







参考ChatGLM3-6B仓库https://github.com/THUDM/ChatGLM-6B/和仓库https://github.com/datawhalechina/self-llm/blob/master,这里使用的是autodl平台的3090(24G)的显卡机器,镜像选择Pytorch->2.0.0->3.8(ubuntu20.04)->11.8。
环境配置
创建一个独立的环境,AutoDL不支持conda activate
conda create -n chatglm3-6b python=3.8
source activate chatglm3-6b
pip换源和安装依赖包
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install fastapi==0.104.1
pip install uvicorn==0.24.0.post1
pip install requests==2.25.1
pip install modelscope==1.9.5
pip install transformers==4.37.2
pip install streamlit==1.24.0
pip install sentencepiece==0.1.99
pip install accelerate==0.24.1
使用 modelscope 中的snapshot_download函数下载模型,第一个参数为模型名称,参数cache_dir为模型的下载路径。
在 /root/autodl-tmp 路径下新建 download.py 文件并在其中输入以下内容,粘贴代码后记得保存文件,如下图所示。并运行 python /root/autodl-tmp/download.py执行下载,模型大小为 14 GB,下载模型大概需要 10~20 分钟
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('ZhipuAI/chatglm3-6b', cache_dir='/root/autodl-tmp', revision='master')
Python Client端
client_demo.py
import os # 导入os模块,用于操作系统功能
import platform # 导入platform模块,用于获取操作系统信息
from transformers import AutoTokenizer, AutoModel # 从transformer导入AutoTokenizer和AutoModel类
# 初始化分词器tokenizer和模型,将其放到GPU上运行,使用半精度浮点数减少内存使用
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/ZhipuAI/chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("/root/autodl-tmp/ZhipuAI/chatglm3-6b", trust_remote_code=True).half().cuda()
model = model.eval() # 设置模型评估模式
os_name = platform.system() # 获取当前操作系统的名称
clear_command = 'cls' if os_name == 'Windows' else 'clear' # 根据操作系系统设置清屏命令,Windows使用cls,其他使用clear
def build_prompt(history):
# 定义一个函数,用于构建聊天的提示信息
prompt = "欢迎使用 ChatGLM-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序"
for item in history:
if item['role'] == 'user':
query = item['content']
prompt += f"\n\n用户:{query}"
elif item['role'] == 'assistant':
response = item['content']
prompt += f"\n\nChatGLM-6B:{response}"
return prompt
def main():
# 定义主函数
history = [] # 初始化对话历史列表
while True:
query = input("\n用户:") # 用户输入文本,如果输入stop则退出循环,如果输入clear则清空对话历史
if query == "stop":
break
if query == "clear":
history = []
os.system(clear_command)
print("欢迎使用 ChatGLM-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")
continue
count = 0
for response, history in model.stream_chat(tokenizer, query, history=history): # 调用模型的stream_chat方法,进行流式输出
count += 1
if count % 8 == 0: # 每8次输出后清屏并打印当前的对话历史
os.system(clear_command)
print(build_prompt(history), flush=True)
os.system(clear_command) # 在一轮对话结束后清屏
print(build_prompt(history), flush=True) # 打印最终的对话历史
if __name__ == "__main__":
main()
直接python client_demo.py运行结果如下:
欢迎使用 ChatGLM-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序
用户:你好
ChatGLM-6B:你好👋!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。
用户:你的流式输出和批量输出的方式是什么
ChatGLM-6B:我的流式输出和批量输出的方式如下:
1. 流式输出:
流式输出是指按照一定的格式,以实时的方式输出信息。对于我来说,流式输出主要是指在对话过程中,根据你的问题,我实时地回答你。这种输出方式更加适用于实时交互场景,比如在线聊天、语音识别等。
2. 批量输出:
批量输出是指在同一时间,输出多个信息。对于我来说,批量输出主要是指在一次性对话中,回答你多个相关问题。这种输出方式更加适用于需要一次性获取多组信息场景。
以上两种输出方式可以根据实际需求进行选择。如果你有其他问题,欢迎继续提问。
批量输出写法
history = []
print("欢迎使用 ChatGLM-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")
queries = ["你好", "今天天气很好", "你喜欢做什么事"]
for query in queries:
response, history = model.chat(tokenizer, query, history=history)
print(build_prompt(history), flush=True)
Web端
Gradio
web_gradio_demo.py
from transformers import AutoModel, AutoTokenizer # 加载和使用预训练的模型和分词器
import gradio as gr # gradio用于创建web界面
import os
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/ZhipuAI/chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("/root/autodl-tmp/ZhipuAI/chatglm3-6b", trust_remote_code=True).half().cuda()
model = model.eval()
MAX_TURNS = 20 # 对话中最大轮数
MAX_BOXES = MAX_TURNS * 2 # 定义了界面上可以显示的最大文本框数量
def predict(query, max_length, top_p, temperature, history=None):
if history is None:
history = []
for _, history in model.stream_chat(tokenizer, query, history, max_length=max_length, top_p=top_p,
temperature=temperature):
updates = [] # 存储界面更新指令
for item in history:
if item['role'] == 'user':
query = item['content']
updates.append(gr.update(visible=True, value="用户:" + query))
elif item['role'] == 'assistant':
response = item['content']
updates.append(gr.update(visible=True, value="ChatGLM-6B:" + response))
if len(updates) < MAX_BOXES:
updates = updates + [gr.Textbox(visible=False)] * (MAX_BOXES - len(updates))
yield [history] + updates
def main():
with gr.Blocks() as demo: # 创建一个Gradio界面实例
state = gr.State([]) # 初始化state向量用于存储对话历史
text_boxes = []
for i in range(MAX_BOXES):
if i % 2 == 0:
text_boxes.append(gr.Markdown(visible=False, label="提问:"))
else:
text_boxes.append(gr.Markdown(visible=False, label="回复:"))
with gr.Row():
with gr.Column(scale=4):
txt = gr.Textbox(show_label=False, placeholder="Enter text and press enter", lines=11)
with gr.Column(scale=1):
max_length = gr.Slider(0, 4096, value=2048, step=1.0, label="Maximum length", interactive=True)
top_p = gr.Slider(0, 1, value=0.7, step=0.01, label="Top P", interactive=True)
temperature = gr.Slider(0, 1, value=0.95, step=0.01, label="Temperature", interactive=True)
button = gr.Button("Generate")
button.click(predict, [txt, max_length, top_p, temperature, state], [state] + text_boxes)
demo.queue().launch(share=False, inbrowser=True, server_port=6006)
if __name__ == '__main__':
main()
python web_gradio_demo运行后端,指定端口号为6006,这样可以用autoDL的自定义服务在本地访问,gradio会自动生成前端框架:
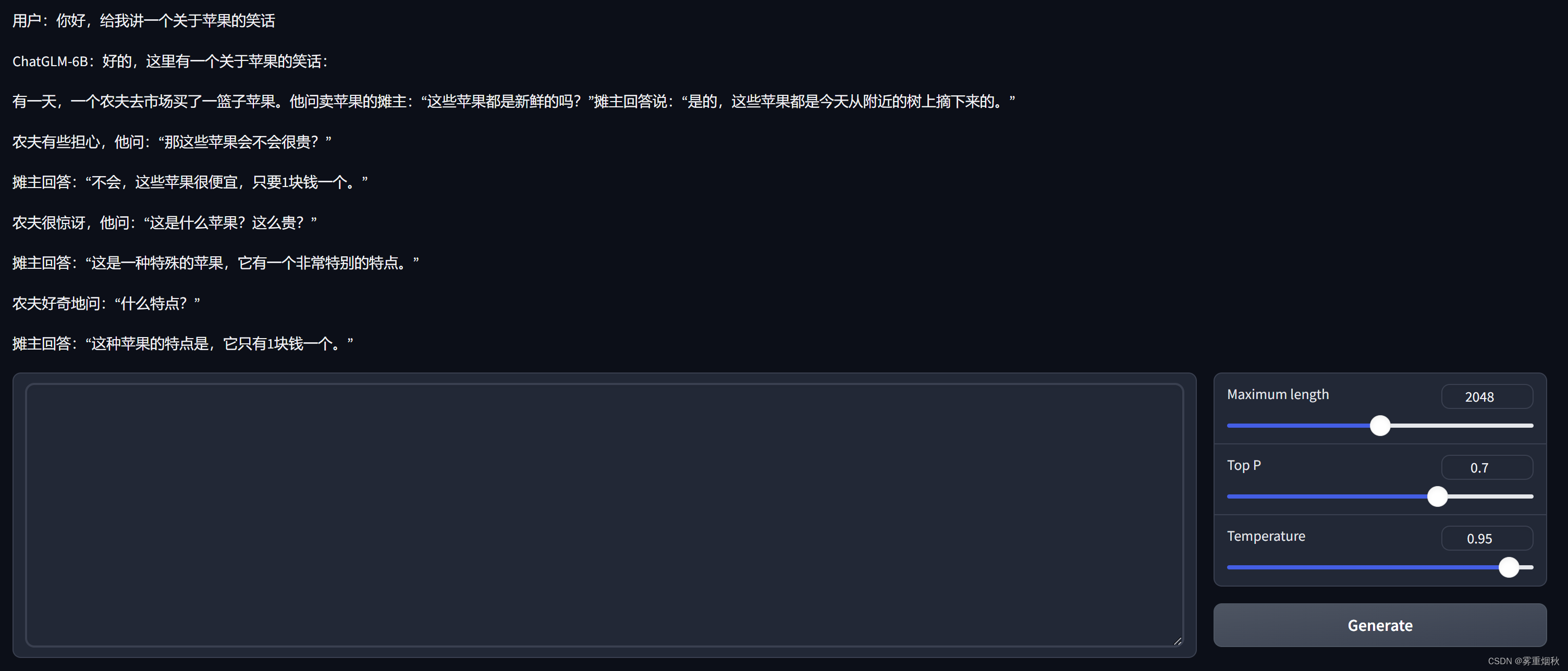
streamlit
web_streamlit_demo.py
from transformers import AutoModel, AutoTokenizer
import streamlit as st
from streamlit_chat import message
st.set_page_config(
page_title="ChatGLM-6b 演示",
page_icon=":robot:"
)
@st.cache_resource
def get_model():
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/ZhipuAI/chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("/root/autodl-tmp/ZhipuAI/chatglm3-6b", trust_remote_code=True).half().cuda()
model = model.eval()
return tokenizer, model
MAX_TURNS = 20
MAX_BOXES = MAX_TURNS * 2
def predict(input, history=None):
tokenizer, model = get_model()
if history is None:
history = []
with container:
if len(history) > 0:
for i, (query, response) in enumerate(history):
message(query, avatar_style="big-smile", key=str(i) + "_user")
message(response, avatar_style="bottts", key=str(i))
message(input, avatar_style="big-smile", key=str(len(history)) + "_user")
st.write("AI正在回复:")
with st.empty():
for response, history in model.stream_chat(tokenizer, input, history):
for item in history:
if item['role'] == 'user':
query = item['content']
elif item['role'] == 'assistant':
response = item['content']
st.write(response)
return history
container = st.container()
# create a prompt text for the text generation
prompt_text = st.text_area(label="用户命令输入",
height = 100,
placeholder="请在这儿输入您的命令")
if 'state' not in st.session_state:
st.session_state['state'] = []
if st.button("发送", key="predict"):
with st.spinner("AI正在思考,请稍等........"):
# text generation
st.session_state["state"] = predict(prompt_text, st.session_state["state"])
用streamlit run web_streamlit_demo.py --server.address 127.0.0.1 --server.port 6006运行,结果如下:
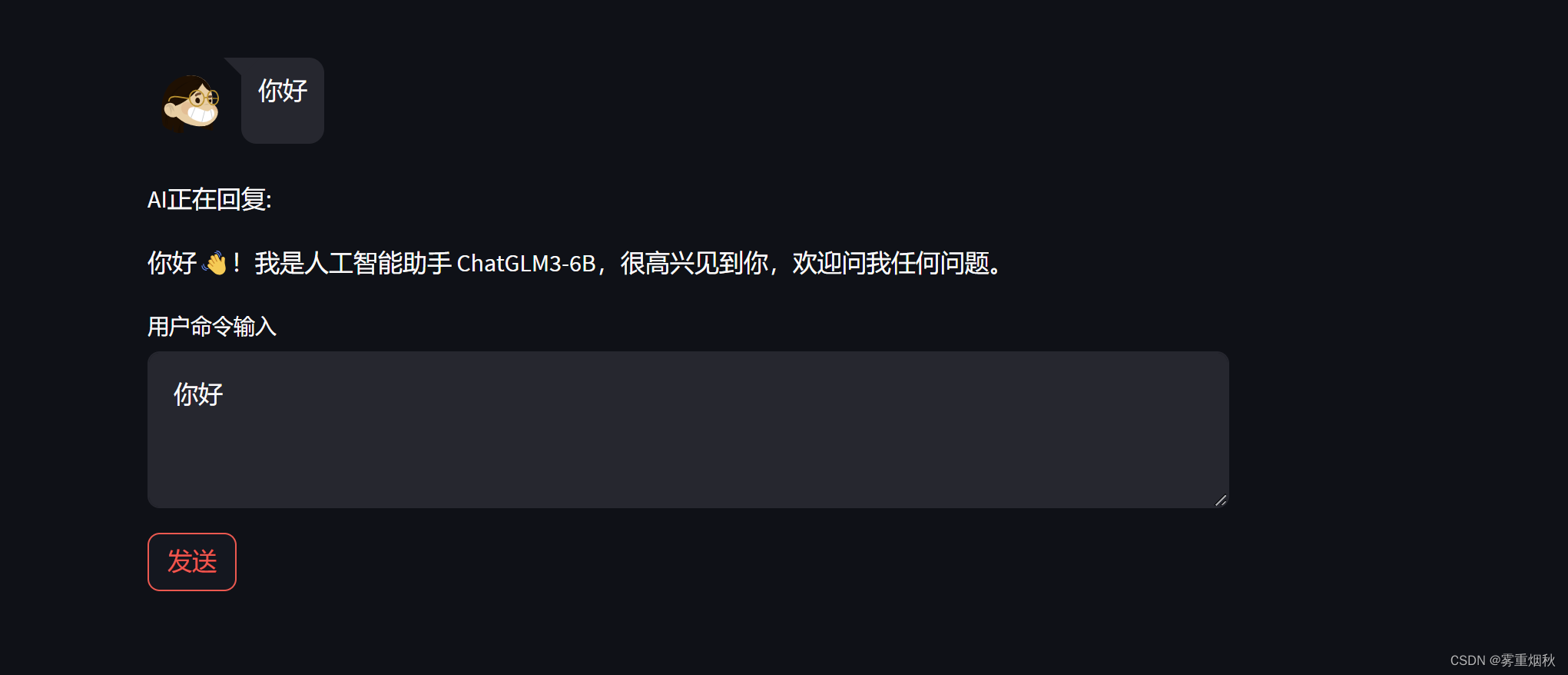
FastAPI+WebSocket
WebSocket API是一项先进的技术,它能够在用户的浏览器和服务器之间建立双向交互式通信会话。借助此API,你可以向服务器发送消息并接收事件驱动的响应,而无需轮询服务器以获取回复。之前使用的前后端交互方式都是请求-响应,用户提交数据后,服务器处理请求并返回响应,使用WebSocket允许服务器主动向客户端推送数据,FastAPI是一个高性能的Web框架,允许使用WebSocket来实现实时通讯。
# 导入FastAPI和WebSocket类,以及WebSocketDisconnect异常和HTMLResponse响应类
from fastapi import FastAPI, WebSocket, WebSocketDisconnect
from fastapi.responses import HTMLResponse
from fastapi.middleware.cors import CORSMiddleware # 导入CORS中间件,用于处理跨域资源共享(CORS)
from transformers import AutoTokenizer, AutoModel
# 导入uvicorn,轻量级的ASGI服务器
import uvicorn
pretrained = "/root/autodl-tmp/ZhipuAI/chatglm3-6b"
tokenizer = AutoTokenizer.from_pretrained(pretrained, trust_remote_code=True)
model = AutoModel.from_pretrained(pretrained, trust_remote_code=True).half().cuda()
model = model.eval()
app = FastAPI() # 创建一个FastAPI应用程序实例
# 添加CORS中间件到FastAPI应用程序,允许跨域请求
app.add_middleware(
CORSMiddleware
)
# 读取websocket_demo.html文件内容,用于返回HTML响应
with open('websocket_demo.html') as f:
html = f.read()
# 定义一个路由,当访问根路径(/)时,返回之前读取的HTML内容
@app.get("/")
async def get():
return HTMLResponse(html)
# 定义WebSocket端点/ws,创建WebSocket路由
@app.websocket("/ws")
async def websocket_endpoint(websocket: WebSocket):
"""
input: JSON String of {"query": "", "history": []}
output: JSON String of {"response": "", "history": [], "status": 200}
status 200 stand for response ended, else not
"""
await websocket.accept() # 接受WebSocket连接,并处理接收到的JSON格式消息
try:
while True:
json_request = await websocket.receive_json()
query = json_request['query']
history = json_request['history']
for response, history in model.stream_chat(tokenizer, query, history=history):
# 将生成的回复以JSON格式发送回客户端
await websocket.send_json({
"response": response,
"history": history,
"status": 202,
})
await websocket.send_json({"status": 200}) # stream_chat完成时发送状态码200
except WebSocketDisconnect:
pass
def main():
uvicorn.run(f"{__name__}:app", host='127.0.0.1', port=6006, workers=1) # 使用uvicorn.run启动FastAPI应用程序
if __name__ == '__main__':
main()
用python websocket_api.py运行结果如下:

前端代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<title>Chat</title>
</head>
<body>
<h1>WebSocket Chat</h1>
<form action="" onsubmit="return false;" id="form">
<label for="messageText"></label>
<input type="text" id="messageText" autocomplete="off"/>
<button type="submit">Send</button>
</form>
<ul id='messageBox'>
</ul>
<script>
let ws = new WebSocket("ws://" + location.host + "/ws");
let history = [];
let last_message_element = null;
function appendMessage(text, sender, dom = null) {
if (dom === null) {
let messageBox = document.getElementById('messageBox');
dom = document.createElement('li');
messageBox.appendChild(dom);
}
dom.innerText = sender + ':' + text;
return dom
}
function sendMessage(event) {
if (last_message_element !== null) { // 如果机器人还没回复完
return;
}
let input = document.getElementById("messageText");
if (input.value === "") {
return;
}
let body = {"query": input.value, 'history': history};
ws.send(JSON.stringify(body));
appendMessage(input.value, '用户')
input.value = '';
event.preventDefault();
}
document.getElementById("form").addEventListener('submit', sendMessage)
ws.onmessage = function (event) {
let body = JSON.parse(event.data);
let status = body['status']
if (status === 200) { // 如果回答结束了
last_message_element = null;
} else {
history = body['history']
last_message_element = appendMessage(body['response'], 'ChatGLM-6B', last_message_element)
}
};
</script>
</body>
</html>
清言智能体API调用
参考https://chatglm.cn/developersPanel/apiSet
api_key和api_secret从上述网址获得,assistant_id为自己的清言智能体的id。
import json
import requests
def get_access_token(api_key, api_secret):
url = "https://chatglm.cn/chatglm/assistant-api/v1/get_token"
data = {
"api_key": api_key,
"api_secret": api_secret
}
response = requests.post(url, json=data)
token_info = response.json()
return token_info['result']['access_token']
# Here you need to replace the API Key and API Secret with your,I provide a test key and secret here
api_key = ''
api_secret = ''
token = get_access_token(api_key, api_secret)
def handle_response(data_dict):
message = data_dict.get("message")
if len(message) > 0:
content = message.get("content")
if len(content) > 0:
response_type = content.get("type")
if response_type == "text":
text = content.get("text", "No text provided")
return f"{text}"
elif response_type == "image":
images = content.get("image", [])
image_urls = ", ".join(image.get("image_url") for image in images)
return f"{image_urls}"
elif response_type == "code":
return f"{content.get('code')}"
elif response_type == "execution_output":
return f"{content.get('content')}"
elif response_type == "system_error":
return f"{content.get('content')}"
elif response_type == "tool_calls":
return f"{data_dict['tool_calls']}"
elif response_type == "browser_result":
content = json.loads(content.get("content", "{}"))
return f"Browser Result - Title: {content.get('title')} URL: {content.get('url')}"
def send_message(assistant_id, access_token, prompt, conversation_id=None, file_list=None, meta_data=None):
url = "https://chatglm.cn/chatglm/assistant-api/v1/stream"
headers = {
"Authorization": f"Bearer {access_token}",
"Content-Type": "application/json"
}
data = {
"assistant_id": assistant_id,
"prompt": prompt,
}
if conversation_id:
data["conversation_id"] = conversation_id
if file_list:
data["file_list"] = file_list
if meta_data:
data["meta_data"] = meta_data
with requests.post(url, json=data, headers=headers) as response:
if response.status_code == 200:
for line in response.iter_lines():
if line:
decoded_line = line.decode('utf-8')
if decoded_line.startswith('data:'):
data_dict = json.loads(decoded_line[5:])
output = handle_response(data_dict)
else:
return "Request failed", response.status_code
print(output)
# This is the GLMs of zR, only zR's key can call this GLMs
assistant_id = ""
access_token = token
prompt = "介绍一下你自己"
result = send_message(assistant_id, access_token, prompt)
print(result)
嗨!我是萌动助聊,一个基于智谱 AI 公司于2023年训练的语言模型开发的聊天助手。我的主要任务是帮助用户进行有趣、可爱的对话,让聊天变得更加生动和愉快。我具备自动回复、表情包推荐和语音合成等能力,可以根据对话内容提供合适的回答和表情包,还能将文字回答转化为可爱的语音。我的目标是通过释放可爱魅力,让用户的聊天体验更加有趣和愉悦。
None
使用GLMs API转OpenAI接口
具体教程参考https://github.com/MetaGLM/glm-cookbook/blob/main/glms/api/glms_openai_api.ipynb
- 使用
.拼接key与Secret为API Key,如下:
21a**********9a0.2fa****************************237
Docker部署
docker --version
- 请准备一台具有公网IP的服务器并将8000端口开放。
- 拉取镜像并启动服务
docker run -it -d --init --name zhipuai-agent-to-openai -p 8000:8000 -e TZ=Asia/Shanghai vinlic/zhipuai-agent-to-openai:latest
- 查看服务实时日志
docker logs -f zhipuai-agent-to-openai
- 重启服务
docker restart zhipuai-agent-to-openai
- 停止服务
docker stop zhipuai-agent-to-openai
Docker-compose 部署
docker-compose --version
version: '3'
services:
zhipuai-agent-to-openai:
container_name: zhipuai-agent-to-openai
image: vinlic/zhipuai-agent-to-openai:latest
restart: always
ports:
- "8000:8000"
environment:
- TZ=Asia/Shanghai
docker-compose up
接入智能体能力
import os
from openai import OpenAI
# 在环境变量中设置OPENAI_API_BASE为您部署的zhipuai-agent-to-openai服务地址
BASE_URL = os.getenv("OPENAI_API_BASE", "http://127.0.0.1:8000/v1")
# 在环境变量中设置OPENAI_API_KEY为第一步拼接获得的API Key或者直接填写
API_KEY = os.getenv("OPENAI_API_KEY", "21a**********9a0.2fa****************************237")
client = OpenAI(
base_url=BASE_URL,
api_key=API_KEY
)
# 调用对话补全接口
result = client.chat.completions.create(
# 必须填写您自己创建的智能体ID,否则无法调用成功
model="65d6ba38fca9900836172419",
# 目前多轮对话基于消息合并实现,某些场景可能导致能力下降且受单轮最大token数限制
# 如果您想获得原生的多轮对话体验,可以传入首轮消息获得的id,来接续上下文
# "conversation_id": "65f6c28546bae1f0fbb532de",
messages=[
{
"role": "user",
"content": "你好"
}
],
# 如果使用SSE流请设置为true,默认false
stream=False
)
# 输出调用结果
print(result.choices[0].message.content)
自定义部署
参考https://github.com/THUDM/ChatGLM3/tree/main/openai_api_demo
docker-compose.yml
services: # 开始定义服务列表
glm3_api: # 服务名称为 glm3_api
image: python:3.10.13-slim # 使用的 Docker 镜像是 python 3.10.13-slim 版本
restart: unless-stopped # 容器停止时除非明确停止,否则会尝试重启
working_dir: /glm3 # 设置容器内的工作目录为 /glm3
container_name: glm3_api # 给容器设置一个名称 glm3_api
env_file: ./.env # 指定环境变量文件的路径
networks: # 定义容器连接的网络
- v_glm3 # 连接的网络名称为 v_glm3
deploy: # (此部分可能是多余的,因为 Docker Compose 不直接使用 'deploy' 键)
resources: # 定义资源分配
reservations: # 资源预留
devices: # 设备
- driver: nvidia # 使用 Nvidia 驱动
count: 1 # 预留 1 个设备
capabilities: [gpu] # 指定 GPU 能力
environment: # 设置环境变量
- MODEL_PATH=/models/chatglm3-6b # 模型路径环境变量
- EMBEDDING_PATH=/models/bge-large-zh-v1.5 # 嵌入模型路径环境变量
- TZ=Asia/Shanghai # 设置时区为上海
- PYTHONDONTWRITEBYTECODE=1 # 禁止 Python 写入 __pycache__ 文件夹
- PYTHONUNBUFFERED=1 # 禁止 Python 缓冲输出
- DOCKER=True # 指示应用运行在 Docker 中
ports: # 端口映射
- 8100:8000 # 将容器的 8000 端口映射到宿主机的 8100 端口
volumes: # 卷挂载
- ./:/glm3 # 将当前目录挂载到容器的 /glm3 目录
- ${LOCAL_MODEL_PATH}:/models/chatglm3-6b # 将宿主机的本地模型路径挂载到容器的模型路径
- ${LOCAL_EMBEDDING_MODEL_PATH}:/models/bge-large-zh-v1.5 # 将宿主机的嵌入模型路径挂载到容器的嵌入模型路径
command: # 容器启动时执行的命令
- sh # 使用 sh 作为 shell
- -c # 用 --command 的方式执行一串命令
- | # 多行命令
sed -i s/deb.debian.org/mirrors.tencentyun.com/g /etc/apt/sources.list # 替换 Debian 源为腾讯云镜像
sed -i s/security.debian.org/mirrors.tencentyun.com/g /etc/apt/sources.list # 替换 Debian 安全源为腾讯云镜像
apt-get update # 更新包列表
python -m pip install -i https://mirror.sjtu.edu.cn/pypi/web/simple --upgrade pip # 使用上海交通大学的镜像升级 pip
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple # 使用清华大学的镜像安装依赖
python api_server.py # 运行 api_server.py 脚本
networks: # 定义网络
v_glm3: # 网络名称为 v_glm3
driver: bridge # 使用桥接网络模式
api_server.py
"""
This script implements an API for the ChatGLM3-6B model,
formatted similarly to OpenAI's API (https://platform.openai.com/docs/api-reference/chat).
It's designed to be run as a web server using FastAPI and uvicorn,
making the ChatGLM3-6B model accessible through OpenAI Client.
Key Components and Features:
- Model and Tokenizer Setup: Configures the model and tokenizer paths and loads them.
- FastAPI Configuration: Sets up a FastAPI application with CORS middleware for handling cross-origin requests.
- API Endpoints:
- "/v1/models": Lists the available models, specifically ChatGLM3-6B.
- "/v1/chat/completions": Processes chat completion requests with options for streaming and regular responses.
- "/v1/embeddings": Processes Embedding request of a list of text inputs.
- Token Limit Caution: In the OpenAI API, 'max_tokens' is equivalent to HuggingFace's 'max_new_tokens', not 'max_length'.
For instance, setting 'max_tokens' to 8192 for a 6b model would result in an error due to the model's inability to output
that many tokens after accounting for the history and prompt tokens.
- Stream Handling and Custom Functions: Manages streaming responses and custom function calls within chat responses.
- Pydantic Models: Defines structured models for requests and responses, enhancing API documentation and type safety.
- Main Execution: Initializes the model and tokenizer, and starts the FastAPI app on the designated host and port.
Note:
This script doesn't include the setup for special tokens or multi-GPU support by default.
Users need to configure their special tokens and can enable multi-GPU support as per the provided instructions.
Embedding Models only support in One GPU.
Running this script requires 14-15GB of GPU memory. 2 GB for the embedding model and 12-13 GB for the FP16 ChatGLM3 LLM.
"""
import os
import time
import tiktoken
import torch
import uvicorn
from fastapi import FastAPI, HTTPException, Response
from fastapi.middleware.cors import CORSMiddleware
from contextlib import asynccontextmanager
from typing import List, Literal, Optional, Union
from loguru import logger
from pydantic import BaseModel, Field
from transformers import AutoTokenizer, AutoModel
from utils import process_response, generate_chatglm3, generate_stream_chatglm3
from sentence_transformers import SentenceTransformer
from sse_starlette.sse import EventSourceResponse
# Set up limit request time
EventSourceResponse.DEFAULT_PING_INTERVAL = 1000
# set LLM path
MODEL_PATH = os.environ.get('MODEL_PATH', 'THUDM/chatglm3-6b')
TOKENIZER_PATH = os.environ.get("TOKENIZER_PATH", MODEL_PATH)
# set Embedding Model path
EMBEDDING_PATH = os.environ.get('EMBEDDING_PATH', 'BAAI/bge-m3')
@asynccontextmanager
async def lifespan(app: FastAPI):
yield
if torch.cuda.is_available():
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
app = FastAPI(lifespan=lifespan)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
class ModelCard(BaseModel):
id: str
object: str = "model"
created: int = Field(default_factory=lambda: int(time.time()))
owned_by: str = "owner"
root: Optional[str] = None
parent: Optional[str] = None
permission: Optional[list] = None
class ModelList(BaseModel):
object: str = "list"
data: List[ModelCard] = []
class FunctionCallResponse(BaseModel):
name: Optional[str] = None
arguments: Optional[str] = None
class ChatMessage(BaseModel):
role: Literal["user", "assistant", "system", "function"]
content: str = None
name: Optional[str] = None
function_call: Optional[FunctionCallResponse] = None
class DeltaMessage(BaseModel):
role: Optional[Literal["user", "assistant", "system"]] = None
content: Optional[str] = None
function_call: Optional[FunctionCallResponse] = None
## for Embedding
class EmbeddingRequest(BaseModel):
input: Union[List[str], str]
model: str
class CompletionUsage(BaseModel):
prompt_tokens: int
completion_tokens: int
total_tokens: int
class EmbeddingResponse(BaseModel):
data: list
model: str
object: str
usage: CompletionUsage
# for ChatCompletionRequest
class UsageInfo(BaseModel):
prompt_tokens: int = 0
total_tokens: int = 0
completion_tokens: Optional[int] = 0
class ChatCompletionRequest(BaseModel):
model: str
messages: List[ChatMessage]
temperature: Optional[float] = 0.8
top_p: Optional[float] = 0.8
max_tokens: Optional[int] = None
stream: Optional[bool] = False
tools: Optional[Union[dict, List[dict]]] = None
repetition_penalty: Optional[float] = 1.1
class ChatCompletionResponseChoice(BaseModel):
index: int
message: ChatMessage
finish_reason: Literal["stop", "length", "function_call"]
class ChatCompletionResponseStreamChoice(BaseModel):
delta: DeltaMessage
finish_reason: Optional[Literal["stop", "length", "function_call"]]
index: int
class ChatCompletionResponse(BaseModel):
model: str
id: str
object: Literal["chat.completion", "chat.completion.chunk"]
choices: List[Union[ChatCompletionResponseChoice, ChatCompletionResponseStreamChoice]]
created: Optional[int] = Field(default_factory=lambda: int(time.time()))
usage: Optional[UsageInfo] = None
@app.get("/health")
async def health() -> Response:
"""Health check."""
return Response(status_code=200)
@app.post("/v1/embeddings", response_model=EmbeddingResponse)
async def get_embeddings(request: EmbeddingRequest):
if isinstance(request.input, str):
embeddings = [embedding_model.encode(request.input)]
else:
embeddings = [embedding_model.encode(text) for text in request.input]
embeddings = [embedding.tolist() for embedding in embeddings]
def num_tokens_from_string(string: str) -> int:
"""
Returns the number of tokens in a text string.
use cl100k_base tokenizer
"""
encoding = tiktoken.get_encoding('cl100k_base')
num_tokens = len(encoding.encode(string))
return num_tokens
response = {
"data": [
{
"object": "embedding",
"embedding": embedding,
"index": index
}
for index, embedding in enumerate(embeddings)
],
"model": request.model,
"object": "list",
"usage": CompletionUsage(
prompt_tokens=sum(len(text.split()) for text in request.input),
completion_tokens=0,
total_tokens=sum(num_tokens_from_string(text) for text in request.input),
)
}
return response
@app.get("/v1/models", response_model=ModelList)
async def list_models():
model_card = ModelCard(
id="chatglm3-6b"
)
return ModelList(
data=[model_card]
)
@app.post("/v1/chat/completions", response_model=ChatCompletionResponse)
async def create_chat_completion(request: ChatCompletionRequest):
global model, tokenizer
if len(request.messages) < 1 or request.messages[-1].role == "assistant":
raise HTTPException(status_code=400, detail="Invalid request")
gen_params = dict(
messages=request.messages,
temperature=request.temperature,
top_p=request.top_p,
max_tokens=request.max_tokens or 1024,
echo=False,
stream=request.stream,
repetition_penalty=request.repetition_penalty,
tools=request.tools,
)
logger.debug(f"==== request ====\n{gen_params}")
if request.stream:
# Use the stream mode to read the first few characters, if it is not a function call, direct stram output
predict_stream_generator = predict_stream(request.model, gen_params)
output = next(predict_stream_generator)
if not contains_custom_function(output):
return EventSourceResponse(predict_stream_generator, media_type="text/event-stream")
# Obtain the result directly at one time and determine whether tools needs to be called.
logger.debug(f"First result output:\n{output}")
function_call = None
if output and request.tools:
try:
function_call = process_response(output, use_tool=True)
except:
logger.warning("Failed to parse tool call")
# CallFunction
if isinstance(function_call, dict):
function_call = FunctionCallResponse(**function_call)
"""
In this demo, we did not register any tools.
You can use the tools that have been implemented in our `tools_using_demo` and implement your own streaming tool implementation here.
Similar to the following method:
function_args = json.loads(function_call.arguments)
tool_response = dispatch_tool(tool_name: str, tool_params: dict)
"""
tool_response = ""
if not gen_params.get("messages"):
gen_params["messages"] = []
gen_params["messages"].append(ChatMessage(
role="assistant",
content=output,
))
gen_params["messages"].append(ChatMessage(
role="function",
name=function_call.name,
content=tool_response,
))
# Streaming output of results after function calls
generate = predict(request.model, gen_params)
return EventSourceResponse(generate, media_type="text/event-stream")
else:
# Handled to avoid exceptions in the above parsing function process.
generate = parse_output_text(request.model, output)
return EventSourceResponse(generate, media_type="text/event-stream")
# Here is the handling of stream = False
response = generate_chatglm3(model, tokenizer, gen_params)
# Remove the first newline character
if response["text"].startswith("\n"):
response["text"] = response["text"][1:]
response["text"] = response["text"].strip()
usage = UsageInfo()
function_call, finish_reason = None, "stop"
if request.tools:
try:
function_call = process_response(response["text"], use_tool=True)
except:
logger.warning("Failed to parse tool call, maybe the response is not a tool call or have been answered.")
if isinstance(function_call, dict):
finish_reason = "function_call"
function_call = FunctionCallResponse(**function_call)
message = ChatMessage(
role="assistant",
content=response["text"],
function_call=function_call if isinstance(function_call, FunctionCallResponse) else None,
)
logger.debug(f"==== message ====\n{message}")
choice_data = ChatCompletionResponseChoice(
index=0,
message=message,
finish_reason=finish_reason,
)
task_usage = UsageInfo.model_validate(response["usage"])
for usage_key, usage_value in task_usage.model_dump().items():
setattr(usage, usage_key, getattr(usage, usage_key) + usage_value)
return ChatCompletionResponse(
model=request.model,
id="", # for open_source model, id is empty
choices=[choice_data],
object="chat.completion",
usage=usage
)
async def predict(model_id: str, params: dict):
global model, tokenizer
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=DeltaMessage(role="assistant"),
finish_reason=None
)
chunk = ChatCompletionResponse(model=model_id, id="", choices=[choice_data], object="chat.completion.chunk")
yield "{}".format(chunk.model_dump_json(exclude_unset=True))
previous_text = ""
for new_response in generate_stream_chatglm3(model, tokenizer, params):
decoded_unicode = new_response["text"]
delta_text = decoded_unicode[len(previous_text):]
previous_text = decoded_unicode
finish_reason = new_response["finish_reason"]
if len(delta_text) == 0 and finish_reason != "function_call":
continue
function_call = None
if finish_reason == "function_call":
try:
function_call = process_response(decoded_unicode, use_tool=True)
except:
logger.warning(
"Failed to parse tool call, maybe the response is not a tool call or have been answered.")
if isinstance(function_call, dict):
function_call = FunctionCallResponse(**function_call)
delta = DeltaMessage(
content=delta_text,
role="assistant",
function_call=function_call if isinstance(function_call, FunctionCallResponse) else None,
)
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=delta,
finish_reason=finish_reason
)
chunk = ChatCompletionResponse(
model=model_id,
id="",
choices=[choice_data],
object="chat.completion.chunk"
)
yield "{}".format(chunk.model_dump_json(exclude_unset=True))
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=DeltaMessage(),
finish_reason="stop"
)
chunk = ChatCompletionResponse(
model=model_id,
id="",
choices=[choice_data],
object="chat.completion.chunk"
)
yield "{}".format(chunk.model_dump_json(exclude_unset=True))
yield '[DONE]'
def predict_stream(model_id, gen_params):
"""
The function call is compatible with stream mode output.
The first seven characters are determined.
If not a function call, the stream output is directly generated.
Otherwise, the complete character content of the function call is returned.
:param model_id:
:param gen_params:
:return:
"""
output = ""
is_function_call = False
has_send_first_chunk = False
for new_response in generate_stream_chatglm3(model, tokenizer, gen_params):
decoded_unicode = new_response["text"]
delta_text = decoded_unicode[len(output):]
output = decoded_unicode
# When it is not a function call and the character length is> 7,
# try to judge whether it is a function call according to the special function prefix
if not is_function_call and len(output) > 7:
# Determine whether a function is called
is_function_call = contains_custom_function(output)
if is_function_call:
continue
# Non-function call, direct stream output
finish_reason = new_response["finish_reason"]
# Send an empty string first to avoid truncation by subsequent next() operations.
if not has_send_first_chunk:
message = DeltaMessage(
content="",
role="assistant",
function_call=None,
)
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=message,
finish_reason=finish_reason
)
chunk = ChatCompletionResponse(
model=model_id,
id="",
choices=[choice_data],
created=int(time.time()),
object="chat.completion.chunk"
)
yield "{}".format(chunk.model_dump_json(exclude_unset=True))
send_msg = delta_text if has_send_first_chunk else output
has_send_first_chunk = True
message = DeltaMessage(
content=send_msg,
role="assistant",
function_call=None,
)
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=message,
finish_reason=finish_reason
)
chunk = ChatCompletionResponse(
model=model_id,
id="",
choices=[choice_data],
created=int(time.time()),
object="chat.completion.chunk"
)
yield "{}".format(chunk.model_dump_json(exclude_unset=True))
if is_function_call:
yield output
else:
yield '[DONE]'
async def parse_output_text(model_id: str, value: str):
"""
Directly output the text content of value
:param model_id:
:param value:
:return:
"""
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=DeltaMessage(role="assistant", content=value),
finish_reason=None
)
chunk = ChatCompletionResponse(model=model_id, id="", choices=[choice_data], object="chat.completion.chunk")
yield "{}".format(chunk.model_dump_json(exclude_unset=True))
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=DeltaMessage(),
finish_reason="stop"
)
chunk = ChatCompletionResponse(model=model_id, id="", choices=[choice_data], object="chat.completion.chunk")
yield "{}".format(chunk.model_dump_json(exclude_unset=True))
yield '[DONE]'
def contains_custom_function(value: str) -> bool:
"""
Determine whether 'function_call' according to a special function prefix.
For example, the functions defined in "tools_using_demo/tool_register.py" are all "get_xxx" and start with "get_"
[Note] This is not a rigorous judgment method, only for reference.
:param value:
:return:
"""
return value and 'get_' in value
if __name__ == "__main__":
# Load LLM
tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True)
model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True, device_map="auto").eval()
# load Embedding
embedding_model = SentenceTransformer(EMBEDDING_PATH, device="cuda")
uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
openai_api_request.py
"""
此脚本是使用 OpenAI API 创建与 ChatGLM3 模型的各种交互的示例。
它包括以下功能:
1. 进行基本的聊天会话,询问多个城市的天气状况。
2. 发起简单的中文聊天,请模特讲一个小故事。
3. 检索并打印给定文本输入的嵌入。
每个函数都展示了 API 功能的不同方面,展示了如何发出请求
并处理响应。
"""
from openai import OpenAI
# 使用OpenAI API创建与ChatGLM3模型交互的OpenAI客户端实例
base_url = "http://127.0.0.1:6006/v1/"
client = OpenAI(api_key="2d7a05fd1282e7a2", base_url=base_url)
# 聊天会话函数,
def function_chat():
messages = [{"role": "user", "content": "What's the weather like in San Francisco, Tokyo, and Paris?"}]
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
},
}
]
# 调用chat.completions.create方法,发送聊天请求到API服务
response = client.chat.completions.create(
model="chatglm3-6b",
messages=messages,
tools=tools,
tool_choice="auto",
)
if response:
content = response.choices[0].message.content
print(content)
else:
print("Error:", response.status_code)
# 简单聊天函数,说一个短故事
def simple_chat(use_stream=True):
messages = [
{
"role": "system",
"content": "You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's "
"instructions carefully. Respond using markdown.",
},
{
"role": "user",
"content": "你好,请你用生动的话语给我讲一个小故事吧"
}
]
response = client.chat.completions.create(
model="chatglm3-6b",
messages=messages,
stream=use_stream,
max_tokens=256,
temperature=0.8,
presence_penalty=1.1,
top_p=0.8)
if response:
if use_stream:
for chunk in response:
print(chunk.choices[0].delta.content)
else:
content = response.choices[0].message.content
print(content)
else:
print("Error:", response.status_code)
# 定义embedding函数,用于获取给定文本输入的嵌入
def embedding():
response = client.embeddings.create(
model="bge-large-zh-1.5",
input=["你好,给我讲一个故事,大概100字"],
)
embeddings = response.data[0].embedding
print("嵌入完成,维度:", len(embeddings))
if __name__ == "__main__":
simple_chat(use_stream=False)
simple_chat(use_stream=True)
embedding()
function_chat()















 742
742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









