







1. 登录
def login():
"""
登录
:return:
"""
url = "https://passport.17k.com/ck/user/login"
data = {
"loginName": "18291962907",
"password": "cjl2000321"
}
data = requests.post(url, data=data).json()
if data['data']['nickname'] == "又大又白又圆又软":
print("登录成功")
return True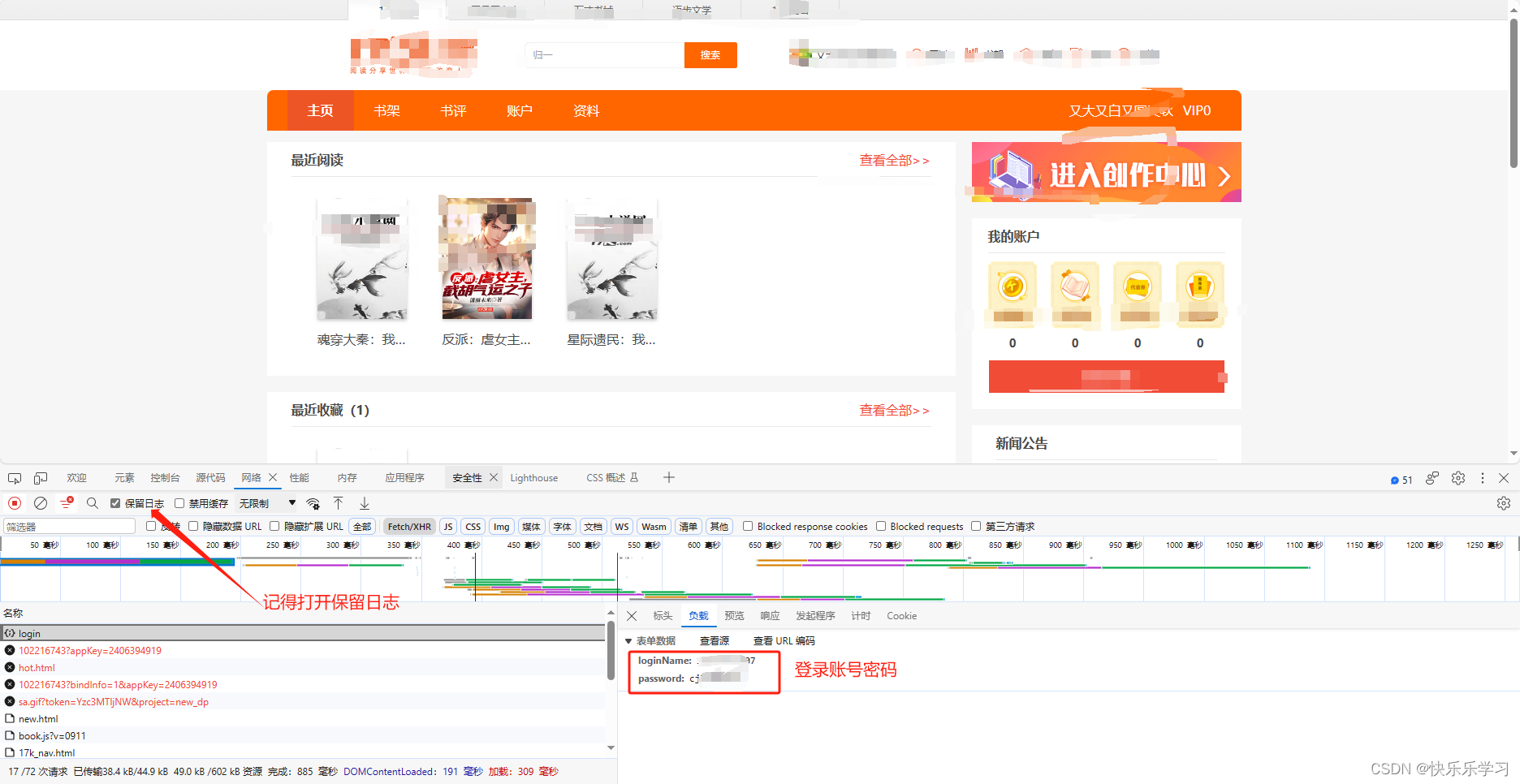
2. 选择完结和全本免费的书籍
def book_type():
"""
获取书名与URL
:return:
"""
book_dict = {}
url = 'https://www.17k.com/all/book/2_0_0_0_3_0_1_0_1.html'
res = requests.get(url).text
for value in re.findall('<a target="_blank" href="//www.17k.com/book/(.*?)</a>', res):
data = value.split('" >')
book_dict[data[1]] = data[0]
return book_dict
# 选择已完本、免费的书籍
def screen():
"""
选择已完本、免费的书籍
:return: 返回book_type函数
"""
url_li = {"已完本": "https://static.17k.com/js/mod/WXShare.js?v=0911",
"只看免费": "https://static.17k.com/js/mod/WXShare.js?v=0911"}
param = {
"v": "0911"
}
for key, url in url_li.items():
data = requests.get(url, params=param).text
if "设置成功" in data:
print(key, "设置成功")
return book_type()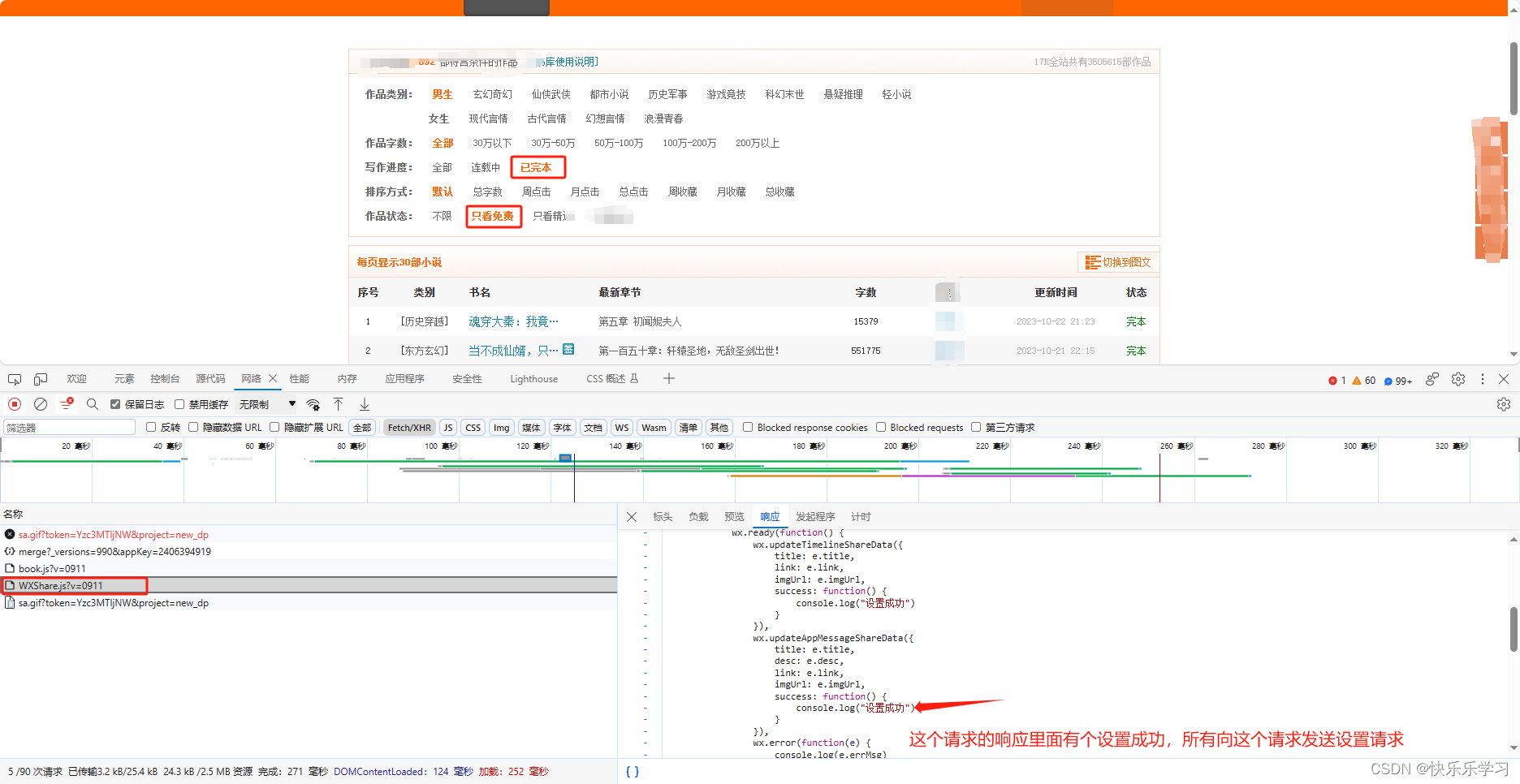
3. 获取筛选后这个页面的所有书籍的名称和URL
def get_book_id(li):
"""
进入书籍页,获取详情页url地址
:param li:
:return:
"""
url = f"https://www.17k.com/book/{li}"
res = requests.get(url)
res.encoding = 'utf-8'
for book_detail_url in re.findall(r'href="(.*?)"', res.text):
if len(book_detail_url) == 18 and "list" in book_detail_url:
return book_detail_url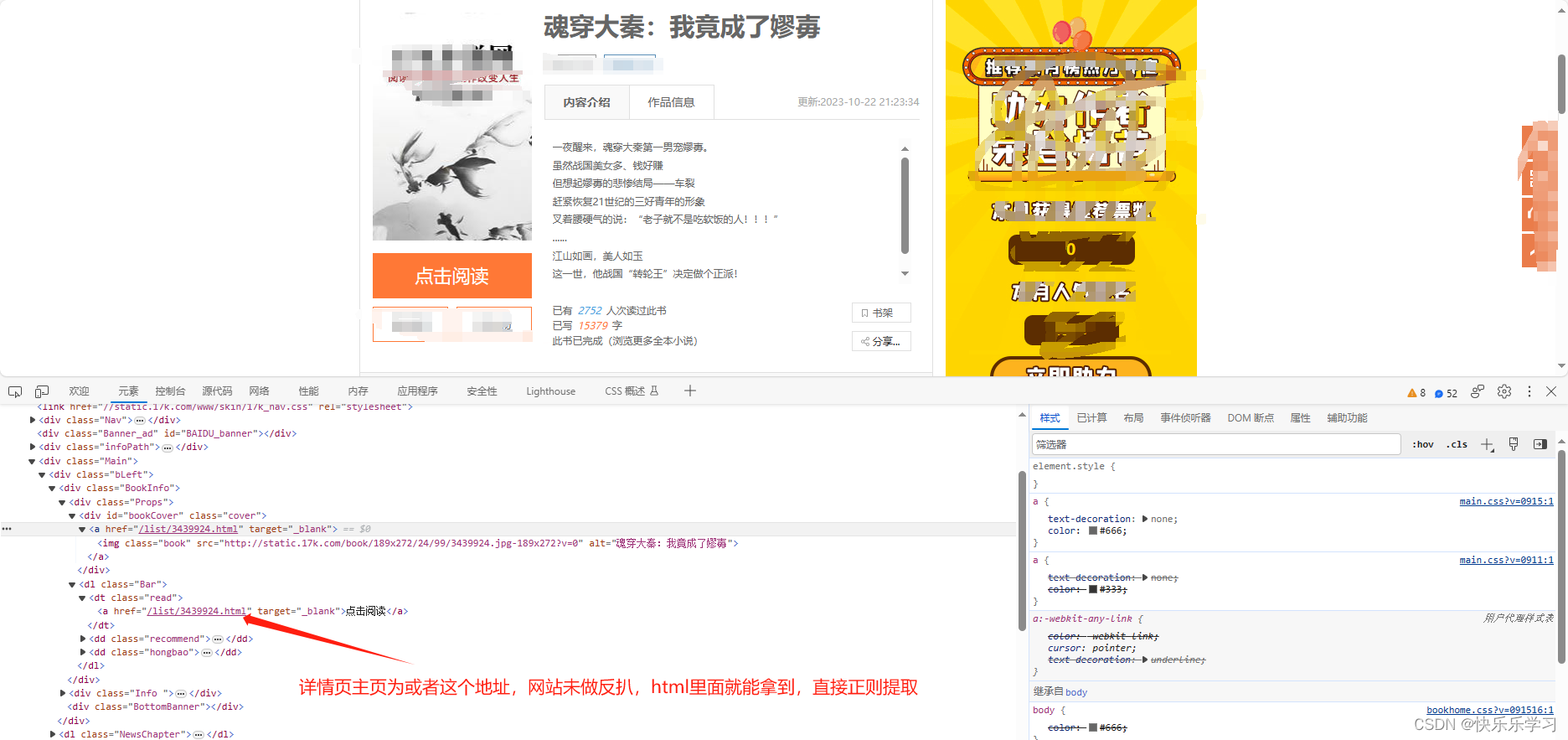
4. 进入书籍详情页点击阅读获取所有章节名称和URL
def get_section_url(book_detail_url):
"""
获取章节链接
:param book_detail_url:
:param url_set:
:return:
"""
chapter_dict = {} # 存放章节名称和URL
url = f"https://www.17k.com{book_detail_url}"
res = requests.get(url, headers=headers)
res.encoding = 'utf-8'
chapter_name = re.findall('title="(.*?)&', res.text) # 章节名称
chapter_url = re.findall('href="/chapter(.*?)"', res.text) # 章节URL
for index, value in enumerate(chapter_name):
chapter_dict[value] = chapter_url[index]
return chapter_dict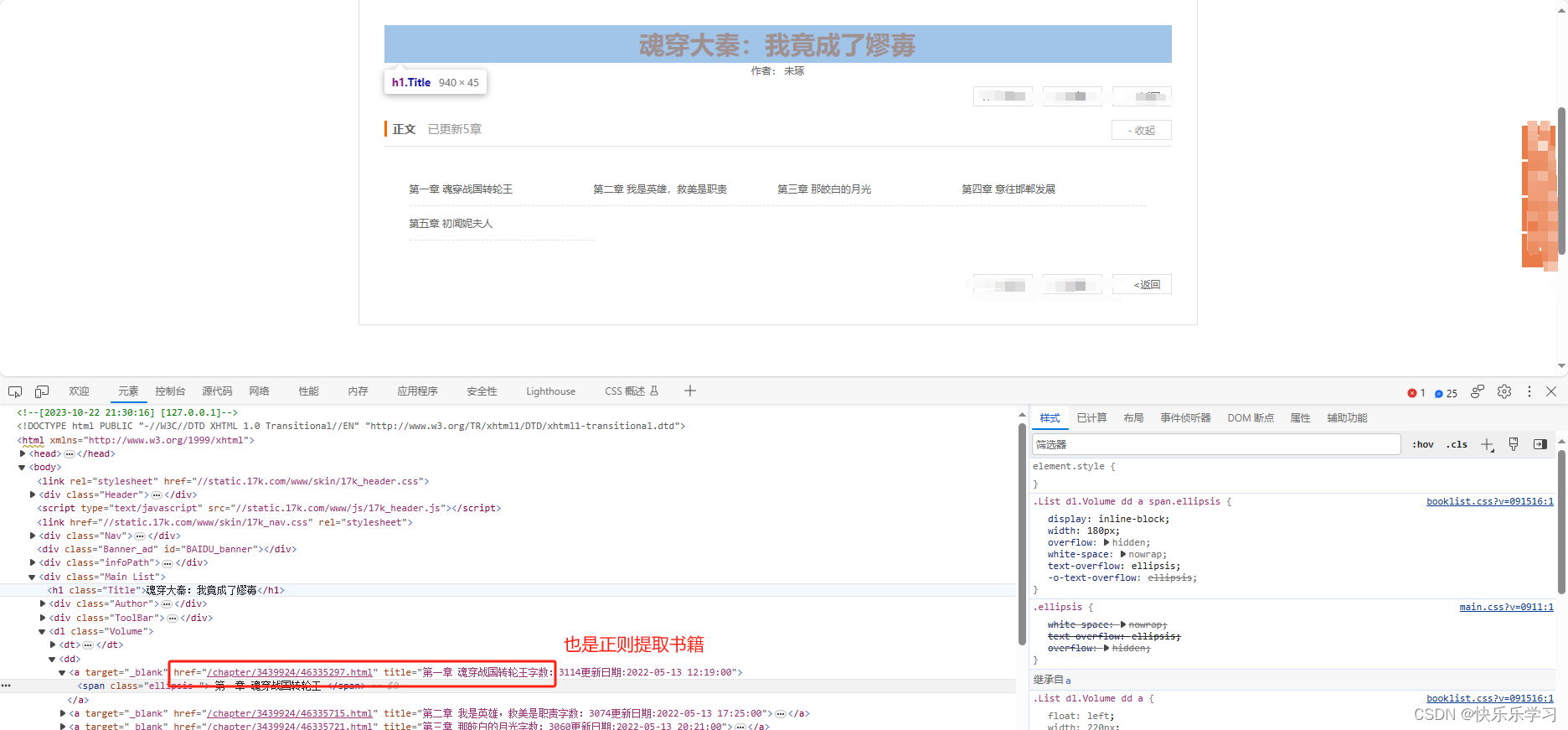
5. 下载书籍
用异步下载很快,秒完成
async def fetch(chapter_dict, book_path):
async with aiohttp.ClientSession() as session:
tasks = [asyncio.create_task(download_book(session, name, url, book_path)) for name, url in chapter_dict.items()]
await asyncio.wait(tasks)
async def download_book(session, name, url, book_path):
url = f"https://www.17k.com/chapter{url}"
async with session.get(url, headers=headers) as res:
res.encoding = 'utf-8'
data = await res.text()
paragraphs = re.findall(r'<div class="p">(.*?)</div>', data, re.DOTALL) # 内容
file = os.path.join(book_path, name)
with open(f"{file}.txt", mode="w", encoding="utf-8") as fp:
fp.write(re.findall('<h1>(.*?)</h1>', data)[0]) # 章节名称
fp.write("\n".join(re.findall('<p>(.*?)</p>', paragraphs[0].strip())))
fp.close()6.完整代码
"""
#!/usr/bin/env python
# -*- coding:utf-8 -*-
@Project : 图书信息爬取2.py
@File : 17k小说.py
@Author : 18291962907
@Time : 2023/10/23 0:21
"""
import requests, re, os, asyncio, aiohttp
excel_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), "17K小说")
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.61",
"Cookie": "GUID=b42b4087-dc18-4711-854b-ed1509d29600; c_channel=0; c_csc=web; Hm_lvt_9793f42b498361373512340937deb2a0=1697815882,1697991226,1698066050; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F03%252F43%252F67%252F102216743.jpg-88x88%253Fv%253D1697991806000%26id%3D102216743%26nickname%3D%25E5%258F%2588%25E5%25A4%25A7%25E5%258F%2588%25E7%2599%25BD%25E5%258F%2588%25E5%259C%2586%25E5%258F%2588%25E8%25BD%25AF%26e%3D1713618111%26s%3D8d33aa31493ead9d; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22102216743%22%2C%22%24device_id%22%3A%2218b4db665e33c3-0415888f7d54dd-745d5774-2073600-18b4db665e4e62%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%22b42b4087-dc18-4711-854b-ed1509d29600%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1698071298"
}
def lord_file():
if not os.path.exists(excel_path):
os.makedirs(excel_path)
else:
print("已存在")
def book_file(book_name):
"""创建书籍文件夹"""
book_path = os.path.join(excel_path, book_name)
os.makedirs(book_path)
print(book_name, "创建成功")
return book_path
# 登录
def login():
"""
登录
:return:
"""
url = "https://passport.17k.com/ck/user/login"
data = {
"loginName": "18291962907",
"password": "cjl2000321"
}
data = requests.post(url, data=data).json()
if data['data']['nickname'] == "又大又白又圆又软":
print("登录成功")
return True
# 获取书名与URL
def book_type():
"""
获取书名与URL
:return:
"""
book_dict = {}
url = 'https://www.17k.com/all/book/2_0_0_0_3_0_1_0_1.html'
res = requests.get(url).text
for value in re.findall('<a target="_blank" href="//www.17k.com/book/(.*?)</a>', res):
data = value.split('" >')
book_dict[data[1]] = data[0]
return book_dict
# 选择已完本、免费的书籍
def screen():
"""
选择已完本、免费的书籍
:return: 返回book_type函数
"""
url_li = {"已完本": "https://static.17k.com/js/mod/WXShare.js?v=0911",
"只看免费": "https://static.17k.com/js/mod/WXShare.js?v=0911"}
param = {
"v": "0911"
}
for key, url in url_li.items():
data = requests.get(url, params=param).text
if "设置成功" in data:
print(key, "设置成功")
return book_type()
# 进入书籍页,获取详情页url地址
def get_book_id(li):
"""
进入书籍页,获取详情页url地址
:param li:
:return:
"""
url = f"https://www.17k.com/book/{li}"
res = requests.get(url)
res.encoding = 'utf-8'
for book_detail_url in re.findall(r'href="(.*?)"', res.text):
if len(book_detail_url) == 18 and "list" in book_detail_url:
return book_detail_url
# 获取章节链接、章节名称
def get_section_url(book_detail_url):
"""
获取章节链接
:param book_detail_url:
:param url_set:
:return:
"""
chapter_dict = {} # 存放章节名称和URL
url = f"https://www.17k.com{book_detail_url}"
res = requests.get(url, headers=headers)
res.encoding = 'utf-8'
chapter_name = re.findall('title="(.*?)&', res.text) # 章节名称
chapter_url = re.findall('href="/chapter(.*?)"', res.text) # 章节URL
for index, value in enumerate(chapter_name):
chapter_dict[value] = chapter_url[index]
return chapter_dict
async def fetch(chapter_dict, book_path):
async with aiohttp.ClientSession() as session:
tasks = [asyncio.create_task(download_book(session, name, url, book_path)) for name, url in chapter_dict.items()]
await asyncio.wait(tasks)
async def download_book(session, name, url, book_path):
url = f"https://www.17k.com/chapter{url}"
async with session.get(url, headers=headers) as res:
res.encoding = 'utf-8'
data = await res.text()
paragraphs = re.findall(r'<div class="p">(.*?)</div>', data, re.DOTALL) # 内容
file = os.path.join(book_path, name)
with open(f"{file}.txt", mode="w", encoding="utf-8") as fp:
fp.write(re.findall('<h1>(.*?)</h1>', data)[0]) # 章节名称
fp.write("\n".join(re.findall('<p>(.*?)</p>', paragraphs[0].strip())))
fp.close()
# 启动函数
def run():
lord_file()
# 1.登录
login()
# 2.在书籍分类页选择已完成、全部免费得数据,并返回这些书籍得Name和URL,返回的结果字典:为键值对
data = screen()
# 3.循环遍历书籍Name和URL的字典
for book_name, book_url in data.items():
# 4. 判断是否存书籍Name的文件夹,不存在则创建,返回文件夹路径
book_path = book_file(book_name)
# 5. 进入书籍简介页面,获取详情页面URL
book_detail_url = get_book_id(book_url)
# 6. 获取不到时,跳过此次循环
if not book_detail_url:
continue
# 7. 获取书籍详情页的章节名称和章节URL地址
chapter_dict = get_section_url(book_detail_url)
# 8. 异步下载内容
asyncio.run(fetch(chapter_dict, book_path))
if __name__ == '__main__':
run()















 1019
1019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









