







Abstract
这篇文章做的是semantic parser,NL to logic form。作者认为这个领域标注的label的数量过少是semantic parser的一个挑战。作者提出了duel learning algorithm,能够充分利用数据的标签。模型有两部分组成,semantic parser model + dual model,并提出了一个新的reward signal。
Introduction
以往的semantic parser存在两个问题,1)缺乏足够的数据,如果需要标注足够的label是需要很大的人工成本。2)需要对输出做出限制。logic form是有严格的结构信息,如果不对结构做出限制,那么生成的logic form会无效,或者在语义和语法不完整。surface是指语法信息,semantic是指语义信息。prime model从query生成logic,duel model从logic生成prime,这两个模型互相监督,一个模型生成的结果由另一个模型验证。
In this loop, the primal and dual models restrict or regularize each other by generating intermediate output in one model and then checking it in the other.
有点像是对抗神经网络的做法。并且这种训练不需要labeled data,可以很容易应用到无监督的数据中。在duel learning中,prime和duel是由两个agent来实现,这两个模块通过强化学习互相学习。
文章贡献有三点:1)提出了一个新的duel framework。2)提出新的valid reward。3)实验结果超越了sota。
这篇文章的idea主要是,既然logic form可以通过query得到,那么从logic form也可以得到query。评价逆生成语句的结果即可。
Prime and Dual
Prime Task就是semantic parser的任务,Query to Logic Form。由一个encoder和一个decoder组成,encoder负责将query编码成vector representation,decoder负责把vector representation解码成logic form。
Encoder和Decoder和以往的一些项目没有太大区别,Encoder是bidirectional LSTM

正向输入+反向输入 = hidden layer。Decoder是一个单向LSTM+attention机制,同时还引入了Copy Mechanism和Entity Mapping这两个东西好像是在MWP的neural中提出的。
Dual Model完成的任务是Logic to Text。也是用一个attention-based Encoder-Decoder architecture。对于实体的选择,Reverse Entity Mapping和prime model的对应起来,从知识库里面选择相对应的实体,知识库是给出的。
Dual Learning for Semantic Parsing
作者使用两个Agent来表示Query to Logic和Logic to Query。由于这样产生的feedback是不可微分,所以用强化学习来优化。Q2LF和LF2Q形成两个循环。

通过Q2LF生存y(logic form),然后用logic form通过LF2Q生成Query,和原先输入的Query对比。第二个循环也是一样。第一个循环query->logical form->query, 第二个循环logical form->query->logical form 。
Learning Algorithm
假设存在三类数据集,包含了logic form的数据集 { x , y } , τ \{ x, y \},\tau {x,y},τ ,只含有query的无监督数据集Q,只含有logic form的无监督数据集LF。先用包含了logic form的数据集用极大似然预训练神经网络。
上图左便是第一个循环。首先从Q和
τ
\tau
τ的数据集中随机采样,Query通过seq2seq得到k个logic form,这些logic form本身就可以获得一个奖励
R
q
v
a
l
R_q^{val}
Rqval,然后通过Q2LF的loop获得一个reconstruction reward
R
q
r
e
c
R_q^{rec}
Rqrec。所以
R
i
q
=
α
R
q
v
a
l
+
(
1
−
α
)
R
q
r
e
c
R_i^{q} = \alpha R_q^{val} + (1-\alpha)R_q^{rec}
Riq=αRqval+(1−α)Rqrec。

policy gradient更新。
第二个循环则是在
L
F
LF
LF和
τ
\tau
τ中采样。

同样的更新方式。
Reward Design
Validity reward:Validity reward是在loop之外估计的,主要是检查logic form的语法和结构问题。首先检查括号匹配的问题,其次就是类型匹配是否有误。
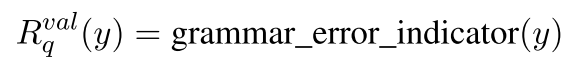
有错误为0,没有错误为1。

to_lisp_tree判断是否满足语法,type_consistent判断是否符合类型。
LF2Q的也很简单:
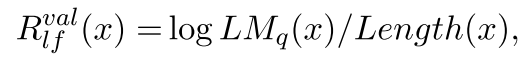
LM(.)是之前预训练的模型,不过我在前面没找着。
Reconstruction reward
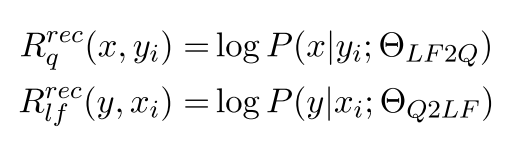
这两东西是估计相似程度的。
Experiments
Dataset
ATIS和OVERNIGHT这两个数据集都是fully supervised的数据集,从这两个数据集构建出unlabeled的数据集。


Conclusion
这篇文章的发在ACL上,算得上是A类了。这篇文章的想法挺新颖,结合了Q2LF和LF2Q。文章的贡献有2,首先是提出了prime and dual model,其次是提出了相应的reward。这种模型有点像是对抗神经网络,难以训练,文章提出新的reward用强化学习训练这个问题。而且这个模型是属于半监督的模型,loss function就相当于是reward,所以只要对reward做调整也可以用在无监督上面。
但是这篇文章的数据量有点小,ATIS和OVERNIGHT数据集都是很小的,和wikitablequesion或wikitablechecking这两个数据集量的不能比的。虽然后面的实验有通过人工添加Logic form的形式增加实验数据,但是Logic form是通过从ATIS数据集上替换修改的,结构上还是和ATIS的logic form类似,泛化能力有限。并且这个模型的这种训练方法如果应用到无监督的数据集上训练可能会很难,这个模型本身是不具备语法检测的,搜索空间相对会大很多,不过我觉得让agent学习如何书写正确的语法也能够人agent学到更多东西。
这篇论文的核心idea还是Query -> logic, logic -> Query这两个loop,并提出是新的reward解决训练问题。
文章复现
数据集ATIS,OVERNIGHT
ATIS数据集中有3983条句子,572个单词,这些单词被分成了127个类别。OVERNIGHT数据集有9个领域,数据集的信息非常详细,比wikitableQuestion那些好多了。
semantic parsing属于Q2LF模块。

Question Generation属于LF2Q模块。

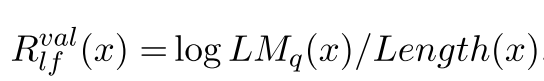
Language Model则是在计算Logic Form所需要的模块。评估生成语句Quesry的优劣。

Pseudo model是利用logic form重新生成数据集,属于augment dataset的方法。

最后则是组合。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









