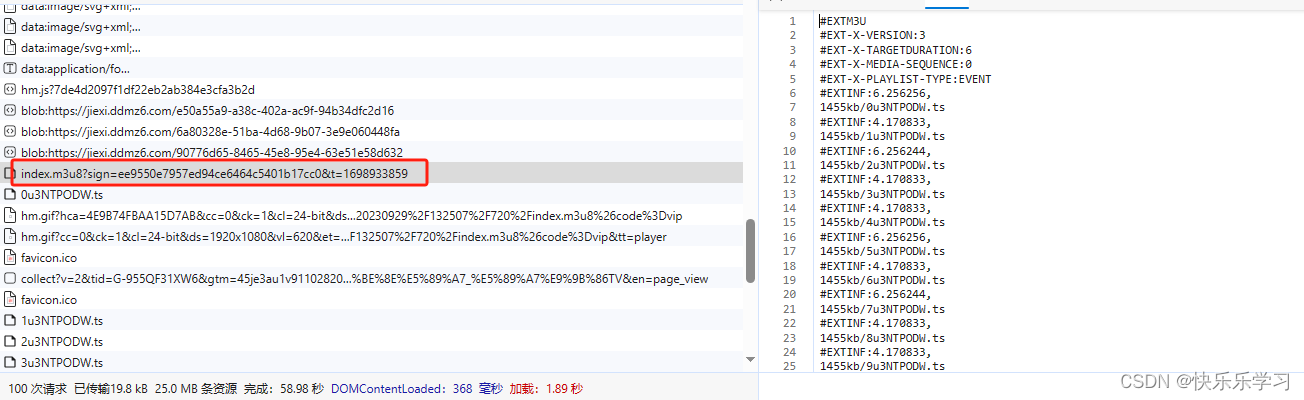
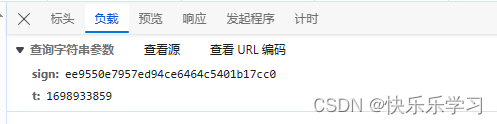

通过分析url,发送请求需要携带sign和t两个参数,我们就需要再次在其他请求中继续寻找
当看到这个public请求时,发现它的响应体中有一个url,url中刚好携带了sign和t两个参数

分析这个请求,我们发现它发起请求的url与页面HTML元素iframe中的src的url一致,携带的参数也是在URL内,所以只需要进行分解数据进行发起请求
3.总结如下
1. 打开网站,获取每集电视剧URL地址和每集名称
2. 获取public请求中的参数与URL地址,发送public请求
3. 从第二步返回的响应体中获取index请求的中的参数
4. 发送index请求,获取ts信息
5. 发送ts请求,下载视频
4. 代码如下
from selenium import webdriver
import aiohttp, asyncio, requests, re, json, os, shutil
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
def web(url):
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options) # 设置无头模式
driver.get(url)
# 切入iframe
two_frame = driver.find_element(By.XPATH, "//td[@id='playleft']/iframe")
html_content = two_frame.get_attribute("outerHTML") # 提取iframe的元素信息,从中获取URL
return re.findall('src="(.*?)" width=', html_content)[0]
async def task(ts_li, head_url, set_file_path):
async with aiohttp.ClientSession() as session:
tasks = []
for ts in ts_li:
if ".ts" in ts:
tasks.append(asyncio.ensure_future(download_m3u8(session, ts, head_url, set_file_path)))
await asyncio.gather(*tasks)
async def download_m3u8(session, ts, head_url, set_file_path):
url = f"{head_url}{ts}"
async with session.get(url=url) as res:
mp4 = await res.content.read()
mp4_name = ts.replace(r"/", "")
mp4_path = f"{os.path.join(set_file_path, mp4_name)}"
with open(mp4_path, "wb") as file:
file.write(mp4)
def run():
initial_url = "https://www.ijujitv.cc/detail/16724.html"
res = requests.get(url=initial_url).text
ser_url = re.findall('href="(.*?)">第', res)[0:10] # 提取每集电视剧的URL
collect_name_li = re.findall('第\d{2}集', res)[0:10] # 提取电视剧每集的名称
excel_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), "路西法第四季")
if not os.path.exists(excel_path):
os.mkdir(excel_path) # 创建保存视频的文件夹
print("路西法第四季 创建成功")
# 循环遍历每一集的URL
for index, url in enumerate(ser_url):
set_file_path = os.path.join(excel_path, collect_name_li[index]) # 每集电视剧的保存路径
if not os.path.exists(set_file_path):
os.mkdir(set_file_path)
print(collect_name_li[index], "创建成功")
u = f"https://www.ijujitv.cc{url}"
requests.get(url=u) # 向每集的url发送请求
publicApi_url = web(u) # 获取https://jiexi.ddmz6.com/api/publicApi.php?url
head_url = re.findall('url=(.*?)index', publicApi_url)[0] # 提取每节短视频url前半部分
publicApi_param = {
"url": re.findall('url=(.*?)&', publicApi_url)[0],
"code": "vip"
}
header = {
"Referer": "https://www.ijujitv.cc/"
}
url = publicApi_url.replace("amp;", "")
# 参数需要json格式化
data = requests.get(url=url, params=json.dumps(publicApi_param), headers=header).text
index_url = re.findall("var url = '(.*?)';", data)[0]
li = index_url.split("=")
index_param = {
"sign": li[1].split("&")[0],
"t": li[2]
}
# 参数需要格式化
ts = requests.get(url=index_url, params=json.dumps(index_param)).text
ts_file = os.path.join(set_file_path, "index.m3u8")
with open(ts_file, "w", encoding="utf-8") as f:
f.write(ts.replace("/", ""))
loop = asyncio.get_event_loop()
loop.run_until_complete(task(ts.split("\n"), head_url, set_file_path))
merge(collect_name_li)
def merge(collect_name_li):
'''
视频合并
:return:
'''
# 进入到下载后ts 的目录
file = os.path.dirname(__file__)
for collect_name in collect_name_li:
mp4_path = fr"{file}\路西法第四季\{collect_name}"
os.chdir(mp4_path)
# 视频合并的命令
os.system(fr'ffmpeg -i index.m3u8 -c copy {mp4_path}.mp4')
for collect_name in collect_name_li:
# 删除保存视频得文件夹,这会在删除最后一个文件时会删除失败
shutil.rmtree(fr"{file}\路西法第四季\{collect_name}")
if __name__ == '__main__':
run()















 2763
2763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









