







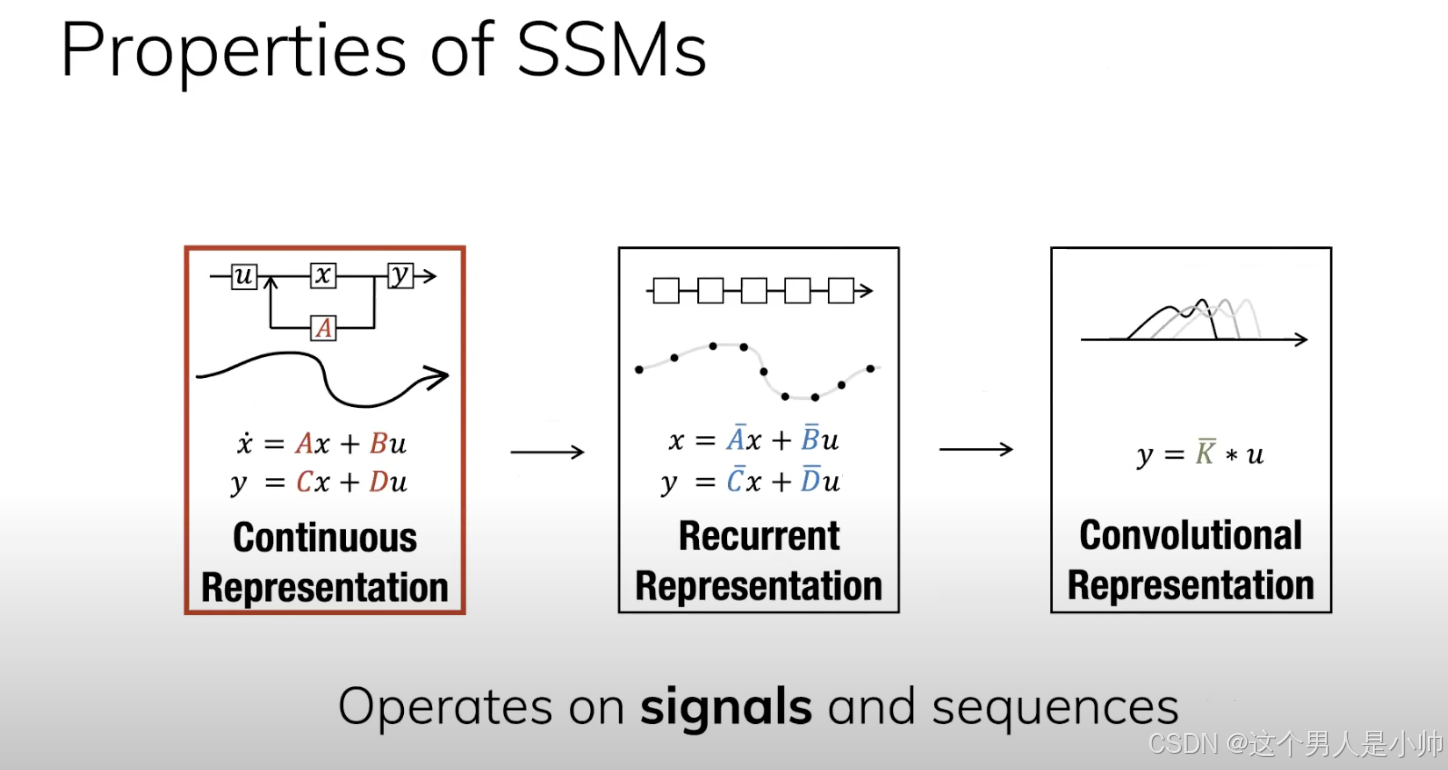
0. 引言
距离第一章节的发布大概过了两周的时间,本章将重点介绍 Mamba 框架中的又一个创新组件:硬件感知设计,我相信有些朋友还是能从我的博文一步一步的跟着我学了下来,承蒙不弃十分感谢。那么,让我们不多做停留,直接开始今天的内容探索吧。
给自己打个广告,如果您对 Transformer 还不太了解,欢迎访问我的博客专栏,其中包含了丰富的 NLP 入门内容。即使您不是NLP领域的学者,这些内容对您深入理解深度学习和神经网络也大有裨益。点击这里学习更多。
此外,如果您对图神经网络的了解还不够深入,我建议您先阅读相关基础知识。点击此处,都是我的个人理解,简单易懂。话不多说,那咱们就开始今天的学习吧。
1. 硬件感知算法
实际上这个创新包含两部分,并行化就是选择性扫描算法和在对硬件操作的理解。
1.1 SSM并行化问题
首先聊并行化的问题:
我们在最初下了一个较强的定义就是SSM是和RNN一致的,并且其能实现并行化能力,这也是其最大的优势,至于这个能力是如何实现的呢?就是通过下下图的方式达成的:

从而完成了这样的并行化能力,当你引入了注意力机制后这个并行化的卷积行为就能用了:

我们提到的这个注意力机制,就是上一节的创新点选择性机制。这一个优势的引入给并行化带来了困难。说人话就是在引入选择性后输入的权重的计算就变的复杂起来。说人话举例子看下图:

可以看到每一个输入使用的B矩阵都是和自己相关的,最红隐状态的计算是由之前的记忆和输入影响的A矩阵得到的,换言之我们可以看到 x t x_t xt 进行矩阵乘法的矩阵都是受到了 x t x_t xt 影响得到的矩阵,再详细一点就是 x t x_t xt 进行矩阵乘法的矩阵都是 x t x_t xt 生成的。大家盯住上述公式的最后一行:

大家思考下我上面说的话,这就是以一个简单的依赖关系 x t x_t xt 和自身生成的矩阵进行计算而已。
我们思考下并行化之所以可以并行实际上就是我们发现了预计算的规律,所以我们找到了计算方式。这就完成了这样的提前计算结果。即
发现了提前计算权重的规律
作者定义了一个这样的新的运算过程:

提出这样的运算方式满足结合率。其计算结果第二项作为结果。着虽然不是卷积但是也能满足并行。
我们试图再简化下这个计算就是:
( a , b ) ∗ ( c , d ) = ( a c , c b + d ) (a,b)*(c,d) = (ac,cb+d) (a,b)∗(c,d)=(ac,cb+d)
结果取第二项:
( a , b ) ∗ ( c , d ) = ( c b + d ) (a,b)*(c,d) = (cb+d) (a,b)∗(c,d)=(cb+d)
所以所以这里就是Mamba的第二个创新点,硬件感知算法。
具体是如何实现的呢??我们根据这个上图举例子:
计算结果如下图:

第一步使用上述定义计算方式计算前 两次输入的结果:

可以得到这样的结果:

我们再次重复这个计算方式:

我们仅仅去其结果的第二项作为计算结果,和C做乘积即可得到最终的结果:

我们再举个例子y3的计算方式,这里是有些不同的大家可以注意下,这里涉及到四个元素的计算,在并行运算的时候首先计算 x 0 x_0 x0和 x 1 x_1 x1然后再计算 x 2 x_2 x2和 x 3 x_3 x3。就是下图形式一致的情况。

然后将两部分的结果进行运算:

即可得到最终的结果:

总体的计算行为如上图所示,总体而言可以看到是具备这样的规律可循的,所以可以实现并行能能力。
1.2 硬件加速问题
SSM模型本身显存占用比较小,所以我们可以将模型和运算都放在SRAM上进行处理;这就和Transformer相比显然具备了很大的差距。Transformer由于注意力的问题,其现存占用太大了,无法完成这个事情。
什么意思呢,由于Transformer需要进行大量的读取操作,这是由于其注意力矩阵带来的高内存需求,所以需要反复的进行着一复制计存取操作。因此这就导致其在性能上首先,不在同一设备上就会增加其沟通成本。
而SSM则仅需要一次的操作就可完成。

上图实际上都是在讨论这样的一个思想。
最终模型的整体架构如下所示:

想传递的全部思想就是通过输入信息去影响各种参数矩阵。这样的一个逻辑思路。
2. 更简单的SSM架构

这个图是什么意思呢?
实际上最右侧的图才是Mamba的结构,其结构收到了门控思路的影响以及H3就是SSM块的影响构建出来的,最终得到的这种组合的形态就是上图所示。其内部具体的细节个如下图所以,类别就是Transfomer中的Encoder block可以直接应用。

Block种的内部细节如下:

有一点就是其在Selective SSM前进行了卷积操作。具体的实验细节各位可以自己去探索了。确实这个大的模型分成了五个小结写到这里俺真的累了。细节的问题都探讨完了。剩下的等我想起来再补充吧。欢迎催更欢迎。
3. 总结
这个Mamba的讲解到此结束了,其实比较难理解的还是SSM前期的准备,在后续的部分都是一些参数规模以及更高层面的东西,这确实需要大量工作的累积。还是与很多巧思在里面的,这同样也是作者的功力嘛。如果你对这样的讲解方式觉得有趣,喜欢。欢迎催更。如果帮助到你十分荣幸。
对这些内容感兴趣的朋友们,通过点赞、收藏和关注来表达你们的支持是对我的极大鼓励。
如果你感觉还不错的话也可以打赏一杯咖啡钱,非常感谢大家!有任何问题或建议,欢迎随时通过私信评论与我交流。期待你们的反馈。



















 2164
2164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











