







文章目录
一、线性回归理论基础
一元线性回归是分析只有一个自变量(自变量x和因变量y)线性相关关系的方法。一元线性回归分析的数学模型为:y = a+bx+ε。
使用偏差平方和分别对参数a和参数b求偏导,可以得到线性模型的未知参数a、b的最小二乘估计值,其中,偏差平方和定义为∑(yi-a-bXi)2,a和b的唯一解如下图所示
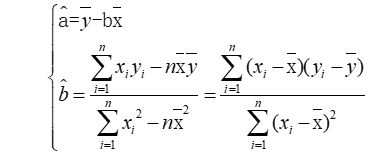
为了方便回归效果显著性检验,根据b的估计,引入LXX、LYY、LXY三个数学符号,这三个数学符号定义如下图所示。
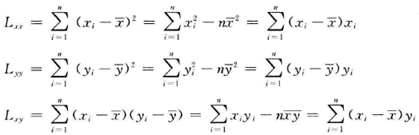
而在现实应用中,因变量的变化往往受多个自变量影响,此时就需要用到两个或两个以上的因素作为自变量来解释因变量的变化,这就叫做多元回归。也就是说,多元线性回归就是当多个自变量与因变量之间是线性关系时,所进行的回归就是多元线性回归。它的数学模型便是:y=β0+β1X1+β2X2+…+βpXp+ε
二、利用Excle进行线性回归分析
打开分析数据集,选择数据->数据分析

选择回归

选择对应的X、Y值
X值选择area、bedroom、bathroom
Y值选择price

点击确定得到结果
Price=10072.1+345.911 area-2925.8bedroom+7345.39*bathroom

三、基于statsmodels进行线性回归分析
1、导入数据及基础包
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv('D:/house_prices.csv')
df.info(); df.head()

2、数据清洗
z分数法:z分数(z-score),也叫标准分数(standard score)是一个数与平均数的差再除以标准差的过程。 在统计学中,标准分数是一个观测或数据点的值高于被观测值或测量值的平均值的标准偏差的符号数。
# 异常值处理
# ================ 异常值检验函数:iqr & z分数 两种方法 =========================
def outlier_test(data, column, method=None, z=2):
""" 以某列为依据,使用 上下截断点法 检测异常值(索引) """
"""
full_data: 完整数据
column: full_data 中的指定行,格式 'x' 带引号
return 可选; outlier: 异常值数据框
upper: 上截断点; lower: 下截断点
method:检验异常值的方法(可选, 默认的 None 为上下截断点法),
选 Z 方法时,Z 默认为 2
"""
# ================== 上下截断点法检验异常值 ==============================
if method == None:
print(f'以 {
column} 列为依据,使用 上下截断点法(iqr) 检测异常值...')
print('=' * 70)
# 四分位点;这里调用函数会存在异常
column_iqr = np.quantile(data[column], 0.75) - np.quantile(data[column], 0.25)
# 1,3 分位数
(q1, q3) = np.quantile(data[column], 0.25), np.quantile(data[column], 0.75)
# 计算上下截断点
upper, lower = (q3 + 1.5 * column_iqr), (q1 - 1.5 * column_iqr)
# 检测异常值
outlier = data[(data[column] <= lower) | (data[column] >= upper)]
print(f'第一分位数: {
q1}, 第三分位数:{
q3}, 四分位极差:{
column_iqr}')
print(f"上截断点:{
upper}, 下截断点:{
lower}")
return outlier, upper, lower
# ===================== Z 分数检验异常值 ==========================
if method == 'z':
""" 以某列为依据,传入数据与希望分段的 z 分数点,返回异常值索引与所在数据框 """
"""
params
data: 完整数据
column: 指定的检测列
z: Z分位数, 默认为2,根据 z分数-正态曲线表,可知取左右两端的 2%,
根据您 z 分数的正负设置。也可以任意更改,知道任意顶端百分比的数据集合
"""
print(f'以 {
column} 列为依据,使用 Z 分数法,z 分位数取 {
z} 来检测异常值...')
print('=' * 70)
# 计算两个 Z 分数的数值点
mean, std = np.mean(data[column]), np.std(data[column])
upper, lower = (mean + z * std), (mean - z * std)
print(f"取 {
z} 个 Z分数:大于 {
upper} 或小于 {
lower} 的即可被视为异常值。")
print('=' * 70)
# 检测异常值
outlier = data[(data[column] <= lower) | (data[column] >= upper)]
return outlier, upper, lower
清洗结果
outlier, upper, lower = outlier_test(data=df, column='price', method='z')
outlier 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2125
2125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









