






概要
语法错误纠正(GEC)是自动检测和纠正文本中的错误的任务。 该任务不仅包括纠正语法错误,例如缺少介词和不匹配的主谓一致,还包括拼写错误和语义错误,例如拼写错误和选词错误。 该领域在过去十年中取得了重大进展,部分原因是一系列五项共享任务的推动,这些任务推动了基于规则的方法、统计分类器、统计机器翻译以及最终神经机器翻译系统的发展,这些系统代表了当前的主导地位 最先进的。
介绍
写作是一项需要学习的技能,对于非母语用户来说尤其具有挑战性。 在我们的母语中,我们偶尔都会犯标点、拼写错误,以及选词上的小错误,所以非母语作家常常很难创作出符合语法且易于理解的文本。
自然语言处理 (NLP) 领域的研究至少从 20 世纪 80 年代起就已经解决了“格式错误的输入”问题,因为除非输入符合语法,否则文本的下游解析通常会崩溃(Kwasny 和 Sondheimer 1981;Jensen 等人 1983) 。 然而,能够显着帮助非母语作家的有用应用程序直到 2000 年代才开始出现,例如 ETS 的 Criterion(Burstein、Chodorow 和 Leacock 2003)和 Microsoft 的 ESL Assistant(Leacock、Gamon 和 Brockett 2009)。 这些系统很大程度上基于手工编码的“错误规则”,应用于强大的解析器的输出,建议纠正错误。
随后科学家利用数据驱动的方法,使用监督机器学习模型,这些模型是根据错误文本的注释语料库构建的,并进行了示例性更正(Brockett、Dolan 和 Gamon 2006;De Felice 和 Pulman 2008;Rozovskaya 和 Roth 2010b;Tetreault, Foster 和 Chodorow 2010;Dahlmeier 和 Ng 2011b)。 Helping Our Own (HOO) 共享任务(Dale、Anisimoff 和 Narroway 2012)吸引了 14 个研究小组使用英语第一证书 (FCE) 语料库 (Yannakoudakis) 进行竞争并报告其纠正英语限定词和介词选择错误的结果 ,Briscoe 和 Medlock 2011),事后看来,这是从基于规则到数据驱动方法的转折点,以及人们对这项任务的兴趣日益浓厚。Leacock等人(2014) 随后发表了一份长达一本书的调查报告,总结了该领域迄今为止的进展。
在本文中,我们更深入地关注最近基于深度学习的任务方法,并对任务的性质、其评估和其他剩余挑战(例如多语言语法错误)进行更详细的讨论。
现状
语法的定义出奇的难以定义,在母语使用者和非母语使用者之间更是难以捕捉具体细节。比如下面的部分举例( 出自论文:Grammatical Error Correction: A Survey of the State of the Art)
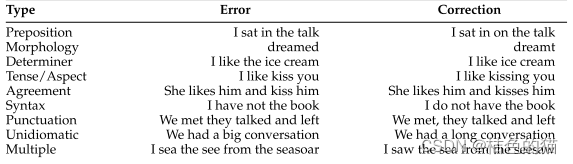
有些错误在某种意义上是复杂的,它们的纠正需要一系列替换、省略或插入步骤来纠正,有的句子还包含某种重复性的错误。所有现有的注释方案都根据所涉及的词的词性,以及所感知的错误的形态、词汇、句法、语义或语用来源,将这些大类(遗漏错误,插入错误,遗漏错误)细分为更多的子类。这些方案的区别数量各不相同,从20多个(Nucle:Dahlmeier,Ng,and Wu 2013)到近100个(CLC:Nicholls 2003)。这些不同的注释决策以人工事实的方式影响了系统性能的评估,因此开发了一个两阶段自动标准化过程Errant(Felice,Bryant and Briscoe 2016;Bryant,Felice,and Briscoe 2017),它使用语言增强的对齐算法和一系列错误类型分类规则将平行的错误和更正的句子对映射到单个注释方案。该方案使用主要基于词性和词法的25个主要错误类型类别,这些错误类型进一步细分为遗漏(遗漏)、不必要(插入)和替换错误。这种方法允许在任何或所有平行语料库上对系统进行一致的自动化培训和评估,并支持针对不同错误类型对系统的优势和劣势进行更细粒度的分析,更方便的让语言科学家去进行标注和测试。
数据集
语法错误的概念很难定义,因为不同的错误可能有不同的范围(例如,本地错误与上下文错误)、复杂性(例如,拼写错误与语义错误)和更正(例如,[本书] → 这本书] vs. [这本书 → 这些书]。 因此,人工注释是一项对认知要求极高的任务,清晰的注释指南是数据集质量的重要组成部分,其最重要的三个方面是:Minimal vs. Fluent Corrections, Annotation Consistency, and Preprocessing Challenges.
Minimal vs. Fluent Corrections
所谓的Minimal vs. Fluent Corrections,即最小修正与流畅修正,注释者应该进行最少数量的更改以使文本符合语法,然而这通常会导致听起来不自然的更正,因此最好按照流畅更正的原则对语料库进行注释。
` 提示:
| 类型 | I句子. |
|---|---|
| Original | I want explain to you some interesting part from my experience. |
| Minimal | I want to explain to you some interesting parts of my experience. |
| Fluent | I want to tell you about some interesting parts of my experience. |
最小更正主要是在解释之前插入缺失的不定式以使句子符合语法,但流利更正也会将“解释”更改为“告诉”你,因为“告诉”某人经历比“解释”经历在生活中更为常用。这种区别的主要挑战之一是,很难在构成最小修正和构成流畅修正之间划清界限。 这是因为最小校正(例如,缺少限定词)是流畅校正的子集,因此没有最小校正就不可能有流畅校正,最小的修正通常比流畅的修正更容易进行(对于人类和机器来说),尽管不可否认的是,流畅的修正是更理想的结果。
Annotation Consistency
注释一致性(Annotation Consistency),人类注释的一个重大挑战是,更正是主观的,而且通常有多种方法来更正一个句子。如果注释者的任务是明确定义他们为纠正句子而进行的编辑,则注释者指南必须明确定义编辑的概念。
Preprocessing Challenges
人类注释者需要经过训练来纠正自然文本,GEC 系统通常经过训练来纠正单词标记化句子(主要用于评估目的)。 这种不匹配意味着人工注释通常要经过几个预处理步骤才能产生所需的输出格式。 第一个转换涉及将字符级编辑转换为标记级编辑,但有时可能会出现人工注释的字符范围无法映射到完整标记的情况; 例如:[ing → ed] 表示编辑 [dancing → danced]。 第二个转换涉及句子标记化,考虑到人工编辑可能会改变句子边界(例如,[A. B, C. → A, B. C.]),这可能会更复杂。
小结
本文详细介绍了目前语法纠错所面临的工作,尤其是数据集的产生,下文将介绍具体的语法纠错数据集
















 4877
4877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











