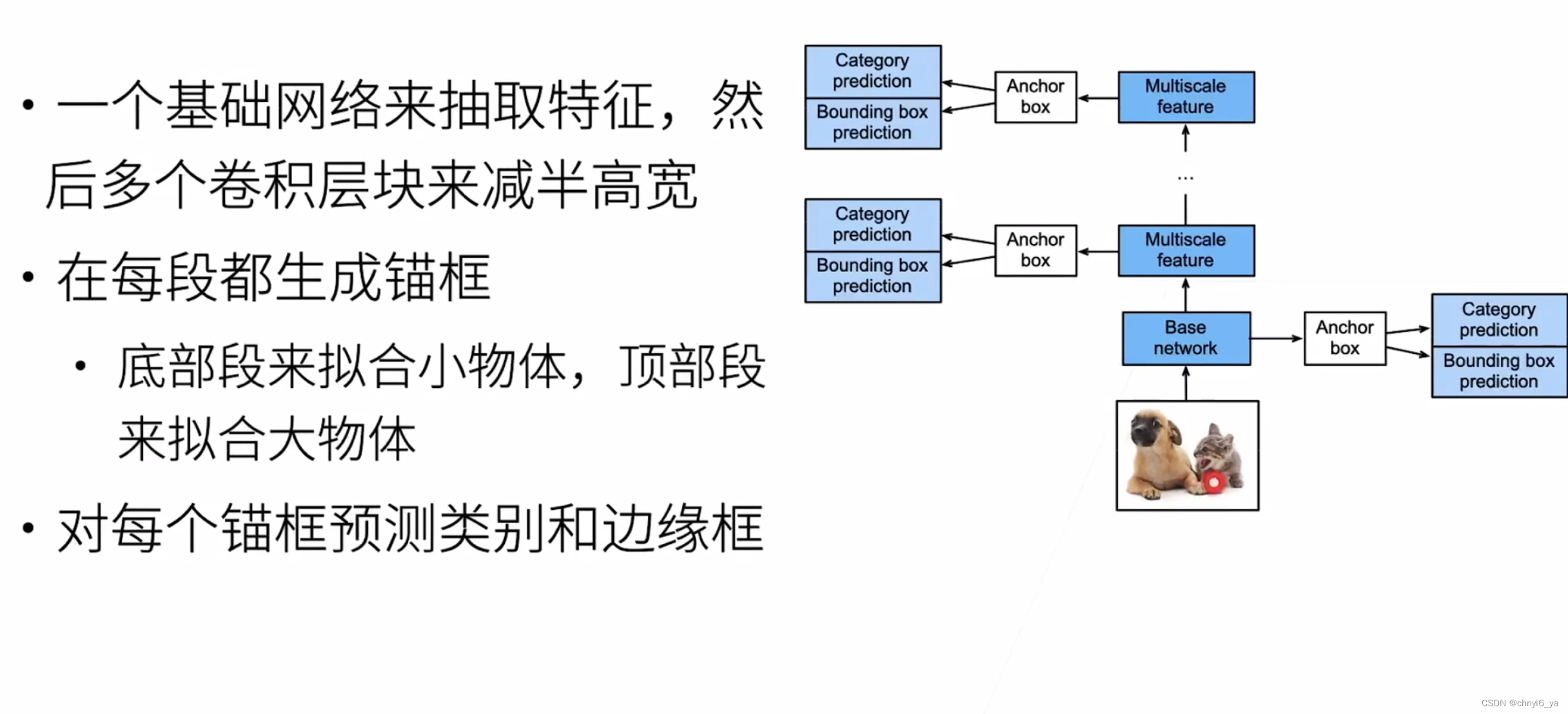
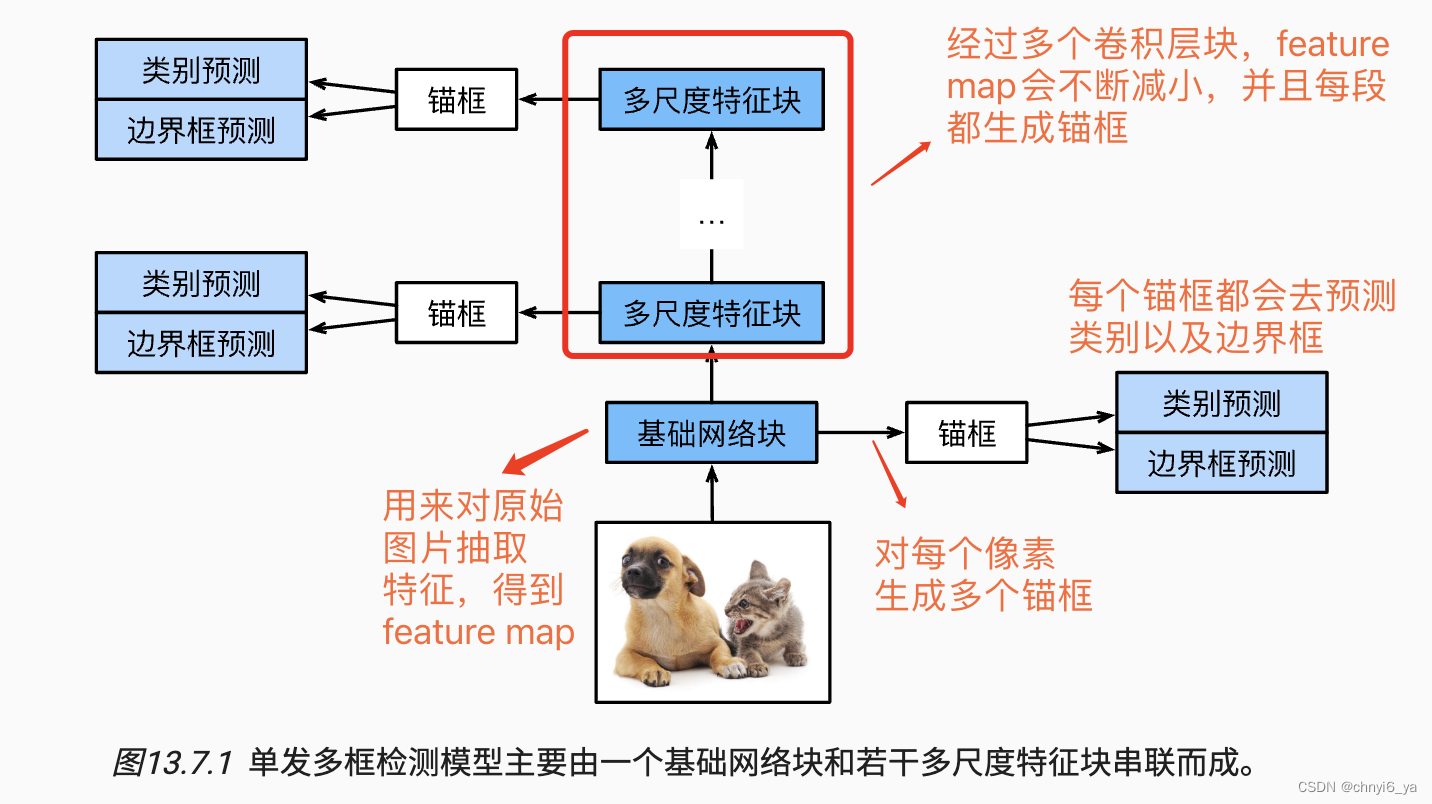
1. 生成锚框 2. SSD模型 越到顶部去拟合大物体,底部是来拟合小物体的。 3. SSD的效果 4. 总结 SSD通过单神经网络来检测模型以每个像素为中心产生多个锚框在多个段的输出上进行多尺度的检测 5. YOLO(you only look once) 6. YOLO的效果 7. Q&A Q1:测试数据做平均,是结果做平均还是概率做平均?还是看实际情况选择? A1:结果做平均。

























 467
467











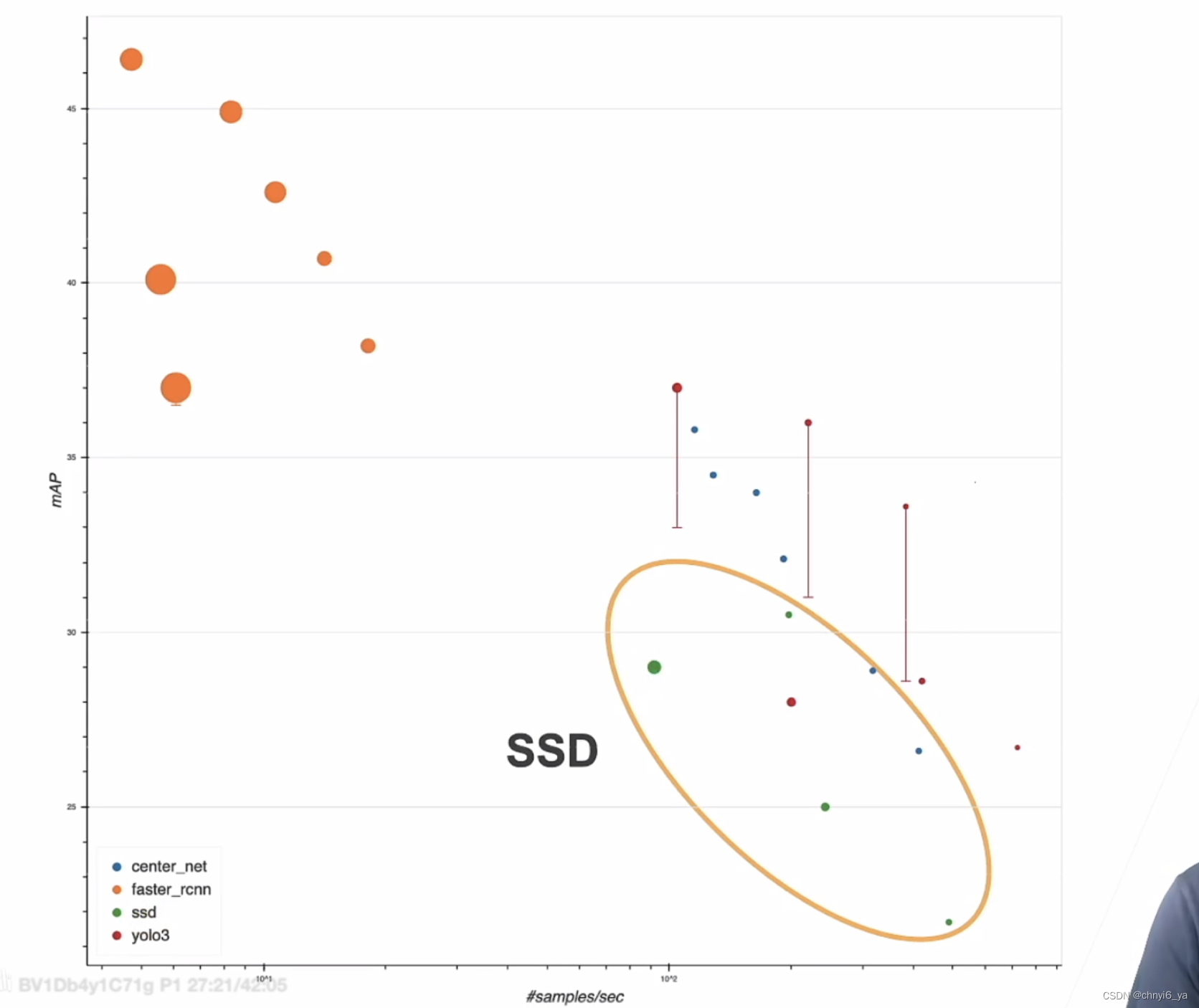
 被折叠的 条评论
为什么被折叠?
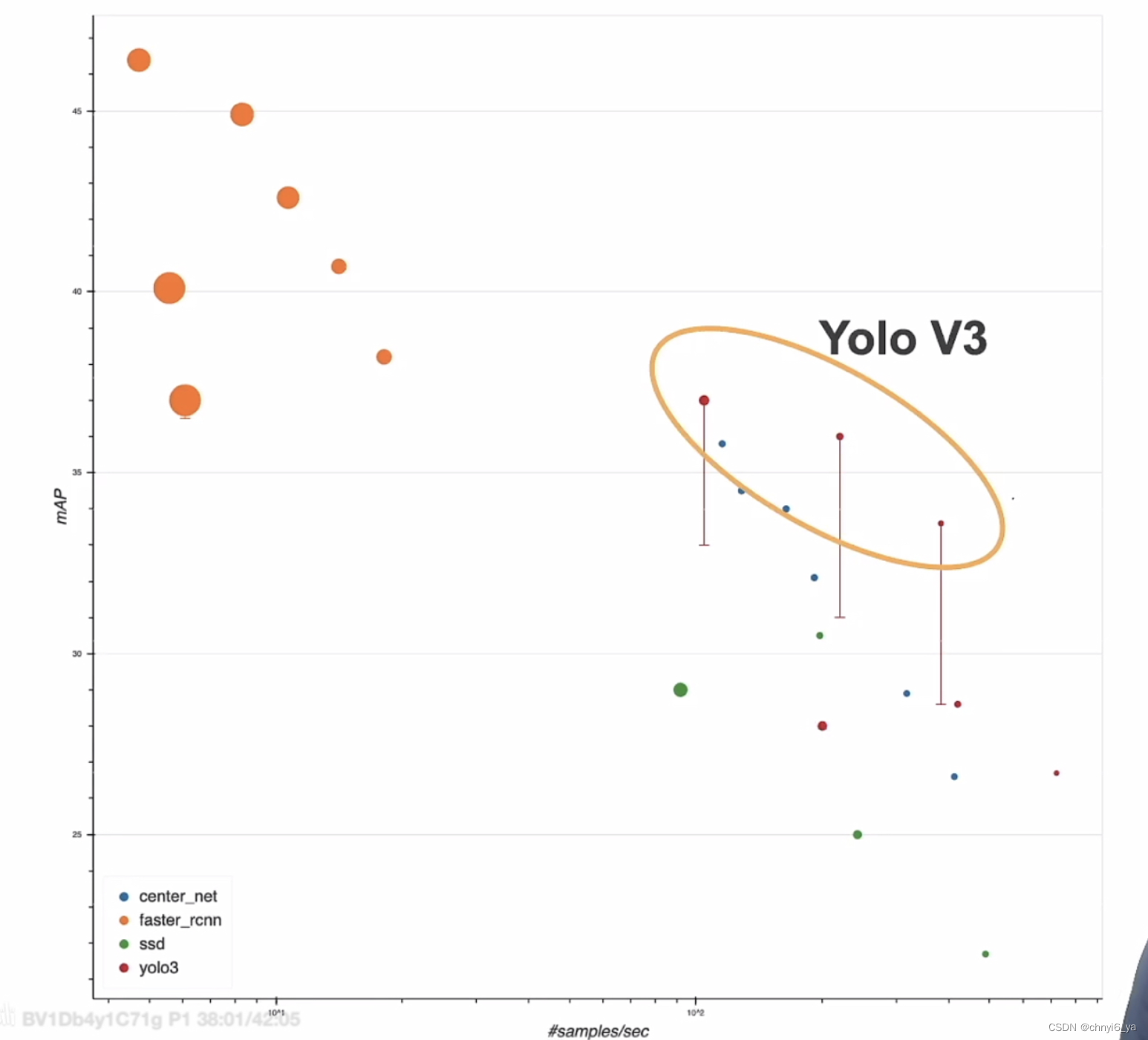
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






