









文章目录
- 前言
- 1. RB tree深度探索
- 2. set、multiset深度探索
- 3. map、multimap深度探索
- 注:
- 4. hashtable深度探索(上)
- 5. hashtable深度探索(下)
- 6. unordered容器概念
- 7. 算法的形式
- 8. 迭代器的分类(category)
- 9. 迭代器分类(category)对算法的影响
- 10. 算法源代码剖析
- 11. 仿函数和函数对象
- 12. 存在多种Adapter
- 13. Binder2nd
- 14. not1
- 15. bind
- 16. reverse_iterator
- 17. inserter
- 18. ostream iterator
- 19. istream iterator
- 20. 一个万用的hash function
- 21. Tuple用例
- 22. type traits
- 23. type traits实现
- 24. cout
- 25. movable元素对于deque速度效能的影响
- 26. 测试函数
前言
本文为侯捷老师STL课程的一个笔记分享。
课件来源:
https://github.com/19PDP/Bilibili-plus/blob/master/C%2B%2B-STL-HouJie/slide/Slide.pdf
1. RB tree深度探索
这里开始进入关联式容器(Associative Containers),有key和value,查找非常快,甚至元素的安插也非常快,这是很有用的。底层一般是用红黑树或散列表来做。
关联式容器甚至可以想象成一个小型的数据库。用key(关键值)去找value(真正的数据)。
关于红黑树具体原理以及操作不在此课程范围内,可以查看相关资料,这里提供一个参考:
https://zhuanlan.zhihu.com/p/91960960

红黑树提供“遍历”操作以及iterators,按照正常的++ite,就能得到里头所有元素的一个排序状态。
我们不应该使用iterators去改变元素的值。但是编程层面并未禁止这件事。因为我们在红黑树里排序的是元素的key,而map允许元素的data被改变,只有元素的key才是不可被改变的。
这里红黑树提供insert_unique和insert_equal,前者表示放入的key一定是独一无二的,要是里头已经有了一个key,比如说6,那么再放6进去的时候就会放不进去(什么也不发生,也不会报异常之类的)。而用insert_equal是可以放进去的。
下面来观察源码。红黑树内部实现有五个模板参数。这里有一个术语要弄清楚。这里元素本身可以放两个东西:key和data,而这里的value是key和data合起来的东西。而内部所存一个是key一个是data(区别于之前所述的key和value键值对):

所以对应到源码实现的时候要告诉它key是啥value是啥:

这里data本身也可能是其他几个东西的组合。
第三个模板参数是要告诉他,key要怎么从value中拿出来;第四个模板参数就是告诉他应该怎么去比较大小;第五个模板参数就是分配器,有个默认值。
再接着看上图,红黑树内部的数据,图中有三个。分别代表着re_tree的大小、指向红黑树的节点的指针、key的大小比较准则(应该会是一个function object)。
再来思考一个红黑树的内部大小。一个node_count和header都是4字节,加起来8字节,而一个key_compare是一个函数对象,按理没有大小,但是一般编译器实现上,对于大小为0的class会默认给它大小为1,所以这里就是4+4+1为9字节。而要是按照内存对齐,这里就应该是4+4+4=12字节。
同样这里要考虑刻意的“前闭后开”,这里表现出来就是上图的header。
再回到这张图:

一般不会使用红黑树,会使用set或者map之类的包装好的。这里侯老师示范使用红黑树。这里老师第一和第二个参数都传入int,就表示key就是value,value就是key。第三个参数使用GNU C独有的identity,一个仿函数,就是直接返回它自己本身,如上图。第四个传标准库就有的less。
这就是真正拿红黑树来用的做法。只是为了加深理解,实际中一般不会这样用。
那么,接着往下来看用例:



同样这样设计变得复杂化了,但是符合OO里面一个观念:
OO里头为了某个目标会很乐意实现成:在一个class里头,有一个指针或一个单一的东西来表现它的实现手法implementation。这样一种手法叫做handle and body
所以这样的做法,从以前2.9版变成现在4.9版这样复杂,是为了符合handle and body这样的目标。
上图也把set和map画出来了,就是里头有一个Rb_tree(复合)
在STL(上)有一张图,新版(G4.9)红黑树大小从原来的12变成了24字节。从这里可以看到里面还有一个_Rb_tree_color,是一个枚举类型,加起来是3 ptr + 1 color 是24字节。
2. set、multiset深度探索
有了前面红黑树的基础,后面的分析就势如破竹了:

这里set/multiset在设计上禁止通过iterators去改变数据(区分底层的红黑树,那是为了让map使用去改data)。
可以观察其内部实现,内部有一个红黑树:

这里set禁止通过迭代器改内容的关键就是上图的const_iterator
set的所有操作,都是转调用底层的t(红黑树)的操作。
前面的stack和queue也是这样。
那么从这层意义来看,set未尝不是一个container adapter
整个课程使用了G2.9版本来做例子,但是其实其他的平台其他的版本结构都是类似的,所以好好分析了一个平台一个版本的实现后,如果有需要再观看其他平台的实现就会很方便。
下面举一个VC6的例子:

上图的_Kfn其实不就是GNU C的identity吗 😃
下面又回到了之前的测试的例子了(在STL(上)中的测试一节)也可以看到:

3. map、multimap深度探索
在set中,key就是value、value就是key;而在map中value里头包括key和data两部分。
这就是他们的唯一区别。
我们无法使用iterators来改变元素的key,但可以用它来改变元素的data。


如上图,map这里的实现中直接告诉了红黑树第三个参数(之前说了是从value中怎么拿key的方式)select1st,就是说value中的第一个就是key。
而同样从上图我们可以看到,这里把key和data组合成了一个pair,当作value
所以之前我们说set不能改变元素是借由const_iterator来做的,而map不能改key是借由value实现的pair中的模板参数const Key来实现的,区别在这里。
同样,这里的select1st是GNU C独有的,我们再来看看VC中的实现:

同样,在map中_Kfn这一块的写法就是GNU中的select1st
同样是在STL(上)中的测试一节有过的测试multimap:

这里比如multimap<long, string>,心中要知道,红黑树实现是把他们包装成一个pair,然后当作节点放入红黑树中的。
这里中括号要传回来与这个key相关的data,如果这个key不存在,中括号就会创建这个元素带着这个key放入map中,所以这是map独特的operator []:

这里lower_bound是二分查找的一种版本,标准库提供的一个算法。
而在上面实现中还分为了2011之前的版本和2011之后的版本实现。
同样提供的一个例子,通过中括号来放元素(通过之前分析我们知道,找不到key就会加入新的元素进去):

而显然由于中括号里头先做了lower_bound再做了insert,所以当然是直接放元素比较快。
注:
这里4、5、6几乎都在“C++新标准-C++11/14(第二讲:标准库部分)”中讲过了,这里有的地方仅放PPT供参考。
4. hashtable深度探索(上)

如上图所述:空间不足时,就是除以空间个数看放在哪。全世界在设计hashtable的时候都是这样的做法。那么就会有碰撞(哈希冲突)。
然后就会有科学家发明算法,比如之前数据结构学的各种诸如:线性探查法、线性补偿探测法、平方取中法、开放定址法巴拉巴拉。
但是最终大家放弃了这些方法,改用现在称呼为拉链法的方法。即如果发生碰撞就让他们变成一个链表串在一起。

那么放到什么情况会被判定为某个篮子的链表过长呢?这里没有任何数学,纯粹是人的经验法则,就是如果元素个数>=篮子个数,就被认为危险,就把篮子扩充为两倍。

从上图,这里我们可以观察源码,模板参数中第一个value,第二个key,第三个HashFcn(哈希函数,可以是一个仿函数函数对象),用来算出hash code,第四个模板参数就是从这一包东西中取出key的方式(函数对象),有点像红黑树的那个参数了,第五个模板参数EqualKey,同样作为一个函数对象告诉它怎样比大小,最后一个分配器。
同样我们观察它的内部数据,首先有三个函数对象,然后有一个篮子vector(图中的buckets),还有一个变量登记有多少元素。所以一个hashtable的大小就是:三个函数对象,之前提到了原本大小应该是0但是编译器会给1,共3个字节,buckets本身是vector三个指针12个字节,num_elements是一个size_type是四个字节,所以一共 1 + 1 + 1 + 12 + 4 = 19,字节对齐共20个字节。所以每个hashtable的大小是20个字节。
而node的设计,除了东西本身之外还由于单向链表的实现所以会挂着一个指针指向下一个节点。
同时迭代器要是走到尽头了应该能够回到“控制中心”以达到下一个节点(有点像之前STL上中分析的deque)。所以迭代器应该有能力回到篮子vector里头去走向下一个篮子。所以从上图观察设计可以看到其中有两个指针node* 和 hashtable*
5. hashtable深度探索(下)
下图是一个直接使用hashtable的实例:




如果要自己写一个hash-function,可以想象应该类似下图这样写:

所谓modulus(模数,mod)就是除后得余数,所以hash code算出来落在哪个篮子上,所有的hash table几乎都是这样直接取模去做的,公认的一件事。下图浅蓝色的部分其实也就是去计算最终落在哪个篮子里,最后可以看到最终通通会去取余数:

6. unordered容器概念
2.0之后把hash改成了unordered:

其余的介绍就是看STL(上)的测试了,没别的说的了。
所以也能看到unordered容器与之前的set、map等容器区别就在于,底部支撑的是红黑树还是hash table了。
7. 算法的形式



从语言的层面来讲,容器是一个类模板,而算法则是一个函数模板。
如上图右下角,标准库里所有的算法类型都是这两个版本。比如说sort算法可以传递第三个参数,即排序的准则。而这第三个参数其实是一个Functor。
所以这里算法其实是看不到容器的,它只能看到自己的迭代器。所以算法会想要提问去问迭代器一些问题,然后迭代器进行回答来提供这些算法所需要的信息。
如果算法发出问题而迭代器无法回答,那么编译就会报错。
8. 迭代器的分类(category)

这里我们观察到迭代器一共有五种(category):
random_access_iterator_tag
bidirectional_iterator_tag
forward_iterator_tag
input_iterator_tag
output_tag
其中的继承关系如上图。
每个容器对应迭代器也来分析总结一下:
- Array、Vector、Deque:都是连续空间(这里包括deque的假象),所以都是random_access_iterator_tag。
- List:不连续空间,但是是双向链表,所以是bidirectional_iterator_tag
- Forward-List:既然是单向链表,所以应该是forward_iterator_tag
- Set、Map、Multiset、Multimap:红黑树的底部支撑,通过我们之前的分析,我们知道红黑树都应该是双向的,所以是bidirectional_iterator_tag
- Unordered Set/Multiset、Unordered Map/Multimap:hashtable的底部支撑,通过之前的分析我们知道,要看每个篮子的链表是双向还是单向链表,所以应该是forward_iterator_tag(对应hashtable内部实现是单向的链表)或是bidirectional_iterator_tag(对应hashtable内部实现是双向的链表)。而按照之前分析的版本实现来看,G2.9是单向链表实现,所以G2.9版本就应该对应着forward_iterator_tag
下图是测试打印出各种容器的迭代器类型:

这里又讲到了这种C++语法,就是typename后加小括号表临时对象。
这里侯老师的做法就是把拿到的迭代器丢到萃取机去问它的iterator_category。然后继续往上丢,通过函数重载去实现打印。
而上图的实现,还有istream_iterator对应着input_iterator,ostream_iterator对应着output_iterator。
下图把放进来的iterator放到typeid去,typeid可以形容成C++提供的一个操作符,放入后得到一个对象object,然后使用其中的name。得到的结果如下图右侧:

这里可以参看上图的一些注解。output取决于library的实现,传回来的版本就取决于编译器的一些版本。GNU不一样VC不一样之类的。
这里再来看一下特殊的istream_iterator和ostream_iterator:


可以看到源码实现中都指定了他们的category
而这里还有一些特殊的形式,即父类什么都没有,只有一些typedef,而子类去继承父类,相当于子类也有了这些typedef。这样的继承为的就是把typedef继承过来。
9. 迭代器分类(category)对算法的影响
下图以函数distance举例,表示两个迭代器之间的距离:

可以从上图看到,先通过萃取机拿到iterator的category,然后根据category创建临时对象,通过重载根据第三参数从而调用相对应的函数。而函数返回值的返回类型同样是根据萃取机拿到迭代器的difference_type
很显然,上图的第二版本一减就结束了,而第一个版本则要一步一步判断,效率相差很大。
接着拿advance函数举例:

同样最后根据迭代器category分成了三个版本。
接着来看copy函数:

需要三个参数:来源端的头和尾、目的端的头。然后copy过去。
这里可以看到实现较为复杂,有很多次对迭代器的检查。这里最后的trivial表示重不重要。
还有例子destroy供参考:

destroy按理会调用析构函数,这里会判断这个析构函数是否是重要的。
destroy的源码:


这里命名成如下图这样的形式,但其实它只是一个模板参数,所以只是一个暗示:

10. 算法源代码剖析
之前已经了解了迭代器的分类以及type traits对算法的影响,下面再来看看一些例子:

上图中q就是quick,b就是binary二分查找法。可以看到C和C++参数上的区别。
第一个C++算法为accumulate:

第一版本就是一个初值加上每个元素的值。
第二个版本则是初值与每个元素做了一个binary_op的操作。
上图右侧的minus()等都是一个functor
可以看到,对于第四个参数binary_op,只需要小括号()能作用到其上即可。()叫做function call operator,函数作用符。
所以就把这样的浅蓝色的(如上图的binary_op,即可被小括号作用在其上)叫做callable entity。可被调用的东西。
这里示范了两个,一个是一般的函数myfunc,或者是函数对象(function object),即一个类或结构体重载了小括号。
通常算法有两个版本,第二个版本允许我们加上一个准则。
第二个例子for_each:

这里for_each函数每次调用。
C++的range-based for statement非常好用。右手边可以直接放一个容器,像上图其实也是一个容器(initializer_list)
第三个例子:

replace就是把一段范围的旧值该换为新值。写着很简单。
replace_if就是加了一个条件。注意这里的ForwardIterator等都只是模板参数,但是GNU C的源码有暗示,这样阅读起来非常好。
replace_copy,等于旧值的用新值放入新的区间中去,否则不变。
第四个:
以下这几个侯老师整理了容器中带不带这些同名函数:

count就是走一遍看想不想等,相等计数就+1.
count_if就是看是否符合条件,符合计数就+1.
这里左边这种属于泛化的,右边的则是对自己这样的容器有一个比较快的或别的做法。
因此容器中有自己的那个版本那么一般我们就用自己的这个专属版本。
这里这八个特别的地方就是关联式容器,都自带着一个count函数。我们可以想象因为他们是关联式容器,查找会比较快,不需要再像全局的count这样一个一个去遍历。
我们还可以在接下来的find与sort中看到这样的现象:
第五个:

全局的find就是一个循序查找的方式。并没有什么特殊的。最坏的情况要全部走一遍。
find_if就是找的时候要符合一个条件。
同样,关联式容器自己带有一个find。
第六个:

这里仅仅示范sort的用法。实现比较复杂。
这里上图的rbegin和rend的r代表着reverse,就是逆向的begin和end。
这里这八个关联式容器已经形成sorted状态了。而list和forward_list则是自带着自己的版本。因为全局的sort要求迭代器是random_access_iterator,需要可以跳,而list和forward_list则不行。
下图简单说明了一下rbegin和rend:

这里rbegin和rend要拿的其实是原来的end和begin,但是需要用adapter改变一下。
使用必须在排序的状态下:

上图右下角说明了lower_bound和upper_bound。上图的lower_bound展示的意思是,可以把20安插进去的最低点,而upper_bound就是可以把20安插进去的最高点。当然前提需要已经排好序,源码其实就是一个二分搜寻。
11. 仿函数和函数对象
functor是最简单的,也是最有可能自己写的六大部件之一。其只为算法服务:

首先其必须重载小括号。上图就是标准库提供的三大类的functor:算术类、逻辑运算类、相对关系类(即比大小)。
接着往下看:

GNU C++独有着非标准的一些仿函数,比如之前用过的identity、select1st等。
而可以看到在4.9版本的名字发生了变化。
下图再一次拿sort函数举例:

可以看到,前面四个排序都是由小到大排序,最后一个传入greater就是由大到小排序。
没有继承就没有融入STL,STL中有些功能就可能不适用。再往下看:
再次回到这张图:

这次观察黄色的部分,可以看到他们都集成了一个仿函数。而没有继承就没有融入STL,比如之前sort的PPT中。

binary_function就是两个操作数。而unary_function就是只有一个操作数,比如对一个东西取它的否定。
从源码中我们可以看到,他们其实就是把模板参数换了个名字而已。
这里再一次来谈我们之前说的大小的概念:这一个类中没有data,大小理应是0,但是实际上编译器会给1字节(之前讲过),但是当我们是继承关系的时候它作为父类它的大小就仍然是0字节。
STL规定每个adaptable function都应该挑一个来继承。
比如这里的less有两个操作数,就继承了binary_function。
这里adaptable就是一个能不能被改造的意思,在后面的adapter会接着说。
总结:
仿函数就是一个class里头重载了小括号(),这样的一个class所创建出来的对象就叫做函数对象或仿函数。为什么叫函数对象呢?因为这个对象是一个对象但是像一个函数,所以叫函数对象。
而很多地方为了搭配算法我们就会去写出仿函数来。但是要注意的是,如果创造的时候没有继承,那么就放弃了未来可以被改造的机会。亦即如果想要自己写的functor融合入整个STL体系,那么就需要选择适当的仿函数(如上图的unary_function与binary_function等)之一去继承。
12. 存在多种Adapter
现在来进入最后一个部件,adapter,可以叫做适配器,或者叫做改造器之类的(其实也有设计模式adapter):

adapter其实只是一个小工程的变化而已。adapter只是把一个既有的东西稍微改一下而已。
上图可以看到,adapter出现在了三个地方,由它想要改造的东西去决定叫什么。做法有个性也有共性。
关键是,要改造某一个东西,A改造了B,那么A就代表了B,那么之后就只需要使用A,而实际功能的实现则仍然是交由B去实现。
那么A要使用B的功能,之前我们也提到了,一个是继承的方式,一个是内含(复合)的方式。
那么在这里的adapter中,我们统统不用继承的方式,而都是用内含的方式。
第一种adapter,容器的adapter:

可以看到,其内含了一个容器deque。这就是容器的适配器。
13. Binder2nd
接下来讲函数适配器。其比较常被使用。
之前第一讲写过这样一个程序,比如下图的右上角:

这里我想要看小于40的元素个数,可以专门写一个小于40的function传进来,而要是再要一个大于100,或小于200,就又需要写针对这样的特例的function。
那么现在标准库就给了这样的adapter:bind2nd,就相当于把第二个参数绑定了一下。
这里很有意思,less实际上是一个object,还没有调用,所以此时并未传入参数,这里bind2nd里面就会创建binder2nd,其为真正的主角。有很多手法都是有一个class主体,然后再去给一个辅助函数来使用。那么这里我们再来观察主体binder2nd:
这里adapter修饰function那么它之后也要去形成function的样子,所以这里要去重载小括号()。以上图右上角的例子举例,这里的成员op其实就是红色的less,而value实际上是40,所以实际上实现中并不是什么绑定,只是先把40记起来,等到后面调用的时候直接传参(这里的op(x, value),非常巧妙!
而这里最后用辅助函数bind2nd,typename加小括号,创建临时对象。创建对象的时候指定模板参数。
到这里我们已经知道其大致实现了,接下来再来看看一些细节:
首先是上图灰色部分。adapter首先去问第二实参是什么类型,然后这里会看是否可以转换,比如右上角例子中的40去判断是不是less中模板的int型。如果不能转换就会编译出错。可以看到这里的value的type不能随便定义,必须用问的方式来获得。
从上图灰色的部分可以看到,很多地方的type都是靠问的,会问三个问题:第一个实参是什么type,第二个实参是什么type,这两个比完之后又是什么type?
所以一个函数对象必须能够回答这三个问题才能和这一个adapter:bind2nd搭配完美。这样上图这些灰色的部分才会有意义。如果能够回答这三个问题,我们就叫这个function叫做是adaptable的。
于是回到下图,我们瞬间明白了这三个typedef的作用,其实就是去回答那些问题的:

回到下图,再来说一下typename:

这里的typename其实是为了让编译器通过的作用。比如:
typedef typename Operation::second_argument_type arg2_type;
这一句(在上图的左上角)。编译器编到这里的时候其实还不知道作为模板参数的Operation是什么,也就无法得知Operation::second_argument_type是否是正确的用法。所以正常来讲编译器编到这里会编不过。所以这里typename用以是这里,就是让编译器编到这里可以编译通过。
这里还有一个细节,就是这个adapter作用完后还可能被别的adapter使用,于是这里的binder2nd还继承了unary_function。这样的写法就非常的严谨。
下图列了后续版本的一些变化,其实在新版本中bind1st、bind2nd都过时了,统统用bind来取代:

14. not1
有了前面的基础,后面的分析也差不多:

15. bind
之前分析过bind2nd和binder2nd,也说了新版本都被bind所取代:

下图展示了bind的一个用法(在cplusplus.com网站中):

可以看到,bind可以绑定四个东西(上图左下角)。绑定functions:functions、function objects;绑定members:member functions、data members
这里的 _1 和占位符placeholder有关,从示例中我们可以看到,我们用 _1 占位符来代表第一参数,然后传给bind,之后调用的时候再真正传入。
同样,这里我们还看到了 _1 和 _2 的区别,非常有趣。
比如下图这个例子,10为第一参数,传给bind的_1,而2为第二参数,传给bind的_2,结果就不是5而是0.2了。
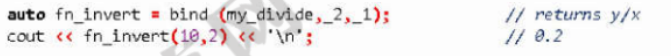
当然,bind还能指定一个模板参数,表示返回类型。而前面没有指定,return type就是所绑的那个东西(my_divide)。
再来看绑定members的例子:
可以看到,member function都有隐藏的this,于是这里我们就用了_1占位符,之后来传this指针(这里的ten_two)。
然后还可以绑定data members,很有意思。
这里示例还有一个cbegin和cend,这里的c表示const,即传回的迭代器是const的。
16. reverse_iterator
现在开始谈iterator adapter:
第一种,reverse_iterator:

首先是之前说的那5个typedef(迭代器设计原则),和原来的iterator一致即可。
重要的是表现出取值的动作。对逆向取值就是对正向退一位取值。可以观看上图的源码(主要是操作符重载)。
17. inserter
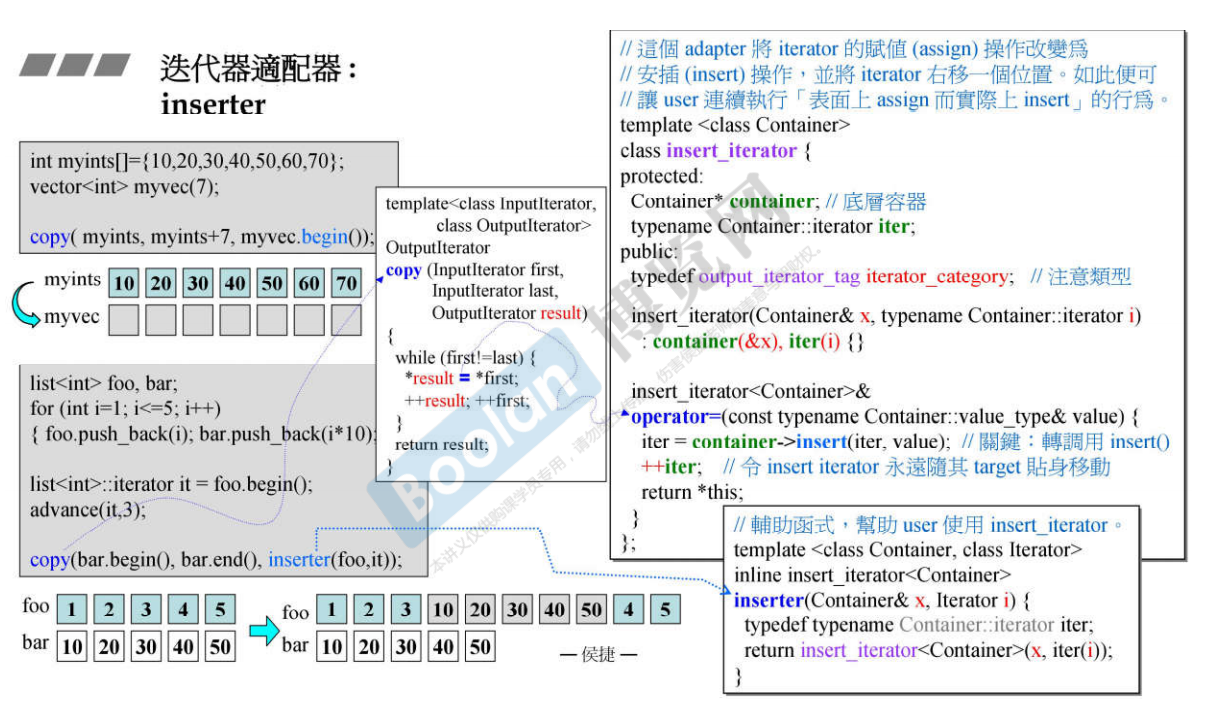
可以看到copy是直接拷贝赋值,所以要事先预留好足够的空间大小。
而inserter就与直接copy区分出来。这里实现中用了advance基础函数,因为链表是不能直接+3的。
可从上面的示意图看到,要是用意是硬插入这五个元素,就要用到inserter这样一种迭代器适配器。即把目的端迭代器it改为插入型的迭代器动作。而实现的关键又是使用了操作符重载。
我们来看它的实现:在copy中赋值是用赋值号=去操作的:*result = *first; 那么在inserter这个适配器中我们就重载了赋值号=,这样在进行copy的赋值操作的时候就会跑到inserter内的操作符重载中去调用。而在操作符重载中观看源码就可以发现关键是直接转调用了insert()函数。
18. ostream iterator
接下来谈ostream iterator与istraem iterator。而这里ostream iterator与istraem iterator都不属于之前讲的那三种适配器,于是这里侯老师叫做X适配器。

这里把迭代器绑定到一个装置上,上图中示例绑定到cout上,这太奇怪了!
这里作用到copy中,希望每一个动作都把元素跑到cout上。delimiter是分隔字号的意思。
cout到底是什么?其实cout是一个object,是一个对象。所以cout它可以取地址。
那么在这样一个适配器的关键就是在赋值号重载的时候把value丢到了cout中去(*out_stream << value)。那么丢出去后如果delim存在,就接着丢元素。以此类推把元素全部走完。
所以其实这里也可以叫做ostream的适配器,因为是来改造ostream。
19. istream iterator

istream_iterator更奇妙,绑定的是cin
上图的eos是没有参数的,代表一个标兵一个符号。而iit带有参数cin,cin在istream_iterator实现中被记在in_stream中,然后构造函数的时候就会马上++,++则调用内部的操作符重载部分。也就是说,++就会去读内容。
接下来的例子又复杂一点点,但也更有趣:

我们又回到了之前讲的copy函数。这里同样是创建两个:一个eos作为标兵,一个绑定到cin上。
同样同一个copy,在这里的istream_iterator中重载了*、++等操作符。
所以同样一个copy,在不同的对象上竟有不同的使用,非常有趣。


最后我们也可以看到,只是写错一行代码,但由于模板一层层往下,返回的报错居然这么多!
使用一个东西,却不明白它的道理,不高明!
至今已经明白了标准库的道理。
20. 一个万用的hash function
终于把STL在一二三讲解决了,现在进入第四讲:


所谓hash function,希望产生的hash code越乱越好,避免重复。
从上图可以看到两个型式上的一些区别。
我们再往下看,如果有一个类内有好几个成员,且可能是不同的参数类型,一个“天真”的想法就是分别算出他们的hash code然后相加,但是这样做会造成较多的hash碰撞(冲突)。

如上图,简单地这样相加会造成碰撞较多。虽然可以运作,但是太天真了,不好。
接下来探讨上图1、2、3、4部分的实现。
首先可以看到1、2、3有三个同名的hash_val,1中为可变模板参数,而2、3的参数则与1不同。
可以观察上面的实现,每次拿到一包参数,先在1中声明一个种子seed,然后调用2,2再调用4combine,然后通过哈希函数去设定这个种子seed的值。这个改完之后的种子值就是hash code。也就是从…中一次一次去取出元素来设定种子,知道最后只剩一个参数的时候落到了3这个动作。
可以看到,可变模板参数variadic templates为我们很方便地做到了拆解的事情。
可以看到seed每次都是 ^= 操作,这样就把传入的那一包参数combine计算成了一个hash code。
那么上图算hash code的那个9e3779b9到底是怎么来的呢?拜万能的Google所赐查到如下页面:



之前提到了形式1和2,其实还有形式3:


21. Tuple用例

tuple:一堆东西的组合。这是tr1才加进来的。
注:C++ Technical Report 1 (TR1)是ISO/IEC TR 19768, C++ Library Extensions(函式库扩充)的一般名称。TR1是一份文件,内容提出了对C++标准函式库的追加项目。
现在是到了C++2.0(C++11之后),涵盖了过去的TR1,变成了标准的一部分。
上图首先测试了各个数据的大小。string里头大小就是一个指针,4字节。double8字节。而如果复数指定的是double的话,实部虚部加起来就是16个字节。
那么此时测试tuple,tuple<string, int, int, complex< double > > t,打印出来居然是32字节(想象中加起来4+4+4+16=28)。这个暂时无法理解还有待查验。不过我想应当是由于字节对齐要修正到double8字节的倍数,所以是32字节。
接着示范了tuple的一个给初值。tuple<int, float, string> t1(41, 6.3, “nico”);
和拿出元素的方法: get<0>(t1) 拿出t1的第一个成员。
也可以通过make_tuple,通过编译器的实参推导得到一个tuple:auto t2 = make_tuple(22, 44, “stacy”);
这里还有:t1和t2可以比较大小、可以赋值、可以cout输出(因为tuple重载了<<)。
tie绑定绑住的意思。这里就是t3要绑住这三个东西:tie(i1, f1, s1) = t3; 即把t3的这三个成分拿出来附着到这些变量去(assign values)。
最后示范了tuple_size和tuple_element。后者则可以展示tuple的第几个元素的type。
那么这么神奇的tuple是怎么做的呢?往下看:

又出现了!可变模板参数。
而这样的语法(variadic templates)一定会有一个主体和一个结束条件。上图的结束条件是由G4.8版本简化的,不过足够我们理解tuple了。
设计上一开始就放入了head和tail…,头head和尾tail都是任意类型,看你的指定。其实这些在C++新标准中都有过分析了。这里其实就是继承了tuple<Tail…>递归地去实现。
这里tuple还开放了head和tail两个函数。
22. type traits
在G2.9版做出的type traits的写法如下:

做出了6个typedef。第一个typedef是实现上的关系,不用管;剩下五个问题要回答,问题分别是:你的默认构造函数是不重要的吗?(has_trivial_default_constructor,这里的trivial英文中就是微不足道的意思),你的拷贝构造是不重要的吗?拷贝赋值?析构函数?可以看到这些默认的回答都是false。如:
typedef __false_type has_trivial_default_constructor;
因此所有的这些东西都是重要的。
这里的POD就是“很平淡的旧格式”,那么什么是旧格式呢?其实就是C中的struct。就是里头没有function只有data。
而在特化的版本中,例如__type_traits< int >,这些都被设定为不重要的。毕竟一个int型哪来的拷贝构造啥的嘛!
因此依葫芦画瓢,我们也可以自己去写出这样的一个特化版本。用真或假去回答这五个问题。
因此一个设计者可以写出这五个问题的答案,然后算法再去询问这些问题使用萃取机得到答案。
这就是type traits。
当然这样实用性不高,毕竟谁知道一定要去定义这五个typedef呢!
而在C++11之后,一些type traits如下:




一个类要不要写虚析构函数?以我们对OO的理解,一个class自己被当作base class的时候,只要带着指针应该就要写virtual destructor。那么字符串应该不会被拿来当作父类,因此在设计上destructor不是virtual的。
那么如上图的测试程序,右上角就可以通过迭代器去问是不是有虚析构函数。


这里随便设计出一个类,就可以丢到type traits中去看很多特性,实在是太厉害了。


根据我们对复数的理解,它只有实部虚部,因此析构函数不需要定义,直接默认的就好。萃取出来的结果也是如此,__has_trivial_destructor确实是1,即代表着destructor是不重要的。

23. type traits实现
之前看着感觉type traits非常匪夷所思。拿一个自己定义的类就可以丢进去萃取。下面来看看实现:
例子1,is_void:

这里又是之前讲过的手法:在remove_const的实现中又用到了偏特化。比如这里的remove_const<_Tp const>,它的typedef就仍然是_Tp。
volatile同样,typedef中把关键词volatile或者const拿掉。
所以任何type放进去回应就是去掉那些关键字的版本。
于是回过来看实现:这里的is_void先用remove_cv把const和volatile关键词拿掉,拿的方法在上图左边,拿掉后再进入上图的__is_void_helper,其实现都是用一个泛化和一个偏特化去实现的。这样就实现了is_void的这样一个type traits。
例子2,is_integral:

同样,先用remove_cv把const和volatile关键词拿掉,之后调用helper去进行实现。
例子3,is_class,is_union,is_pod:


24. cout
接下来介绍一下cout:

cout是一个类还是一个对象?cout不能拿类来用,所以它一定是一个对象object。
这个extern是说这个变量可以被外界使用,即文件之外的也能看到它。
于是可以看到,必须是在上图出现的这些基本类型,才能被cout接受(当然这是G2.9版本)。
那么自己要写一个类型去用cout输出,就需要自己操作符重载<<,而不是用cout的操作符重载了。实现如下:
















 528
528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









