






概要
在上节中提到了使用重新排序、集成和系统组合、多任务学习可以提升GEC系统的性能,在本文中,将讲述剩余的方法。
自定义推理方法
自定义推理方法(Costom Inference Methods),目前来看,各种推理技术已被提出来提高系统输出的质量或加快推理时间在GEC。其中最常见的是应用多轮推理,称为迭代解码或多轮解码。
应用多轮推理能够提高输出质量。这是由于GEC的输入和输出使用相同的语言,因此模型的输出可以再次通过模型以产生输出的第二次迭代,达到二次纠正的效果。简单来说,多轮推理可以理解为输入–纠错–再次纠错:
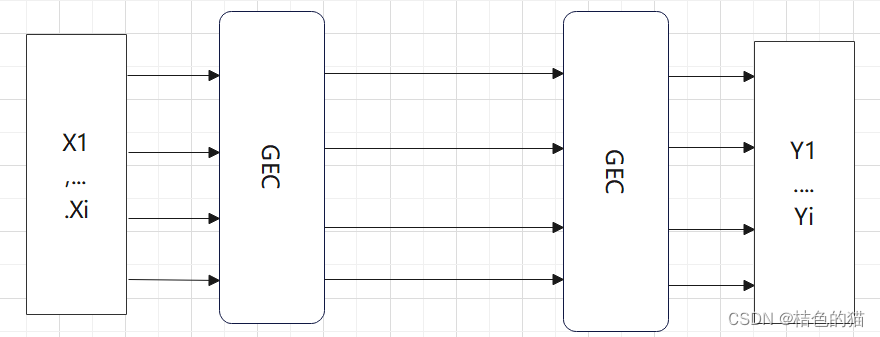
这样做的好处是,模型有第二次机会纠正它在第一次迭代中可能错过的错误。在2019年,Lichtarge等人提出了一种迭代解码算法,允许模型进行多次增量校正。在每次迭代中,只有当模型具有高置信度时,才允许模型生成不同的输出。事实证明,这种技术对于在嘈杂数据(如维基百科编辑)上训练的GEC系统是有效的,但对于在干净数据上训练的GEC系统则不那么有效。2018年,Ge,Wei和Zhou提出了一种称为流畅度提升的替代迭代解码技术,其中模型执行多轮推理,直到流畅度得分停止增加,而在2022年,Lai等人提出了一种迭代方法,该方法研究了以不同顺序纠正不同类型错误(缺失,替换,不必要的单词)的效果。迭代解码通常用于序列标记GEC系统,其通常不能在单次通过中校正所有错误。在这些系统中,应用迭代解码,直到模型停止对输出进行更改或迭代次数达到极限。
在加快推理模块方面,由于GEC中的许多标记都是从输入复制到输出的,因此标准的左右推理可能效率低下。2020年,Chen 等人因此提出了一个两步的过程,只对预测包含语法错误的文本跨度进行校正。他们的系统首先使用错误跨度检测(ESD)模型预测错误跨度,然后使用错误跨度校正(ESC)模型仅校正检测到的跨度。在报告中提到,与标准的序列到序列模型相比,推理时间减少了近50%。在2021年,Sun等人提出了一种并行化技术,以加快推理,积极解码。
上下文GEC
上下文GEC(Contextual GEC),在文本领域,上下文提供了极为重要的的信息,对于纠正许多类型的语法错误和解决不一致性至关重要。然而,现有的GEC系统通常在句子层面执行校正,每个句子被独立地处理,因此跨句子信息被忽略。因此,这些系统经常无法纠正上下文错误,例如动词时态、代词、连读句和话语错误,这些错误通常依赖于单个句子范围之外的信息。此外,这种狭隘的制度所提出的更正在整个段落或整个文件中可能不一致。
在2019年Chollampatt,Wang和Ng率先通过调整调整 CNN 序列到序列模型,使其更具上下文感知能力,从而首次解决了这一问题。具体来说,他们他们引入了一个辅助编码器,将前两个句子与输入句子一起进行编码,并将编码纳入了 CNN 序列到序列模型。输入句子,并通过注意和门控机制将编码纳入解码器。在2021年,Yuan和Bryant随后比较了在基于Transformer的GEC中捕获更广泛上下文的不同架构,并表明本地上下文是有用的(≤ 2句),但对于提高性能来说,非常长的上下文(> 2句)是不必要的。因为人类参考编辑没有注释错误是否取决于本地上下文或远程上下文,所以通常难以评估上下文感知系统对于上下文敏感错误的校正的程度。因此,Chollampatt,Wang和Ng构建了一个动词时态错误的合成数据集,需要跨句子上下文进行纠正,Yuan和Bryant提出了一个文档级评估框架来解决这个问题。
GANs
GANs(生成对抗网络,Generative Adversarial Networks)GANs)(Goodfellow et al. 2014)是一种模型训练方法,它使用生成器来生成一些输出,并使用一个神经网络来区分真实的数据和人工输出。2021年,Raheja和Alikaniotis是第一个将这种方法应用于错误纠正的人,他们训练了一个标准的序列到序列的Transformer模型,以从并行数据和句子分类模型中生成语法句子,以区分这些生成的输出句子和人类注释的参考句子。在训练过程中,模型进行对抗性竞争,生成器学会生成与参考句子无法区分的正确句子(从而欺骗了学习者),而学习者学会识别真实的和生成的句子之间的差异(从而击败了生成器)。这种对抗性训练过程最终被证明可以产生更好的序列到序列模型。
小结
到此,本文关于GEC的研究已经结束,更多详细的信息参考论文《Grammatical Error Correction:A Survey of the State of the Art》,在文章后半部分,讲述了数据增强,GEC评判标准(MaxMatch,ERRANT,GLEU等)以及20年后各种系统的比较,如下图所示:
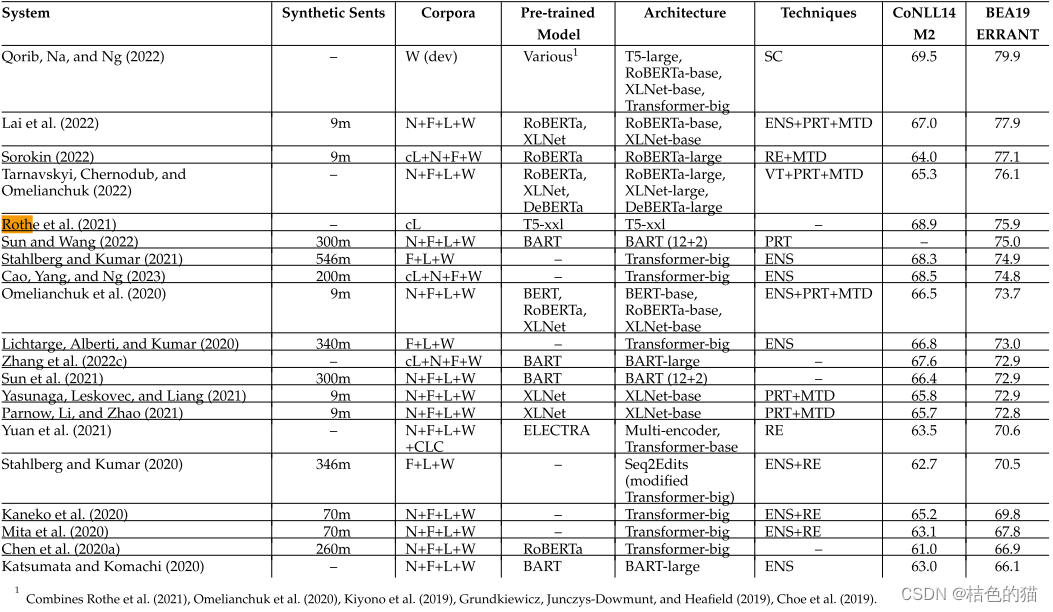
在如上所示的系统中,我节选了几篇技术论文:
(1) Grammatical error correction: Are we there yet?
简述:最近,自然语言处理领域取得了许多进展,语法纠错(GEC)也不例外。我们发现,在语法纠错基准测试语料库 CoNLL-2014 测试集上,最先进的语法纠错系统(T5 和 GECToR)通过标准 F0. 5 评估指标。然而,仔细检查它们的输出结果会发现,仍有一些错误是它们无法纠正的。这表明,创建新的测试数据以更准确地衡量 GEC 系统的真实性能是未来的重要工作。
(2)Frustratingly easy system combination for grammatical error correction.
简述:在本文中,我们将语法纠错(GEC)的系统组合表述为一个简单的机器学习任务:二元分类。我们证明,只要问题表述正确,简单的逻辑回归算法就能非常有效地组合 GEC 模型。我们的方法成功地提高了 F0. 5 在 CoNLL-2014 测试集上的得分比最高基础 GEC 系统提高了 4.2 分,在 BEA-2019 测试集上提高了 7.2 分。此外,在 BEA-2019 测试集上,我们的方法比最新技术高出 4.0 分;在使用原始注释的 CoNLL-2014 测试集上,我们的方法比最新技术高出 1.2 分;在使用替代注释的 CoNLL-2014 测试集上,我们的方法比最新技术高出 3.4 分。我们还表明,我们的系统组合能生成更好的修正,F0. 5 分数。
(3)Type-driven multi-turn corrections for grammatical error correction.
简述:语法纠错(GEC)旨在自动检测和纠正语法错误。在这方面,主导模型通过一次迭代学习进行训练,同时在推理过程中进行多次迭代修正。以往的研究主要集中在数据增强方法上,以消除暴露偏差,这种方法有两个缺点。首先,它们只是将额外构建的训练实例与原始实例混合起来训练模型,无法帮助模型明确意识到渐进修正的过程。其次,它们忽略了不同类型修正之间的相互依存关系。在本文中,我们为 GEC 提出了一种类型驱动的多轮修正方法。利用这种方法,我们可以从每个训练实例中额外构建多个 每个训练实例都涉及特定类型的错误修正。然后,我们依次使用这些额外构建的训练实例和原始实例来训练模型。实验结果和深入分析表明,我们的方法对模型训练大有裨益。
(4)Ensembling and knowledge distilling of large sequence taggers for grammatical error correction
在本文中,我们研究了对 GEC 序列标记架构的改进,重点是在 Large configurations 中对基于 Transformer 的最新编码器进行汇编。我们鼓励通过对跨度级编辑的多数票来组合模型,因为这种方法对模型架构和词汇量大小都有一定的容忍度。我们的最佳组合在 BEA-2019 (测试)上取得了 76.05 分的新 SOTA 结果,即使没有在合成数据集上进行预训练也是如此。此外,我们还利用训练过的集合进行知识提炼,生成了新的合成训练数据集 "Troy-Blogs "和 “Troy-1BW”。我们的最佳单一序列标记模型在生成的 Troy 数据集上进行了预训练,并与公开可用的合成 PIE 数据集相结合,取得了接近 SOTA 的成绩(据我们所知,我们的最佳单一模型在 BEA-2019 测试中的得分为 73.21,仅次于得分更高的 T5 模型)。代码、数据集和训练模型均可公开获取)。
















 858
858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











