







1 研究任务一介绍
1.1 研究任务
实验首先对Titanic数据集进行数据分析和清理,然后分别采用Logistic Regression(逻辑回归)、Support Vector Machines(SVM,支持向量机)、Decision Tree Classifier(决策树分类器)、Random Forest Classifier(随机森林分类器)等机器学习算法预测哪些乘客在这场悲剧中幸存下来。
代码:链接:https://pan.baidu.com/s/17WRKqtYraGHxnOe3NiH3Rg?pwd=v8w4
提取码:v8w4
1.2 研究内容的具体描述
数据分为两组:
1)训练集(train.csv)891行,用于构建机器学习模型。训练集提供每位乘客的结果(也称为“基本事实”)。模型将基于乘客性别等特征创建。
2)测试集(test.csv)418行,用于查看模型的表现。测试集不提供每位乘客的真实情况。使用训练的模型预测测试集中的每位乘客是否在泰坦尼克号沉没中幸存下来。
数据集每一列的简要信息:
1)PassengerId:乘客行的唯一索引,从第一行1开始,每新行增加 1。
2)Survived: 显示乘客是否幸存,1代表幸存,0代表未幸存。
3)Pclass: 票类,1代表头等舱票,2 代表二等票,3 代表三等车票。
4)Name: 乘客姓名。
5)Sex:乘客性别。
6)Age: 乘客年龄。
7)SibSp:与每位乘客同行的兄弟姐妹或配偶的数量。
8)Parch:每名乘客随行儿童的父母人数。
9)Ticket: 票号。
10)Fare: 票价。
11)Cabin:乘客客舱号码,NaN表示该特定乘客的客舱编号尚未记录。
12)Embarked: 特定乘客登船/登船的港口。
2 研究方法原理与步骤
2.1 步骤
1、titanic.py
1)导入必要的库
数据分析库:numpy、pandas
可视化库:matplotlib、seaborn
2)读入并探索历史数据
3)数据分析
获取数据集中的特征列表,查看数据类型,检查任何其他不可用的值。
4)数据可视化
绘制Sex、Pclass、SibSp、Parch、Age、Cabin等特征与生存的条形图,分析哪些特征在预测中比较重要,以及具有哪些特征的乘客更易存活。
5)清理数据
清理数据解决缺失值和不必要的信息,查看测试数据,并将年龄值、性别值、 Embarked值、票价值映射到数值或数值组。
2、model.py
6)测试不同的模型,选择最佳模型
Logistic Regression逻辑回归
Support Vector Machines,SVM支持向量机
Decision Tree Classifier决策树分类器
Random Forest Classifier随机森林分类器
7)创建提交文件
创建 submit.csv 文件,包含对测试数据的预测,将ID设置为PassengerId并预测生存。
2.2 Logistic Regression(逻辑回归)
Logistic回归是广义的线性回归,主要处理二分类问题。

图2.1 Logistic回归计算图
输入特征向量x,x表示样本,w表示参数向量;b是偏置。y是标签(表示是否生存,0否1是),线性回归的输出:h= x*w,然后把这个输出输入到激活函数sigmoid中得到大于0的概率值。
2.3 Support Vector Machines(支持向量机)
支持向量机(support vector machines,SVM)是二分类模型,将实例的特征向量映射为空间中的点,如下图的实心点和空心点,它们属于不同的两类。SVM 的目的是画出一条线区分这两类点。SVM 适合中小型数据样本、非线性、高维的分类问题。

图2.2 SVM原理图
SVM两大分支:Support Vector Classifier(SVC)与Support Vector Regressor(SVR)。
对于SVC,函数间隔: minγ=wx+bminγ=wx+b,此时如果倍增w,bw,b可以无限扩大函数间隔,因此,它并不能作为标准几何间隔,是归一化的函数间隔: minγ=wx+b||w||minγ=wx+b||w||
为了方便讨论,令几何间隔等于1,有
wxi+b≥1foryi=+1wxi+b≥1foryi=+1
wxi+b≤−1foryi=−1
2.4 Decision Tree Classifier(决策树分类)
决策树(decision tree):是一种基本的分类与回归方法。在分类问题中,表示基于特征对实例进行分类的过程,可以认为是if-then的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。
决策树通常有三个步骤:特征选择、决策树的生成、决策树的修剪。用决策树分类:从根节点开始,对实例的某一特征进行测试,根据测试结果将实例分配到其子节点,此时每个子节点对应着该特征的一个取值,如此递归的对实例进行测试并分配,直到到达叶节点,最后将实例分到叶节点的类中。
决策树学习的目标:根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类。
决策树学习的损失函数:正则化的极大似然函数。
决策树学习的测试:最小化损失函数。
决策树学习的目标:在损失函数的意义下,选择最优决策树的问题。

图2.3 决策树流程图
上图为一个决策树流程图,正方形代表判断模块,椭圆代表终止模块,表示已经得出结论,可以终止运行,左右箭头叫做分支。
2.5 Random Forest Classifier(随机森林分类)
随机森林(Random Forest,简称RF),是通过集成学习的思想将多棵树集成的算法,基本单元是决策树,本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。
从直观角度解释,每棵决策树都是一个分类器,那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的 Bagging 思想。
我们前边提到,随机森林是一种很灵活实用的方法,它有如下几个特点:
随机森林具有以下优点:能够有效运行在大数据集上;能够处理具有高维特征的输入样本,而且不需要降维;能够评估各个特征在分类问题上的重要性;在生成过程中,能够获取到内部生成误差的一种无偏估计;对于缺省值问题也能够获得很好得结果。
3 实验结果及分析
3.1 实验结果
3.1.1 开发环境介绍
系统:Win7
处理器:Intel(R) Core(TM)i5-5200U CPU
内存:4G
软件:Python 3.6.5
3.1.2 性能评估指标介绍
指标计算:
准确率: 分类正确的样本数与样本总数之比
Accuracy = (TP + TN) / (TP + FN + FP + TN)
TP(True Positive):被检索到正样本,实际也是正样本(正确识别)
FP(False Positive):被检索到正样本,实际是负样本(一类错误识别)
FN(False Negative):未被检索到正样本,实际是正样本(二类错误识别)
TN(True Negative):未被检索到正样本,实际也是负样本(正确识别)
3.1.3 实验结果
一些特征与生存的条形图如下:

图3.1 Sex特征与生存的条形图

图3.2 Pclass特征与生存的条形图
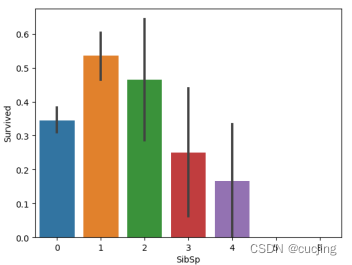
图3.3 SibSp特征与生存的条形图

图3.4 Parch特征与生存的条形图

图3.5 Age特征与生存的条形图

图3.6 Cabin特征与生存的条形图
四种机器学习算法准确率如下:
表3.1 四种算法准确率
| 机器学习算法 | Accuracy(%) |
| Logistic回归 | 77.1 |
| SVM | 79.9 |
| 决策树 | 72.6 |
| 随机森林 | 80.5 |
3.2 实验结果分析
有数据分析可知,Sex、Pclass、SibSp、Parch、Age、Cabin等特征在生存预测中比较重要。由图3.1可知,一些女性的生存机会比男性高得多。由图3.2可知,票类等级越高生存机会越大。由图3.3可知,有更多兄弟姐妹的人或船上的配偶生存的可能性较小,而没有兄弟姐妹的人或配偶比有一两个的人更不可能生存。由图3.4可知,父母或孩子少于四人的人比四人或四人以上的人更有可能生存,与有1-3个父母或孩子的人相比,独自旅行的人生存的可能性更小。由图3.5可知,婴儿比任何其他年龄组更有可能存活。由图3.6可知,有记录的客舱号码的人,更有可能存活下来。
采用Logistic 回归、SVM、决策树、随机森林等机器学习算法进行生存预测,结果如表3.1所示,随机森林分类和SVM在准确率性能上效果相对较好,分别为80.5%和79.9%,Logistic回归次之为77.1%,决策树较差为72.6%。
4 结论
结果表明,随机森林分类和SVM对于Titanic数据集进行生存预测时,在准确率性能上效果较好。
对于拥有缺失值的数据,决策树可以应对,而逻辑回归需要挖掘人员预先对缺失数据进行处理。逻辑回归对数据整体结构的分析优于决策树,而决策树对局部结构的分析优于逻辑回归。决策树的结果和逻辑回归相比略显粗糙。逻辑回归原则上可以提供数据中每个观察点的概率,而决策树只能把挖掘对象分为有限的概率组群。SVM能够处理大型特征空间,但当观测样本很多时,效率并不是很高,有时候很难找到一个合适的核函数。随机森林是决策树的升级版,多个分类器的效果往往优于单个分类器的效果。
后续可以考虑将不同机器学习算法结合,以优化算法性能。
















 1001
1001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











