






文章目录
shell 脚本运行方式: 在命令行里输入脚本文件的名字
1.引号和字面量
字面量: 引号的作用是用于创建字面量,即原封不动的字面意思。防止shell 做任何的替换。
单引号: 单引号之间的字符,会被当做一个单独的参数。使用字面量时,优先考虑单引号。 如果需求复杂一点,再考虑双引号。
查找etc/passwd/中符合正则表达式r.*t 的行
$ grep 'r.*t' /etc/passwd
**双引号:**与单引号差不多,只是shell会对双引号中的所有变量都进行扩展。
不做转换的一般法则:
- (1)将所有‘(单引号)改成‘\’’ (单引号、反斜杠、单引号、单引号);
- (2)用单引号包围整个字符串。
2 特殊变量
$n: $0、$1: 像这样以正整数命名的变量,都包含了脚本的参数值。n 为数字,$0 代表该脚本名称,$1- 9 代表第一到第九个参数,十以上的参数,十以上的参数需要用大括号包含,如 9 代表第一到第九个参数,十以上的参数,十以上的参数需要用大括号包含,如 9代表第一到第九个参数,十以上的参数,十以上的参数需要用大括号包含,如{10}
$#变量持有传给脚本的变量的数量。当$#为0时,就代表没有参数了,所以$1会是空。用于循环使用shift 来遍历参数很有帮助。
$@ 变量代表脚本接收的所有参数。可以整个传给脚本内的某个命令。
3 逻辑判断
在shell脚本中,-gt (>); -lt(<); -ge(>=); -le(<=);-eq(==); -ne(!=),&&(与),||(或)。
[root@yuioplvlinux-128 ~]# a=5
[root@yuioplvlinux-128 ~]# if [ $a -gt 3 ];then echo "OK"; fi
OK
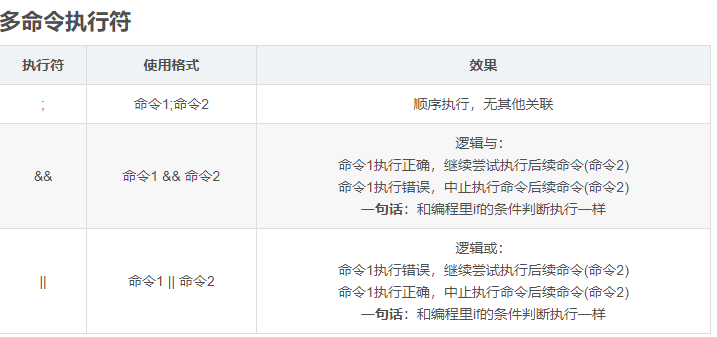
4 管道符
在Shell中分隔符“|”为管道符。管道符用于命令间的值传递。管道符左命令正确输出值作为管道符右命令的操作对象,右命令操作左命令的正确输出。其支持多命令从左向右传递。管道符命令的最终值为最右边命令的输出值。管道符的使用规则:
(1)管道符“|”两边无空格。
(2)管道符左命令必须有正确输出值。
(3)管道符右命令必须能处理左命令的正确输出值。
(4)管道符右命令不能处理管道符左命令的错误输出值。
(5)管道符左命令的正确输出值只能传递给相邻的右命令,反之,右命令仅能处理相邻左命令的正确输出值。
#Shell管道符实例
#从进程列表中查找含有“bash”字符的进程
ps -aux|grep “bash”
5 重定向
echo hello > test.txt 这样控制台就不会输出hello了,而是把输出重定向到test.txt文件中了
echo hello >> test.txt >> 是在文件后面追加 > 是覆盖
$? 执行上一个指令的返回值 (显示最后命令的退出状态。0表示没有错误,其他任何值表明有
所以要判断程序最后执行是否成功可以用这样的命令
if [ $? -eq 0 ]; then
echo “ddd.sh execute succ”
else
echo “ddd.sh execute error!”
exit 1;
fi
-eq //等于
-ne //不等于
-gt //大于 (greater )
-lt //小于 (less)
-ge //大于等于
-le //小于等于
shell重定向输出(1>&2 2>&1 &>file >&file) :
在shell程序中,最常用的文件描述符FD(file descriptor)大概有三个:
0: 标准输入(stdin)
1: 标准输出(stdout)
2: 标准错误(stderr)
example:
如果当前目录下只有一个文件:a
ls
a #代表着1标准输出
ls b
ls ... No such file or directory #代表2错误输出
ls a b 1>f.out 2>f.err #终端上什么都不会输出,相应的信息会被分别输出到f.out和f.err
(ps: 1>f.out缩写:>f.out,通常1>省略成>)
下面,认识下 1>&2 2>&1
如果这样写:1>2,意味着将标准输出重定向到一个名叫2的文件中
而1>&2代表着将标准输出重定向到标准错误中
ls a b 1>f.out 2>&1 #所有(标准输入/标准输出)信息都被输出到f.out
ls a b 2>f.out 1>&2 #所有(标准输入/标准输出)信息都被输出到f.out
&是一个描述符,如果1或2前不加&,会被当成一个普通文件。
> 是 1> 的简写。
1>&2 :标准输出重定向到标准错误。
2>&1 :标准错误重定向到标准输出。
&> file 和 >& file 意思是把标准输出和标准错误输出都重定向到文件file中
shell脚本中exit0和exit1的含义
exit 0:正常运行程序并退出程序;
exit 1:非正常运行导致退出程序;
exit 0 可以告知你的程序的使用者:你的程序是正常结束的。如果 exit 非 0 值,那么你的程序的使用者通常会认为
你的程序产生了一个错误。
在 shell 中调用完你的程序之后,用 echo $? 命令就可以看到你的程序的 exit 值。在 shell 脚本中,通常会根据
上一个命令的 $? 值来进行一些流程控制。0代表程序正确的执行,如下图例子所示:
shell 函数
脚本格式:
1.#!/bin/bash
2.sum (){
3.echo "第一个变量:" $1
4.echo "第二个变量:" $2
5.let n=$1+$2
6.echo $n
7.}
8.sum $2 $1
shell 脚本中的各种括号用法
https://blog.csdn.net/m0_47219942/article/details/107442691?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168895532216800226511857%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=168895532216800226511857&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-1-107442691-null-null.142v88control_2,239v2insert_chatgpt&utm_term=shell%E8%84%9A%E6%9C%AC%E4%B8%AD%E7%9A%84%E5%90%84%E7%A7%8D%E6%8B%AC%E5%8F%B7&spm=1018.2226.3001.4187
usage() 函数
usage()
{
echo "Usage: $0 filename"
exit 1
}
awk 用法
awk中的split和patsplit
echo 'foo,bar' | awk '{n = split($0,a,/,/); for(i=1;i<=n;i++) print a[i]}'
foo
bar
echo 'foo,bar' | awk 'BEGIN{FS=","}{n = split($0,a); for(i=1;i<=n;i++) print a[i]}'
foo
bar
echo 'foo,bar' | awk '{n = patsplit($0,a,/[^,]*/); for(i=1;i<=n;i++) print a[i]}'
foo
bar
echo 'foo,bar' | awk 'BEGIN{FPAT="[^,]*"}{n = patsplit($0,a); for(i=1;i<=n;i++)print a[i]}'
foo
bar
echo "123aaa345bbb678ccc" | awk '{n = patsplit($0,a,/[[:digit:].]+/); for(i=1;i<=n;i++) print a[i]}'
123
345
678
echo "123aaa345bbb678ccc" | awk 'BEGIN{FPAT="[[:digit:].]+"}{n = patsplit($0,a); for(i=1;i<=n;i++) print a[i]}'
123
345
678
split默认是以FS为分隔符,直接切割字符串
if [ -z $i ]判断过滤是否为空
Shell脚本之uniq用法
uniq用于检查文本文件中重复出现的行列,一般与sort命令结合使用
uniq [-cdu] [-f<栏位>] [-s<字符位置>] [-w<字符位置>] [输入文件] [输出文件]
> cat testfile # 原有内容
test 30
test 30
test 30
Hello 95
Hello 95
Hello 95
Hello 95
Linux 85
Linux 85
> uniq testfile # 删除重复行后的内容
test 30
Hello 95
Linux 85
> uniq -c testfile # 检查文件并删除文件中重复出现的行,并在行首显示该行重复出现的次数。
3 test 30
4 Hello 95
2 Linux 85
当重复的行并不相邻时,uniq命令是不起作用的,即若文件内容为以下时,uniq命令不起作用:
> cat testfile1 # 原有内容
test 30
Hello 95
Linux 85
test 30
Hello 95
Linux 85
test 30
Hello 95
Linux 85
# 这时我们就可以使用sort:
> sort testfile1 | uniq
Hello 95
Linux 85
test 30
# 统计各行在文件中出现的次数
> sort testfile1 | uniq -c
3 Hello 95
3 Linux 85
3 test 30
# 在文件中找出重复的行
> sort testfile1 | uniq -d
Hello 95
Linux 85
test 30















 881
881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









