







在跑evaluate.py时,发现bleu,METEOR,ROUGE_L都能成功,就是spice评估总是报错,我的报错内容如下:
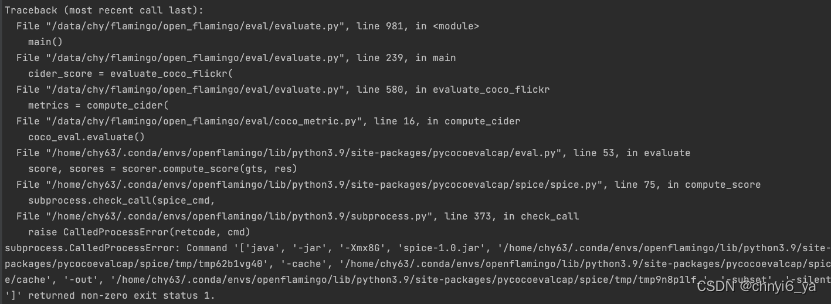
就找了好久,也问了chatgpt啥的,尝试很很多,最终发现是java版本太高了,需要java8的版本,而linux系统下的版本是17,于是需要把java版本降低,但同时我没有root权限,所以只能去java官网下载压缩包后,去自己的主目录解压。
如果有root权限,只需要切换版本啥的,很简单,所以只说没有权限的方法。
1. 具体步骤如下:
这是官网 中java8 版本的下载地址:
https://www.oracle.com/java/technologies/javase/javase8u211-later-archive-downloads.html
注意,先用下面的命令看一下系统的位数:
getconf LONG_BIT

我的是64位,所以选择这一项下载:
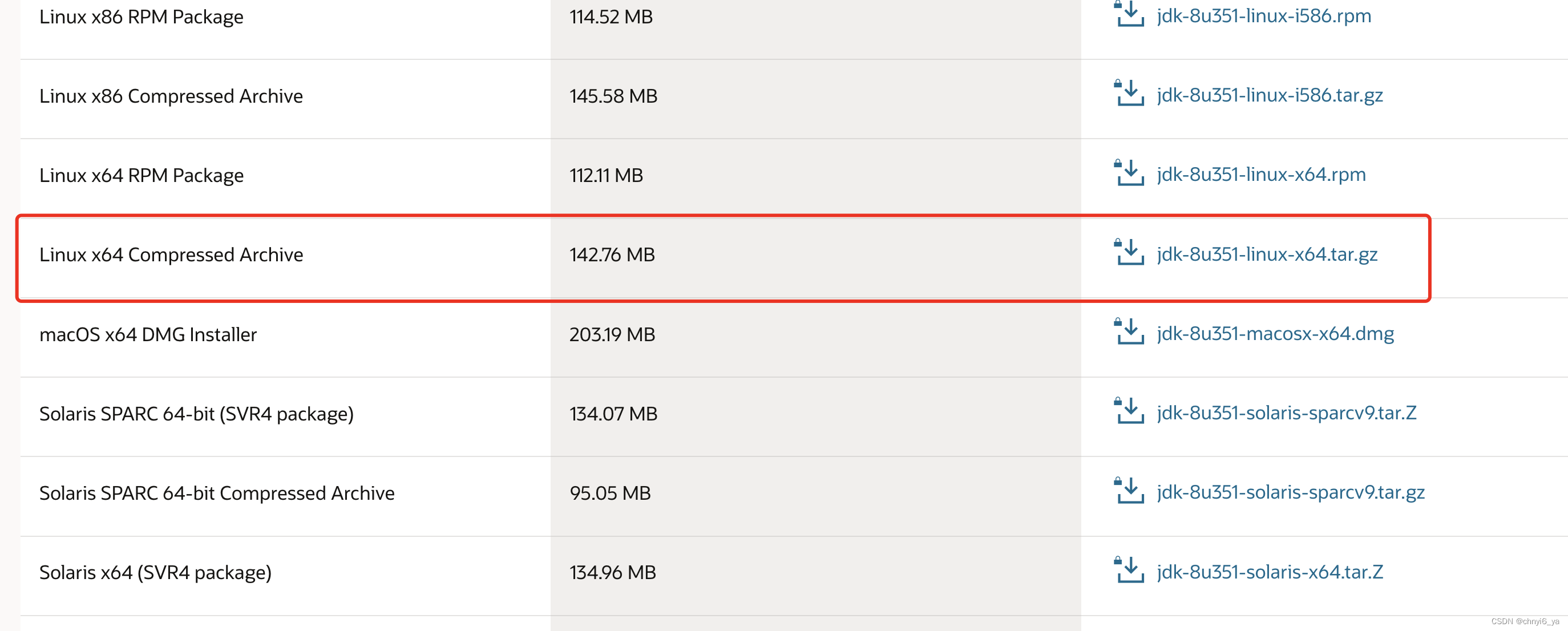
下载好之后,可以在自己的主目录下创建java目录:
mkdir java

之后,会把压缩包解压到java文件夹下:
tar -zxvf jdk-8u301-linux-x64.tar.gz -C ~/java/
此时,进入java文件夹,使用“ls”命令可以看到包含的文件夹:

接下来,使用 vim 编辑器编辑 ~/.bashrc :
vim ~/.bashrc
加入这两句话:
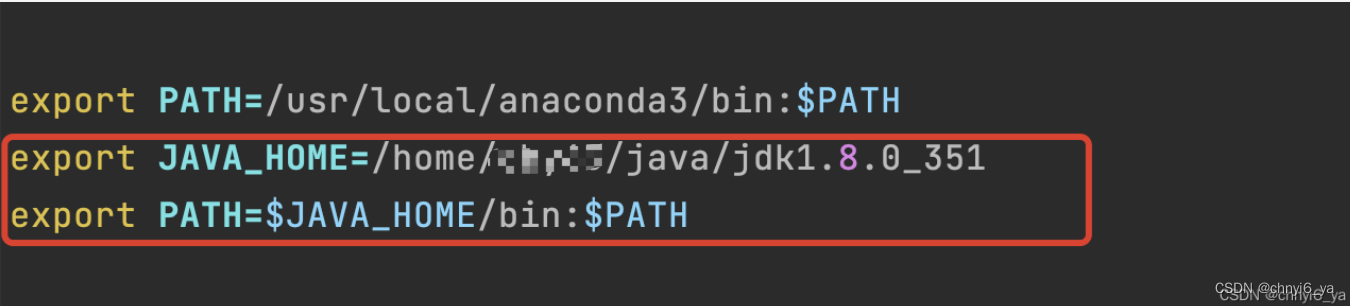
export JAVA_HOME=/home/主目录名字/java/jdk1.8.0_351
export PATH=$JAVA_HOME/bin:$PATH
使用这个命令让其生效:
source ~/.bashrc
最后确认java版本是否安装成功:
java -version

最后的最后,去找到spice.py文件,进行修改,把‘java’改成刚刚安装的路径,刚刚安装的路径可以通过which java获得:


还要把spice-1.0.jar也改成绝对路径:

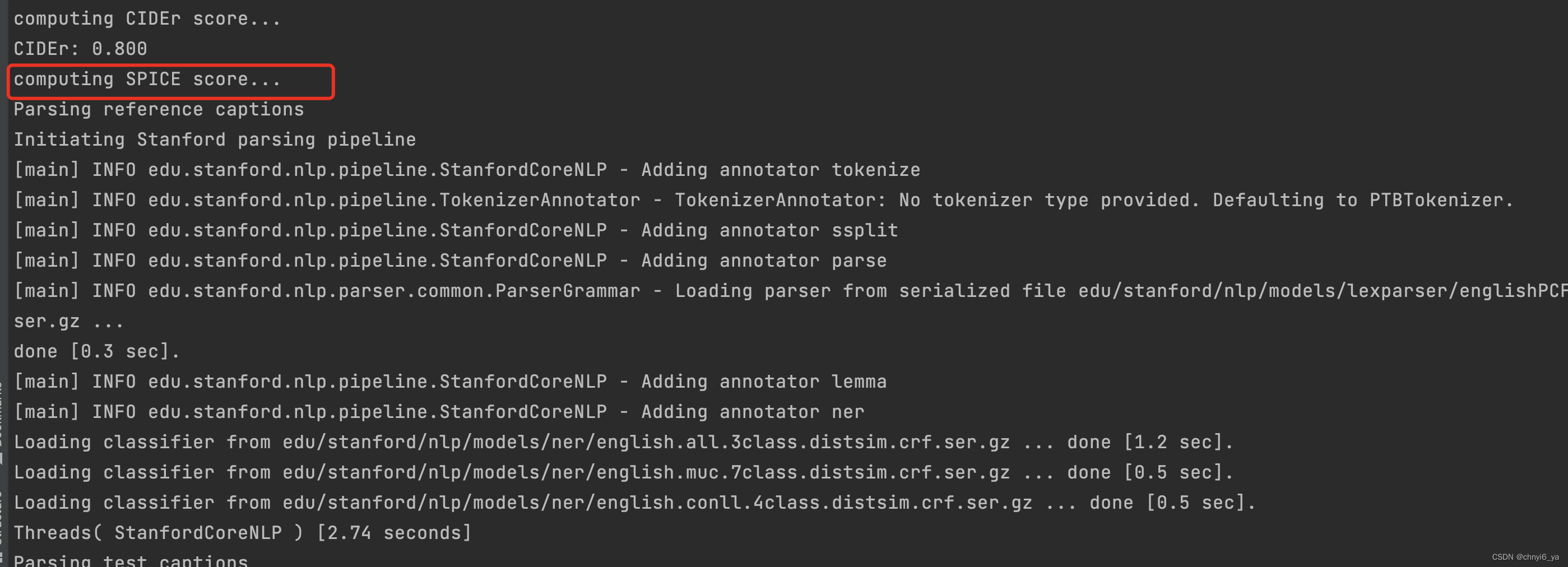
重新运行代码,就评估成功啦~















 1826
1826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









