







1、为什么要引入线程
缺陷:进程是资源的拥有者,在创建、撤销、切换操作中需要较大的时空开销,限制了并发程度的进一步提高
进程作为资源分配的基本单位,调度执行与切换的责任交给线程处理
- 占用较少的系统资源
- 同一进程内的线程共享内存和文件
- 提高应用程序的性能
- 使多处理机效率更高
- 改善程序的结构
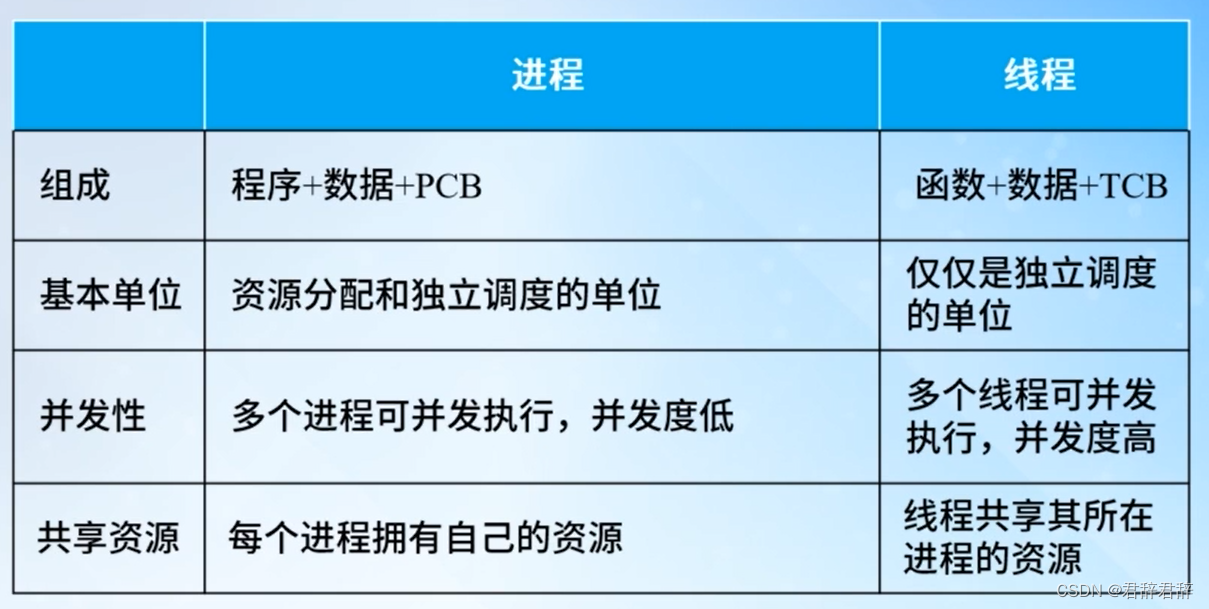
2、进程与线程
线程(Thread):OS调度的最小单位,被包含在进程之中,一条线程指的是进程内的一个执行单元
- 轻量实体:进程的实体是程序,线程的实体是函数
- 调度的基本单位
- 可并发执行
- 共享进程资源
- 用户级线程(ULT)和内核级线程(KST)
- 用户级线程:仅存在用户空间中,应用程序通过线程库管理
- 内核级线程:线程管理由内核管理,以线程为基础进行调度
进程:
- 既是一个拥有资源的独立单位,可独立分配虚地址空间、主存和其它系统资源
- 又是一个可独立调度和分派的基本单位
资源拥有单位称为进程,调度的单位称为线程,进程是线程的母体
 线程共享进程的资源,只拥有堆栈和寄存器等少量资源
线程共享进程的资源,只拥有堆栈和寄存器等少量资源
3、线程模型
3.1 多对一模型
多对一模型将多个用户级线程映射到一个内核级线程,线程管理由用户空间的线程库完成,当一个线程调用系统陷入内核时,整个进程将被阻塞,因此多个线程无法在多处理器上并行运行
3.2 一对一模型
一对一的关系将一个用户级线程映射到一个内核级线程,模型提供更多的并发性,支持多个线程在微处理器上并发执行,缺点是创建用户线程需要相应的内核线程
3.3 多对多模型
多对多关系线程模型是任意数量N的用户线程映射到相等或者小于N内核线程的多路复用,提供了并发的最佳准确性,当一个线程调用系统陷入内核时,内核可以调度另一个线程执行
3.4 Linux模型
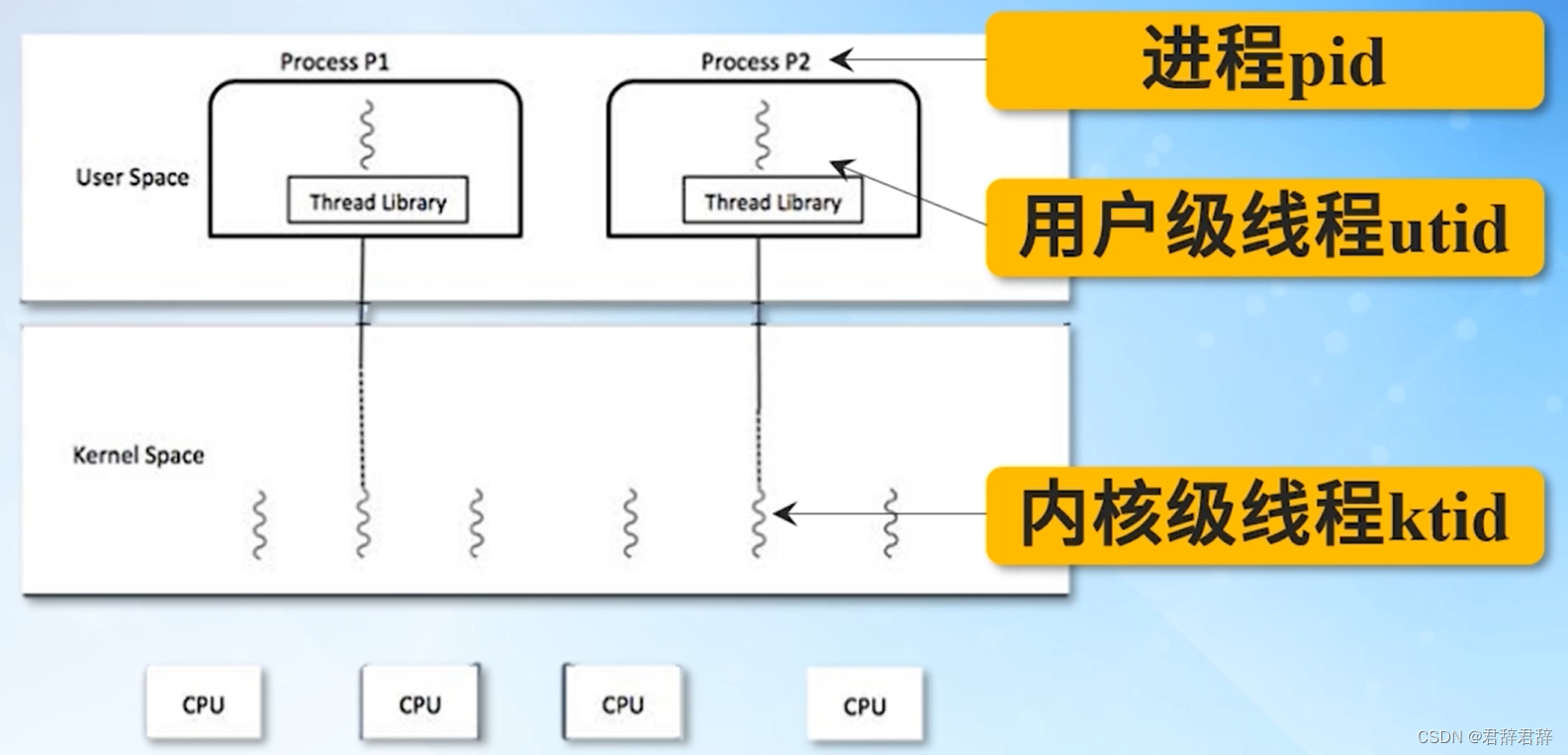 用户级线程与内核级线程是一对一的模型
用户级线程与内核级线程是一对一的模型
4、Linux中进程和线程的创建
进程和线程几乎共享所有的资源:代码、数据、进程空间、打开文件等等,线程只拥有自己的寄存器和栈
task_struct:进程、线程、内核线程
内核中最终都通过 do_fork() 分别创建它们
4.1 fork的实现
Linux创建进程采用了写时复制技术,子进程继承父进程的用户空间
4.2 vfork的实现
int sys_vfork(struct pt_regs regs)
{
return do_fork(CLONE_VFORK | CLONE_VM |SIGCHLD, regs.esp, ®s, 0);
}
第一个标志(CLONE_VFORK),儿子优先,老爸等着
第二个标志(CLONE_VM),共享父进程的内存地址空间(相比写时复用技术效率低)
4.3 clone的实现
long sys_clone(unsigned long, unsigned long, int __user *, int __user *, unsigned long)
{
return _do_fork(clone_flags, newsp, 0, parent_tidptr, child_tidptr, tls);
}
线程的诞生:共享地址空间、文件系统、打开的文件、函数等
4.4 内核线程的创建
目前内核调用 kthread_create() 或者 kthread_run创建线程,其本质也是向 do_fork() 提供特定的flags标志而创建的
4.5 do_fork()代码流程
- copy_process() (主要用于创建进程控制块以及子进程执行时所需其他的数据结构)
- 确定PID
- 如果设置了CLONE_STOPPED,阻塞子进程
- wake_up_new_task()
- 如果设置了CLONE_VFORK标志,阻塞父进程















 1141
1141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









