







 本文详细介绍了多目标进化优化算法SPEA2的流程,包括适应度计算、环境选择、档案截断法等关键步骤。SPEA2通过改进适应度分配,增加了个体间的竞争,以实现更好的解决方案集合。档案截断法通过删除距离最近的个体来维持归档集规模,确保多样性。该算法在多目标优化问题中表现出色。
本文详细介绍了多目标进化优化算法SPEA2的流程,包括适应度计算、环境选择、档案截断法等关键步骤。SPEA2通过改进适应度分配,增加了个体间的竞争,以实现更好的解决方案集合。档案截断法通过删除距离最近的个体来维持归档集规模,确保多样性。该算法在多目标优化问题中表现出色。
参考文献:多目标进化优算法(郑金华、邹娟著)
Zitzler和Thiele 于1999 年提出了SPEA (strength Paretoevolutionaryalgorithm) (Zitzleretal,1999),SPEA 中个体的适应度又称为strength,非支配集中个体的适应度定义为其所支配的个体总数在群体中所占的比重,其他个体的适应度定义为支配它的个体总数加1,约定适应度低的个体对应着高的复制概率。Zitzler等于2001年针对 SPEA 存在的不足,对SPEA 做了改进,提出了SPEA2。
接下来我将描述spea2算法的具体流程:(N 为进化群体P 的规模,M 为归档集Q 的大小,T 为预定的进化代数)
1: 初始化:产生一个初始群体P0,同时使归档集Q0为空,t=0。
2: 适应度分配:计算Pt和Qt中所有个体的适应度(计算适应度是为了后面的环境选择,非支配个体的适应度是小于1的个体)。
3: 环境选择:将Pt和Qt中所有非支配个体保存到Qt+1中。若归档集中的数量超过M,则利用档案截断法(即剪枝法) (archivetruncationprocedure)降低其大小;若 Qt+1的大小比 M 小,则从Pt和Qt中选取支配个体填满Qt+1。
4: 结束条件:若t≥T,或其他终止条件满足,则将 Qt+1中的所有非支配个体作为返回结果,保存到 NDSet中。
5: 配对选择:对Qt+1执行锦标赛选择。
6: 进化操作:对Qt+1执行交叉、变异操作,并将结果保存到Pt+1中,t=t+1,转步骤2
Spea2算法步骤的详解:
- 适应度计算:
F(i)=R(i)+D(i) (F(i)表示i的适应度)
R(i)= (j∈Pop+NDSet,j≻i)∑ S(j) (R(i)表示所有支配i的个体j所支配的个体数的和)
S(i)=|{j|j∈P+Q∧i≻j}| (S(i)表示i支配的个体数)
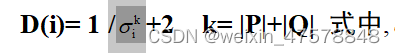 个体i到其第k 个邻近个体之间的距离。为此,需要计算个体i到进化群体P 和归档集Q 中其他所有个体之间的距离,并按增序排列。值得说明的是,SPEA 中计算个体i的适应度时只考虑了非支配集中支配i的个体的有 关信息。而在SPEA2中,计算R(i)时不仅考虑了非支配集中支配个体i的个体信息,同 时也考虑了进化群体中支配i的个体信息;此外,考虑到进化群体中,特别是非支配集中, 有些个体是相互都不被支配的,故而增加 D(i),D(i)是个体i到它的第k 个邻近个体的 距离的反函数。
个体i到其第k 个邻近个体之间的距离。为此,需要计算个体i到进化群体P 和归档集Q 中其他所有个体之间的距离,并按增序排列。值得说明的是,SPEA 中计算个体i的适应度时只考虑了非支配集中支配i的个体的有 关信息。而在SPEA2中,计算R(i)时不仅考虑了非支配集中支配个体i的个体信息,同 时也考虑了进化群体中支配i的个体信息;此外,考虑到进化群体中,特别是非支配集中, 有些个体是相互都不被支配的,故而增加 D(i),D(i)是个体i到它的第k 个邻近个体的 距离的反函数。
(2)档案截断法(剪枝法)
在构造新群体时,首先进行环境选择 (即选择那些非支配个体到归档集中,environmental selection),然后进行繁殖选择 (mating selection)。环境选择时,首先选择适应度值小于1的个体进入归档集Q 中,即 Qt+1={i|i∈Pt+Qt∧F(i)<1} 。此时,若Qt+1中个体数少于约定值 M,即|Qt+1|<M,则在上一代 Pt和Qt中选择 M -|Q|个适应度值小的优秀个体进入Qt+1中。若|Qt+1|>M,则按式 (2.1)修剪过程,依次选择个体i 从Qt+1 中删除,直至 |Qt+1|=M。
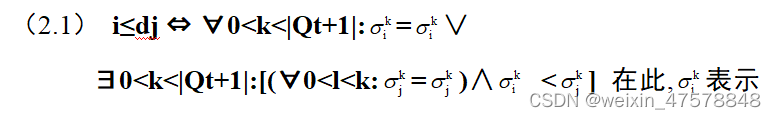
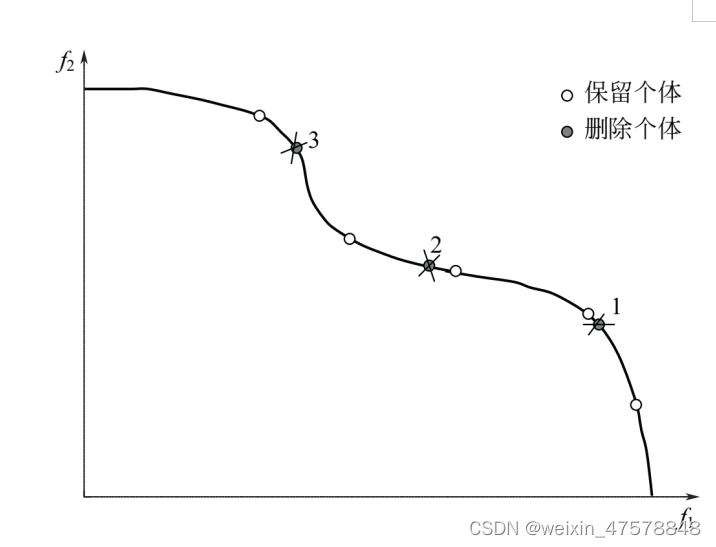
个体i与归档集Qt+1中第k 个个体之间的距离。也就是说,依次选择距离最近的个体删除。当有多个个体在与其前l(0<l<k,0<k<|Qt+1|)个邻近个体具有相同的最小距离时,而与其第k个邻近个体具有不同的距离时,则选取一个具有最小距离的个体删除。以上公式与解释比较抽象(反正我刚开始看是看不懂),我来说下我的理解:首先求出任意两点之间的距离,可以得到一张距离表,选择距离最小的两个点i、j,再选取i、j的第二近邻点,即距离i、j第二小的点,比较第二小近邻点的距离,i、j这两个个体哪个第二近邻点小就删除哪个(这样子就能确定删除的点是距离其他点最小的点),以此类推,这就是档案截断法。图6.10所示为两个目标求最大值的归档集修剪示例, 设归档集的规模 M 为5, 图中删除了3 个个体, 并标明了删除次序分别为1、 2 和3。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









