







mamba详解
0. 引言
在前三章中,我们已经探讨了 Mamba 的核心基础——状态空间模型(SSM),以及对 SSM 模型的离散化处理和并行化操作。我们还详细分析了 HiPPO 和 S4 等技术。本章将重点介绍 Mamba 框架中的一个创新组件:选择性状态空间模型。那么,让我们不多做停留,直接开始今天的内容探索吧。
给自己打个广告,如果您对 Transformer 还不太了解,欢迎访问我的博客专栏,其中包含了丰富的 NLP 入门内容。即使您不是NLP领域的学者,这些内容对您深入理解深度学习和神经网络也大有裨益。点击这里学习更多。
此外,如果您对图神经网络的了解还不够深入,我建议您先阅读相关基础知识。点击此处,都是我的个人理解,简单易懂。话不多说,那咱们就开始今天的学习吧。
1. 注意力机制
注意力机制一直是深度学习中的一个重要话题,特别是在模型需要集中关注输入数据的特定部分时。这一概念得到了 Transformer 的推广应用,是值得深入探讨的。首先,我们不能不提及传统 CNN 的局限性。
避不开传统CNN的局限性。
在传统的卷积神经网络(CNN)中,卷积核的权重在模型训练完成后是固定的。这些权重不依赖于输入数据的特定属性,而是通过训练数据学习到的通用特征探测器。因此,无论输入数据如何变化,卷积核的应用方式(即加权求和的方式)都保持不变。所以我们看到模型一个卷积核进技能仅仅用于对特定图案模式的提取,其能力是有限的。
你输入什么数据我都是按照固定的卷积核逻辑进行模式提取特征。
试图一招鲜吃遍天。
但是在变形金刚中, Transformer 中的注意力机制
相比之下,Transformer 模型通过引入查询(Query)、键(Key)和值(Value)的机制,实现了对输入数据的依赖性处理。每个输入元素都可以根据其他元素的相关性(通过查询和键的点积计算得出)动态地调整其贡献的权重。
注意这里多了一个attention矩阵这个矩阵是由输入和参数矩阵共同决定的。
这种机制使得Transformer能够根据输入数据的上下文信息灵活地调整其注意力焦点,从而提高了模型对输入变化的适应能力。
最大的不同就是你CNN输入任何图都是相同的模式提取。即同样的权重对不同的图。Transformer则是可以按照不同的话产生不同的注意力矩阵然后用这个矩阵去做特征提取。这就出现了本质的区别。
CNN还在用一样的东西对待全部的图。而Transformer已经学会了看人下菜碟。说白了就是多了一步利用输入数据去修感参数矩阵,从而实现看人下菜碟的能力。
正式一点说
最根本的区别在于,传统的 CNN 对任何输入都使用相同的特征提取方式,而 Transformer 能够根据不同的输入生成不同的注意力矩阵,进而调整其特征提取策略。这意味着 Transformer 不再是用一个固定的策略对所有输入一视同仁,而是能够根据输入的具体情况 “量身定制” 处理策略。
这等于说,CNN 仍然在用相同的工具处理所有图像。而 Transformer 已经学会了根据不同的情况使用不同的工具。简而言之,就是通过利用输入数据来修改参数矩阵,从而实现了针对性的处理能力。
这种从传统固定参数过渡到动态调整参数的能力,标志着深度学习模型在理解和处理复杂数据方面迈出了重要一步。
这个注意力是如何实现的呢??传统的CNN计算输出仅仅就是输入和卷积核加权求和计算结果。举个例子就是Wx = Y 而我们注意transformer的W是怎么来的呢?就是注意力矩阵,大家思考下就知道怎么回事了。这样也有助于大家对注意力机制的理解。
上一章节中重点聊了这个S4 模型,可以在作者的汇报中看到,作者一直致力于SSM的研究,可以说SSM的推进就靠他,同样他提出的HiPPO都是在改进SSM的问题。换言之他一直在研究RNN这样的结构,先是改进了记忆问题,现在又要引入注意力机制,如何实现注意力机制,问题就来了???
2. 选择性状态空间的概念引入
在我们上一章节实际上讨论了,SSM没有迎来自己的门控机制,同样他也没迎来自己的注意力机制。当然SSM的门控机制由河马HiPPO实现,改善长时记忆能力,同样这个选择性状态也是其对这种数据推动注意力机制的实现。
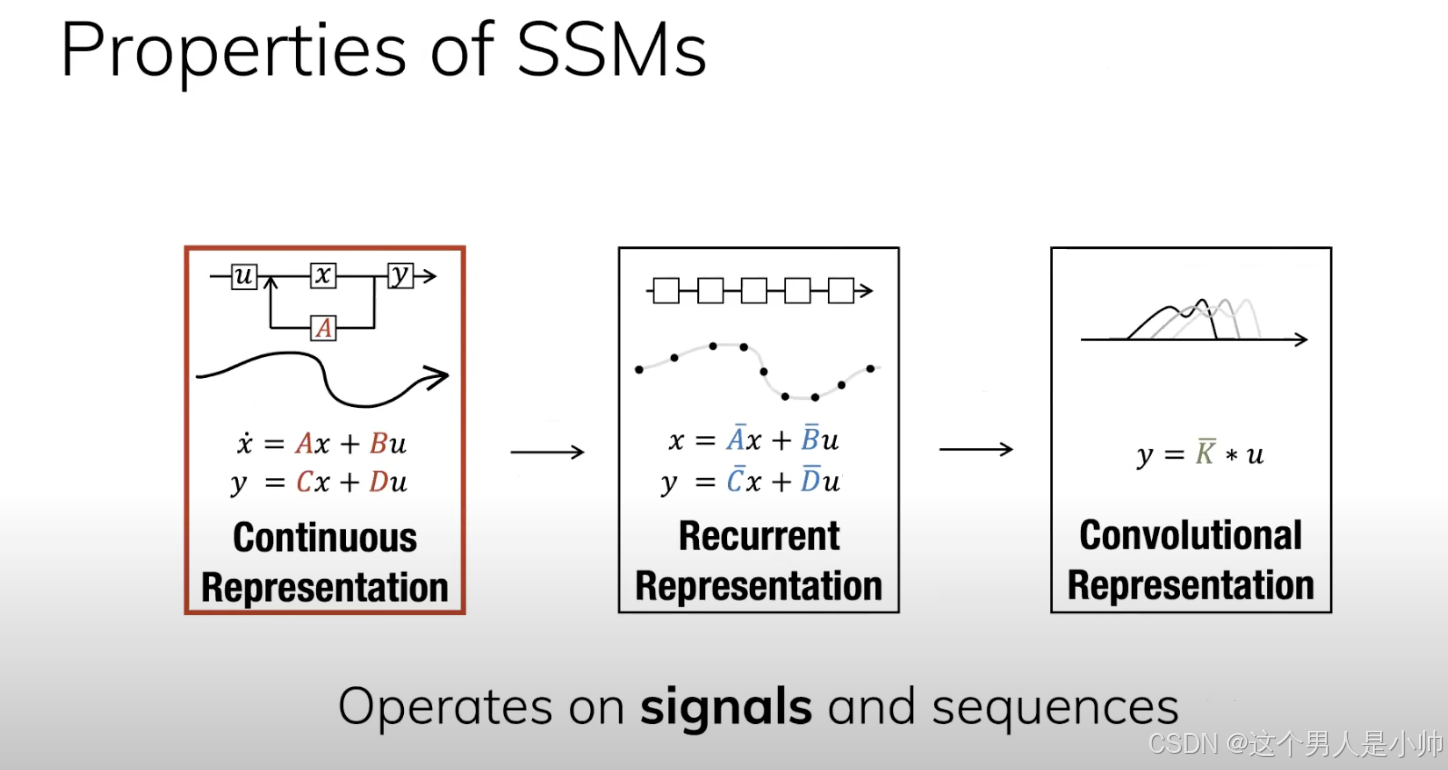
我们可以看到下图是在第二章节中讨论的问题,SSM的并行化机制:

可以看到实际上最终计算输出就是这个公式

假设你有输入序列 [“我”,“爱”,“吃”,“苹果”] 和 [1, 2, 3, 4, 5]。在没有引入任何注意力机制换言之这个选择性状态空间的时候,每个输入元素的处理方式是由固定的参数矩阵 C A ‾ k B ‾ C \overline{A}^k \overline{B} CAkB 决定的。这意味着无论输入如何变化,模型对每个输入的处理(例如权重分配)都相同,不会根据输入数据的内容或上下文动态变化。
各位可以思考下你要是送入到Transformer中这个数值绝对是变化的。
选择性状态空间模型提供了一种SSM上的注意力机制,使得模型在决定状态如何转移时能够考虑到输入数据的具体特性。这种基于输入驱动的参数调整和状态更新方式,类似于Transformer中的注意力机制,但在状态空间模型的框架下实现,显得更为全面和深入。这种方法的引入,意在解决SSM在应对复杂动态系统时固有的一些限制,如参数固定不变导致的灵活性不足。
换言之这就是Mamba的创新地方,在S4架构下引入一个类注意力机制通过输入影响权重矩阵的方式,被称为选择性状态空间。虽然Mamba模型在推理时参数本身也不变,但由于其设计中引入的选择性机制,使得模型能够根据不同输入token的特点进行有区别的对待(实际上我们可以看到到Transformer在推理的时候参数矩阵也不变化),这与SSM模型相比是一个显著的进步。且Mamba这种选择性是通过训练阶段的参数学习来实现的(根据训练阶段学习到的参数对不同的输入给予不同的处理),而不是在推理阶段动态调整参数。(Transformer变化的仅仅是attention矩阵)
上述思想各位可以停下来思考几分钟,如果你还是不理解这个逻辑,一方面看我的NLP专栏中的Transformer去理解下注意力矩阵的是如何生成。一方面多看看我上面的对比。
继续看下这个大家都爱用的例子:
我想点一个汉堡🍔。 “I want to order a hamburger.
如果没引入这个选择性机制,S4则会使用相同的注意力去处理每一个单词,实际上这个注意力可能不是很精准实际上想表达的是一种无差别计算方式。和我们上面的例子是一样的思想。如果是精力可能更加准确,对待无论是什么单词都是相同的精力:

这个是七月在线等多个博文展示的例子,这是博文链接
https://blog.csdn.net/v_JULY_v/article/details/134923301
第二个图就是引入某种机制可以按问题进行精力的分配,或者就是注意力的分配问题。
仅仅就是一个注意力问题。我觉得可能也是要避开使用注意力这个词汇体现创新点,另一方面他实现这个注意力的方式确实和transformer还是有一些差异的,所以换一种命名没毛病。
大家还记得为什么SSM可以并行化吗,那就是其权重系数可以提前进行计算。这个卷积核的形态就是这样的:

通过参数矩阵
C
,
A
‾
,
B
‾
C, \overline{A},\overline{B}
C,A,B 的乘积提前计算好对应部分的权重系数,从而实现模型的并行能力。 问题来了,你期望引入针对不同输入的权重不同,你的注意力系数就是不一致的。所以
C
,
A
‾
,
B
‾
C, \overline{A},\overline{B}
C,A,B 在不同的输入信息下的结果都是不一样的,也就无法提前计算权重了。
你期望得到注意力机制就要舍弃并行化的能力。 不过肯定之前都讨论了SSM的优势就是并行化,所以作者的另一个创新点就是针对并行化计算的(这个是他的第二个创新点后面说)。说了半天也没是如何实现的注意力机制。主要还是让大家理解下这些前因后果对其有一个全面的理解。
实际上我们也可以称之为这样获得的参数矩阵是输入数据推动的参数矩阵。
总的来说,通过引入依赖于输入的动态更新机制,选择性状态空间模型如S4等不仅改善了注意力分布,而且提高了模型对序列数据的理解和处理能力。这种方法的发展,标志着对复杂数据的建模方法在不断进步和革新,以更好地适应不断变化的数据环境和需求。
3. Mamba的创新点
上面废话说了一大堆,当然最重要的就是在S4上引入了注意力机制,当然人家叫选择性状态空间模型。总体的实现而言这个还是有差异的和注意力机制还是有着诸多不同,同样S4是四个S这个S6就是六个S。开始第一个创新点的讲解吧。

在上一节中我们讨论过这个SSM引入HiPPO改善了长程记忆能力变成S4的,在S4的基础上同样引入了这个注意力机制,换言之就是Selection选择性状态就是从S4变成了S6.
3.1 从S4到S6
作者是怎么做到引入这个注意力机制的呢???
先说和Transformer一样的部分。
我们回忆下Transformer中的 Q , K Q,K Q,K 是怎么得到的。通过输入数据进行线性变换层得到的两个参数矩阵我们称为 Q , K Q,K Q,K。用于注意力矩阵的计算实际上最大的功劳就是这两个线性变换矩阵 。
这两个参数矩阵的数值实际上就是模型训练的时候确定的。通过和输入数据进行交互(矩阵乘法)才生成最终的(注意力矩阵)参数矩阵。我们可以类比下线性变换的参数矩阵是一个中间商用于生成最终使用的参数矩阵(注意力矩阵),而另一部分决定这个参数矩阵(注意力矩阵)的还有输入数据。所以我们最终模型使用的可以因数据不同而变化的参数举证(注意力矩阵)是通过输入数据和线性变换的参数共同确定的。
同样Mamba里面也是这个操作逻辑。需要一个线性变换作为中间商,最终输入数据和线性变换矩阵共同生成的参数矩阵我们才用来进行预测工作。
我们看下S6中的伪代码在下图右侧,左侧则是S4的:

上图中可以的看到,通过这样的输入输入到不同的线性层线,就是输入和线性变换矩阵乘积。输出的结果就是最终需要使用的参数矩阵 B , C , Δ B,C,\Delta B,C,Δ。

再唠叨几句,就是 B , C , Δ B,C,\Delta B,C,Δ 都是由输入信息生成了只是使用了不同的线性层。类比就是Transformer中的 $Q,K $矩阵都是由输入生成。
线性层计算后的输出结果作为后续使用 B , C , Δ B,C,\Delta B,C,Δ 。从而我们可以看到 B , C , Δ B,C,\Delta B,C,Δ都是依赖于数据产生的,这也就是实现了我们想要的注意力机制,通过和数据的交互生成参数矩阵,换言之这也是SSM中的选择性空间状态。
可能有的同学会说不是 A A A 矩阵还不是数据依赖啊。但是别忘记了,后续还要对SSM进行离散化 Δ \Delta Δ 是依赖数据生成的,也就是存在数据依赖性,所以在做离散化的时候,能够让整体的 A ‾ \overline{A} A 与输入相关,就是一个连锁反应,数据影响了 Δ \Delta Δ ,同样 Δ \Delta Δ 将影响传递给了 A ‾ \overline{A} A。而且为了长时记忆估计做出来的这个的隐式的影响吧。
上面我们已经完成了对第一个创新点的讲解,就是利用输入和神经网络的全连接层做线性映射生成一个参数矩阵。而这些参数矩阵恰恰就是由输入数据和全连接的参数矩阵生成的,我们称之为数据依赖的参数矩阵。从而让其在模型中发挥作用替代 B , C , Δ B,C,\Delta B,C,Δ ,完成类似于Transformer中注意力机制的作用。当然上面的伪代码以及参数矩阵的理解还是有很多细节存在的我们下面讨论下
这里仅仅是讨论了其创新的核心但是有些细节我们还是要补充下确保完整性。
3.2 S6 细节补充
之前在提到SSM的时候实际上很少讨论 D D D 矩阵大多数时候用的比较少,所以当SSM展开就是和RNN是一样的。
首先我们明确下 B , C B,C B,C 矩阵的作用实际上就是一个管进入一个管出去。进来的东西就是控制进入多少要决定下取舍。出去同样的也是:
RNN不明白的同学出门到NLP专栏补补课。

这不是和RNN一样吗,一个负责新输入的取舍情况,一个负责计算好的状态作为输出的最终管理,
如果我们称 h h h 为记忆那么 B B B 就是在控制给这个记忆增加东西,而 C C C 就是控制给这 h h h 记忆减少东西作为最终的呈现 。
为什么这么说??
下面的是重点好好看
你可以看到输入的信息经过
B
B
B 要修改
h
h
h 那么就是在做一个加法而
B
B
B决定着输入进记忆的东西。而
C
C
C 仅仅决定保留
h
h
h 的哪部分作为输出,他手里仅仅一个
h
h
h 能处理,只有删减信息的权利。当然如果
D
D
D 矩阵存在
C
C
C 实际上也有增加的能力,但是在这样的结构上我们能看到
B
B
B 决定增加
h
h
h 的信息而
C
C
C 决定删减
h
h
h 的信息用于最终的输出表达。
我们说这个
B
B
B 是用来处理新输入的,对新的输入去留处理,而
A
A
A 则是对之前的记忆进行去留处理就是这么简单。
还有一个细节是我们可以的看到这个 Δ \Delta Δ 是做啥的呗??七月文章中指出是作为遗忘门。
Δ \Delta Δ 是遗忘门!!!!!!!
这个说起来就是LSTM中的概念了。我们如何理解呢???其实可以看这个公式。

离散化 A ‾ , B ‾ \overline{A},\overline{B} A,B 都是需要这个 Δ \Delta Δ 来完成,我们说 A , B A,B A,B 的作用,用来决定去留遗忘,同样这个 Δ \Delta Δ作为离散化间接的影响着 A , B A,B A,B 。
换言之,就是在其产生影响对输入信息和历史记忆做出反应。影响 A ‾ , B ‾ \overline{A},\overline{B} A,B 在进行遗忘时候的尺度问题。所以有着相同的作用。控制着遗忘门的尺度。再直白点就是 Δ \Delta Δ作为离散化间接的影响着 A ‾ , B ‾ \overline{A},\overline{B} A,B 他俩同样又影响着对输入和历史的遗忘能力,所以这就是遗忘门的尺度问题。
同样我觉得这部分要弄懂离不开LSTM的理解,各位还是需要看NLP专栏的内容进行补充。
3.3 S4中模型输入矩阵的维度
输入B就是batch批次大小,L就是序列的长度,而D是每一个token的维度大小。

Mamba是如何处理这样的输入的呢,D假设3 换言之一个token的的维度就是3,则采用三个独立的SSM去对每个维度的数据进行处理。很好理解我们之前在HiPPO中通过一个SSM去拟合一条曲线就是token维度为1的例子,如果每次输入是一个向量呢??就通过三个独立的SSM去拟合呗。

每一个token的维度对应一个独立的SSM系统控制他的拟合处理问题,这也是为了让模型具备更好的能力的一种方式,独立分工。我们看SSM伪代码中就是这样的:

就是说单次输入隐藏状态有多少个维度呢??我们输入一个D维度的数据。其中一个维度就需要SSM使用一个N维度向量去拟合。总体的就是DN个维度的向量来拟合输入的一个向量。大家可以停下来思考下,结合下HiPPO的那个例子。在序列长度上计算它需要O(BLDN)的时间和内存。换言之就是针对一个维度使用了一个SSM我们HiPPO的例子就是最简单的一个维度上的拟合。多维度就用多个而已。
A是什么形态呢???状态是一个向量N那么A不就是一个N*N吗,但是伪代码中则是可以看到是这样的:

这是因为我们之前为了计算计算采用了SVD技术所以,A实际上就是一个对角矩阵,即仅仅对角线有元素,那么如何存储最方便呢。仅需要存储对角线的数值即可。所以我们N维度确定是和状态做乘积。而D则是和SSM的个数保持一致。
3.4 S6和S4模型比较
可以看到红色区域就是最明显的变化,即矩阵维度发生了变换。这是因为我们的BC都是由输入信息生成的:

传统的SSM矩阵的参数矩阵形态是这样的,可以看到矩阵的BC的大原来是(D,N):
变成了(B,L,N)
还有一个细节就是之前的
Δ
\Delta
Δ 从D变成了(B,L,D)。就是一个batch里面就是BL个token,每个token都有一个单独的
Δ
\Delta
Δ 。矩阵B、C的维度由(D,N)变到(B,L,N)这个就比较明显了,我们为了保证不同时间输入使用的是不同的权重,所以B就是要有L个,就是每一个token都有一个独立的
Δ
、
B
、
C
的
\Delta 、B、C的
Δ、B、C的 。
有的同学可能会疑问B矩阵的形状为什么不是BLDN呢?前面说了,D指的是输入token的维度,N指SSM的隐藏层维度hidden dimension,输入维度D为512,你可以不使用512个SSM,使用,SSM隐藏层维度N比如64,也可以不降维,平等维度映射——相当于有8个SSM。不在采用1-1的映射关系了。这样也能降低维度,这都是在为计算资源考虑。
上面我大量的使用了注意力去解释这个选择性机制,同样在九月的博文中也有同样的李基泽我再次截图感兴趣的看原文。

OKK以上我们就介绍了完了Mamba的第一个创新。下一章节的内容主要是讨论这个S6是如何并行化的同样这也是其Mamba的第二个创新。以及也提供了各种简单的block便于大家学习。好了好了大家吸收吸收我们开始第下一节的学习。
4. 总结
【Mamba】详解(4) 【Mamba: 选择性 SSM】,在之前的章节中我们讲解了HiPPO,以及S4,以及这一章节的Mamba的第一个创新,下一节将迎来最中的完结部分。如果你对这样的讲解方式觉得有趣,喜欢。欢迎催更。如果帮助到你十分荣幸。
对这些内容感兴趣的朋友们,通过点赞、收藏和关注来表达你们的支持是对我的极大鼓励。
如果你感觉还不错的话也可以打赏一杯咖啡钱,非常感谢大家!有任何问题或建议,欢迎随时通过私信评论与我交流。期待你们的反馈。



















 6790
6790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











