






机器学习
图中的叉号就是我们的数据样本,横轴为肿瘤大小,纵轴为是否为恶性肿瘤。如果用我们之前学习的线性回归方程,则可以假设 h θ ( x ) = θ T x h_\theta(x) = \theta^Tx hθ(x)=θTx。可以得出图中的倾斜的斜率高一点的那一条直线。为了更好的做出预测,我们可以设定当 h θ ( x ) > = 0.5 h_\theta(x)>=0.5 hθ(x)>=0.5时,认为 y = 1 y=1 y=1,当 h θ ( x ) < 0.5 h_\theta(x)<0.5 hθ(x)<0.5时,认为 y = 0 y=0 y=0,如此看来,假设我们在x轴正方向远处还有一点如图中所示,我们的假设函数也是满足实际情况。但如果我们的假设函数设置的如图中斜率偏低的那一条呢。很显然和数据集中的数据发生了误差。所以线性回归在分类问题中并不是最适合的方法,而且如果使用线性回归,我们得出的 h θ ( x ) h_\theta(x) hθ(x)是可以大于1或者小于0。而接下来要讨论的logistic分类算法的值域大小是在[0,1]之间的。
假设函数
在线性回归中,我们的假设函数公式是
h
θ
(
x
)
=
θ
T
x
h_\theta(x) = \theta^Tx
hθ(x)=θTx,那么在分类问题中,我们定义
h
θ
(
x
)
=
g
(
θ
T
x
)
h_\theta(x) = g(\theta^Tx)
hθ(x)=g(θTx),这里的函数g的定义为
g
(
z
)
=
1
1
−
e
−
z
g(z)=\frac{1}{1-e^{-z}}
g(z)=1−e−z1,
z
=
θ
T
x
z=\theta^Tx
z=θTx,则
hθ(x)=11−e−θTx
这个函数被称作S型函数(Sigmoid function)或逻辑函数(Logistic function)。函数的图像如下图所示:
横轴为z,纵轴为
g
(
z
)
g(z)
g(z)。显然当z趋向于正无穷时,
g
(
z
)
g(z)
g(z)趋向于1,z趋向于负无穷时,
g
(
z
)
g(z)
g(z)趋向于0。图像在(0,0.5)点于纵轴相交。我们现在要做的依然是选择合适的参数
θ
\theta
θ来拟合数据。
这里我们将
h
θ
(
x
)
h_\theta(x)
hθ(x)的输出假设为当输入为x时,y=1时的概率。从概率上的角度来描述可以表达为
h
θ
(
x
)
=
P
(
y
=
1
∣
x
;
θ
)
h_\theta(x) = P(y=1|x;\theta)
hθ(x)=P(y=1∣x;θ)。因此我们可以得到如下公式:
P(y=1|x;θ)+P(y=0|x;θ)=1P(y=1|x;θ)=1−P(y=0|x;θ)
决策边界(decision boundary)
上述我们说过,可以假设当
h
θ
(
x
)
>
=
0.5
h_\theta(x)>=0.5
hθ(x)>=0.5时,认为
y
=
1
y=1
y=1,当
h
θ
(
x
)
<
0.5
h_\theta(x)<0.5
hθ(x)<0.5时,认为
y
=
0
y=0
y=0。根据逻辑函数的图像,我们得知,当z>0时,
h
θ
(
x
)
>
=
0.5
h_\theta(x)>=0.5
hθ(x)>=0.5,则
θ
T
x
>
=
0
\theta^Tx>=0
θTx>=0,同样的
h
θ
(
x
)
<
0.5
h_\theta(x)<0.5
hθ(x)<0.5时
θ
T
x
<
0
\theta^Tx<0
θTx<0。
这里可以举一个例子,假设
h
θ
(
x
)
=
g
(
θ
0
+
θ
1
x
1
+
θ
2
x
2
)
h_\theta(x) = g(\theta_0+\theta_1x_1+\theta_2x_2)
hθ(x)=g(θ0+θ1x1+θ2x2)中的
θ
0
,
θ
1
,
θ
2
\theta_0,\theta_1,\theta_2
θ0,θ1,θ2分别等于-3,1,1。则$\theta =
⎡⎣⎢−311⎤⎦⎥
,
那
么
y
=
1
时
,
即
代
表
,那么y=1时,即代表
,那么y=1时,即代表h_\theta(x) = g(\theta_0+\theta_1x_1+\theta_2x_2) >= 0.5
,
即
,即
,即\theta^Tx = -3+x_1+x_2>=0
,
相
反
y
=
0
时
,
,相反y=0时,
,相反y=0时,\theta^Tx = -3+x_1+x_2<0
,
那
么
我
们
可
以
得
出
这
两
个
不
等
式
的
分
界
线
即
,那么我们可以得出这两个不等式的分界线即
,那么我们可以得出这两个不等式的分界线即x_1+x_2=3$。
在这条直线的上方代表y=1的部分,下方则代表y=0的部分,而这条直线就被称作决策边界。
下面再继续看一个复杂点的例子,这里额外添加两个特征
x
1
2
,
x
2
2
x_1^2,x_2^2
x12,x22。
h
θ
(
x
)
=
g
(
θ
0
+
θ
1
x
1
+
θ
2
x
2
θ
3
x
1
2
+
θ
4
x
2
2
)
h_\theta(x) = g(\theta_0+\theta_1x_1+\theta_2x_2\theta_3x_1^2+\theta_4x_2^2)
hθ(x)=g(θ0+θ1x1+θ2x2θ3x12+θ4x22)。假定$\theta =
⎡⎣⎢⎢⎢⎢⎢⎢−10011⎤⎦⎥⎥⎥⎥⎥⎥
,
则
可
得
出
若
,则可得出若
,则可得出若-1+x_12+x_22>=0
,
则
y
=
1
,
若
,则y=1,若
,则y=1,若-1+x_12+x_22<0
,
则
y
=
0
,
那
么
显
然
,
这
里
的
决
策
边
界
的
图
像
是
,则y=0,那么显然,这里的决策边界的图像是
,则y=0,那么显然,这里的决策边界的图像是x_12+x_22 = 1$。
当然随着假设函数的复杂程度变化,决策边界也会各有不同。后面我们将会学习如何自动选择参数
θ
\theta
θ,使我们能在给定一个训练集时,根据数据自动拟合参数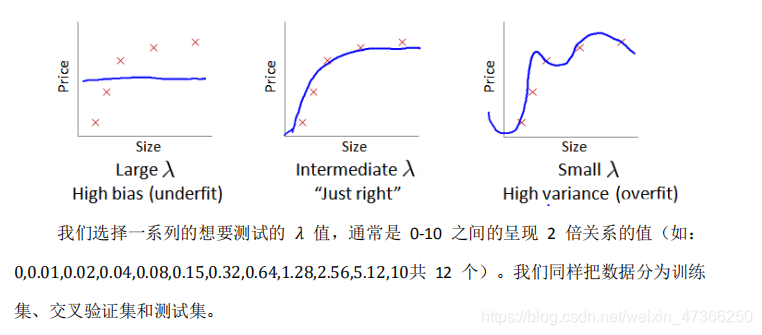
如果我们有 100 行数据,我们从 1 行数据开始,逐渐学习更多行的数据。思想是:
当训练较少行数据的时候,训练的模型将能够非常完美地适应较少的训练数据,但是训练出
来的模型却不能很好地适应交叉验证集数据或测试集数据。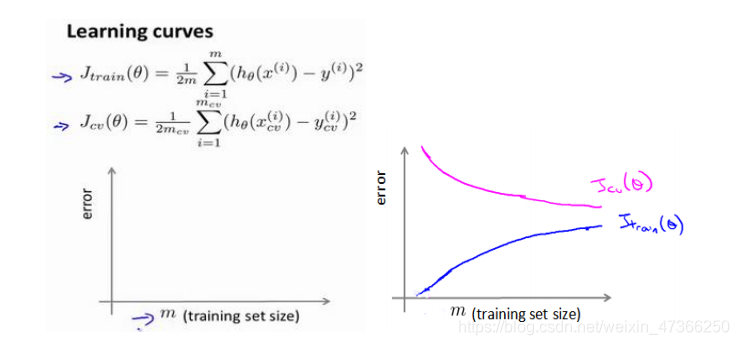
如何利用学习曲线识别高偏差/欠拟合:作为例子,我们尝试用一条直线来适应下面的
数据,可以看出,无论训练集有多么大误差都不会有太大改观: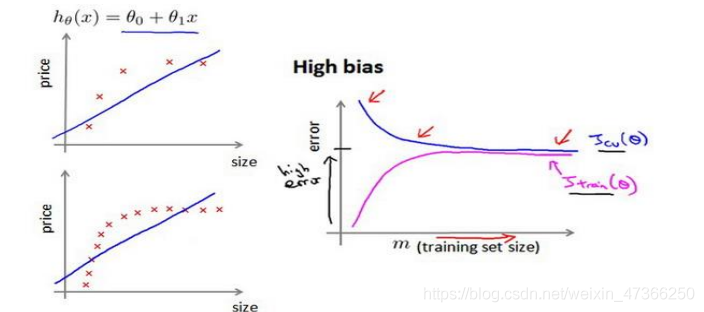
也就是说在高偏差/欠拟合的情况下,增加数据到训练集不一定能有帮助。















 9377
9377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









