







运行环境
我使用的VSCODE运行的,装了node.js:
https://www.runoob.com/nodejs/nodejs-install-setup.html
装了这些插件:
然后就可以在html文件运行js(chrome)或者直接运行js(node)

第一章:精华
本书的目的就是要揭示JavaScript的精华。本书很少涉及DOM(文档对象模型)。
辅助教程:https://www.runoob.com/js/js-tutorial.html
第二章:语法
语法图(Syntax diagrams)
推荐:https://www.jianshu.com/p/aa8d3e914ab3
语法图(Syntax diagrams )又叫铁路图(railroad diagrams)是描述形式文法的一种方式。它是巴科斯范式或扩展巴科斯范式的图形化表示。
铁路图(railroad diagram)规则:
1.从左边界开始沿着轨道去到右边界。
2.沿途,你将在圆框中遇到的是字面量,在方块中遇到的是规则或者描述。
3.任何沿着轨道能走通的序列都是合法的。
4.任何不能沿着轨道走通的序列都是非法的。
5.每个末端只有一个竖条的铁路图允许在任何一对标记中间插入空白。而在末端有两个竖条的铁路图是不允许的。
每个图都有一个起始点和一个终点。这个图通过穿过其他的非终结符和终结符描绘了这些两点之间的可能路径。终结符用圆形区域表示,同时非终结符用方形区域表示。
数字(Numbers)
JavaScript 只有一个数字类型。它在内部被表示为 64 位的浮点数,和 Java 的 double 数字类
型一样。它没有分离出整数类型,所以1和1.0 的值相同。100与1e2相同。
NaN 是一个数值,它表示一个不能产生正常结果的运算结果。 NaN 不等千任何值,包括它自
已。你可以用函数 isNaN(number) 检测 NaN; Infinity 则表示所有大于 1.79769313486231570e+308 的值。
同时, JavaScript 有一个对象 Math, 它包含一套作用于数字的方法。例如,可以用 Math.floor(number) 方法把一个数字转换成一个整数。
字符串(Strings)
字符串字面最可以被包在一对单引号或双引号中,它可能包含0个或多个字符。JS中的所有字符都是 16 位的。
JavaScript 没有字符类型。要表示一个字符,只需创建仅包含一个字符的字符串即可。
var hbh = "\u0041";
alert(hbh.length);
alert(hbh);
如上,字符串自带length属性,\u为unicode编码,后跟4位16进制数,所以打印出来为:1、A
若改为:var hbh = "\u0041" + '\u0042',注意单引号双引号无区别,打印结果为2、AB
字符串是不可变的。一且字符串被创建,就永远无法改变它。两个包含着完全相同的字符且字符顺序也相同的字符串被认为是相同的字符串。
语句(Statements)
一个编译单元包含一组可执行的语句。在 Web 浏览器中,每个<script>标签提供一个被编译且立即执行的编译单元。因为缺少链接器, JavaScript 把它们一起抛到一个公共的全局名字空间中。
当 var 语句被用在函数内部时,它定义的是这个函数的私有变量。
switch、while、for 和 do 语句允许有一个可选的前置标签 (label) ,它配合 break 语句来使用。
代码块是包在一对花括号中的一组语句。不像许多其他语言, JavaScript 中的代码块不会创
建新的作用域,因此变量应该被定义在函数的头部,而不是在代码块中。
false、null、undefined、空字符串’ '、数字0、数字NaN 都被当作假。其他所有的值都被当做真,包括 true 、字符串 “false" ,以及所有的对象。
switch、while、for 和 do 这些都和C差不多,for有一点点区别,它有两种形式,一种和C一样,一种如下:
var person={fname:"Bill",lname:"Gates",age:56};
var txt = ''
for (x in person) // x 为属性名
{
txt = txt + person[x];
}
alert(txt);
通常你需要检测 object.hasOwnProper y(variable) 来确定这个属性名是该对象的成员,还是来自于原型链:
for (x in person)
{
if (person.hasOwnProperty(x))
{
txt = txt + person[x];
}
}
一个 expression 语句可以给一个或多个变扯或成员赋值,或者调用一个方法,或者从对象中删除一个属性。运算符=被用千赋值,不要把它和恒等运算符===混淆起来。运算符+=可以用于加法运算或连接字符串。
表达式(Expressions)
最简单的表达式是字面最值(比如字符串或数字)、变量、内置的值 (true false null undefined NaN Infinity) 、以 new 开头的调用表达式、以 delete 开头的属性提取表达式、包在圆括号中的表达式、以一个前置运算符作为前导的表达式,或者表达式后面跟着:
- 一个中置运算符与另一个表达式
- 三元运算符 ?后面跟着另一个表达式,然后接一个 :,再然后接第 3 个表达式
- 一个函数调用;
- 一个属性提取表达式。

typeof 运算符产生的值有’number’ 、' string’ 、' boolean’ 、' undefined’ 、' function’ 和’object’ 。如果运算数是一个数组或null, 那么结果是’object’ ,这其实是不对的。
在JavaScript 语言里”%“不是通常数学意义上的模运算,而实际上是“求余”运算。两个运算数都为正数时,求模运算和求余运算的值相同;两个运算数中存在负数时,求模运算和求余运算的值则不相同。
第三章:对象
JavaScript 的简单数据类型包括数字、字符串、布尔值(true 和false) 、null 值和undefined值。其他所有的值都是对象。数字、字符串和布尔值"貌似“对象,因为它们拥有方法,但它们是不可变的.JavaScript 中的对象是可变的键控集合{keyed collections) 。在JavaScript中,数组是对象,函数是对象,正则表达式是对象,当然,对象自然也是对象。
对象字面量
var empty_object = {};
var stooge = {
"first-name": "Jerome", // 由于有-,不是一个合法的标识符,所以必须用引号括起来
"last-name": "Howard"
};
对象是可嵌套的:
var flight = {
airline: "Oceanic",
number: 815,
departure: {
IATA: "SYD",
time: "2004-09-22 14:55",
city: "Sydney"
},
arrival: {
IATA: "LAX",
time: "2004-09-23 10:42",
city: "Los Angeles"
}
};
检索
以刚刚的例子:
stooge["first-name"] // "Jerome"
flight.departure.IATA // "SYD"
// 如果你尝试检索一个井不存在的成员属性的值,将返回 undefined
stooge["middle-name"] // undefined
flight.status // undefined
stooge["FIRST-NAME"] // undefined
// || 运算符可以用来填充默认值:
var middle = stooge["middle-name"] || "(none)";
var status = flight.status || "unknown";
// 尝试从 undefined 的成员属性中取值将会导致 TypeError 异常。这时可以通过&&运算符来避免错误。
flight.equipment // undefined
flight.equipment.model // throw "TypeError"
flight.equipment && flight.equipment.model // undefined
更新
比较特别的是,如果对象之前没有拥有那个属性名,那么该属性就被扩充到对象中:
stooge['middle-name'] = 'Lester';
stooge.nickname = 'Curly';
flight.equipment = {
model: 'Boeing 777'
};
flight.status = 'overdue';
引用
对象通过引用来传递。它们永远不会被复制:
var x = stooge;
x.nickname ='Curly';
var nick= stooge.nickname;
// 因为 stooge 是指向同一个对象的引用,所以 nick 'Curly'
var a={}, b = {}, c = {};
// a、b、c每个都引用一个不同的空对象。
a= b = c = {};
// 都引用同一个空对象。
原型
Prototype
每个对象都连接到一个原型对象,井且它可以从中继承属性。所有通过对象字面量创建的对象都连接到 Object.prototype, 它是 JavaScript 中的标配对象。
当你创建一个新对象时,你可以选择某个对象作为它的原型。
我们将给 Object 增加一个 create 方法。这个方法创建一个使用原对象作为其原型的新对象:
if (typeof Object.create !== 'function') {
Object.create = function (o) {
var F = function () {};
F.prototype = o;
return new F();
};
}
var another_stooge = Object.create(stooge);
原型连接在更新时是不起作用的。当我们对某个对象做出改变时,不会触及该对象的原型:
another_stooge['first-name'] = 'Harry';
another_stooge['middle-name'] = 'Moses';
another_stooge.nickname = 'Moe';
原型连接只有在检索值的时候才被用到。如果我们尝试去获取对象的某个属性值,但该对象没有此属性名,那么 JavaScript 会试着从原型对象中获取属性值。如果那个原型对象也没有该属性,那么再从它的原型中寻找,依此类推,直到该过程最后到达终点 Object.prototype 。如果想要的属性完全不存在于原型链中,那么结果就是 undefined 值。这个过程称为委托。
原型关系是一种动态的关系。如果我们添加一个新的属性到原型中,该属性会立即对所有
基于该原型创建的对象可见:
stooge.profession = 'actor';
another_stooge.profession // 'actor'
反射
任意原型链中的任何属性都会产生值:
typeof flight.toString // 'function'
typeof flight.constructor // 'function'
有两种方法去处理掉这些不需要的属性。第一个是让你的程序做检查井丢弃值为函数的属
性。另一个方法是使用 hasOwnProperty 方法,如果对象拥有独有的属性,它将返回 true,hasOwnProperty 方法不会检查原型链。
flight.hasOwnProperty('number') // true
flight.hasOwnProperty('constructor') // false
枚举
通过typeof过滤:
var name;
for (name in another_stooge) {
if (typeof another_stooge[name] !== 'function') {
document.writeln(name + ': ' + another_stooge[name]);
}
}
但是属性名出现的顺序是不确定的,因此要对任何可能出现的顺序有所准备。如果你想要确保属性以特定的顺序出现,最好的办法就是完全避免使用 for in 语句,而是创建一个数组,在其中以正确的顺序包含属性名:
var i;
var properties = [
'first-name',
'middle-name',
'last-name',
'profession'
];
for (i = 0; i < properties.length; i += 1) {
document.writeln(properties[i] + ': ' +
another_stooge[properties[i]]);
}
删除
// 删除 another_stooge nickname 属性,从而暴露出原型的 nickname 属性。
delete another_stooge.nickname;
减少全局变量污染
由于JS没有链接器,所有的编译单元都载入一个公共全局对象中。我们可以为你的应用只创建一个唯一的全局变量:
var MYAPP = {} ;
该变量此时变成了你的应用的容器:
MYAPP.stooge = {
"first-name": "Joe",
"last-name": "Howard"
};
MYAPP.flight = {
airline: "Oceanic",
number: 815,
departure: {
IATA: "SYD",
time: "2004-09-22 14:55",
city: "Sydney"
},
arrival: {
IATA: "LAX",
time: "2004-09-23 10:42",
city: "Los Angeles"
}
};
第四章:函数
函数包含一组语句,它们是 JavaScript 的基础模块单元,用于代码复用、信息隐藏和组合调用。
函数对象
JavaScript 中的函数就是对象。
对象是“名/值”对的集合井拥有一个连到原型对象的隐藏连接。对象字面量产生的对象连接到 Object.prototype 。函数对象连接到 Function.prototype (该原型对象本身连接到 Object.prototype )。
每个函数数在创建时会附加两个隐藏属性:函数的上下文和实现函数行为的代码(JavaScript 创建一个函数对象时,会给该对象设置一个“调用“属性。当 JavaScript用一个函数时,可理解为调用此函数的“调用“属性)。除了调用属性,还有 prototype 属性。它的值是一个拥有 constructor 属性且值即为该函数的对象。
函数字面量
var add = function (a, b) {
return a + b;
};
函数字面量包括4个部分:
- 保留字function
- 函数名(可省略,可以用来实现递归,上面的例子为匿名函数)
- 参数
- 函数的主体,即花括号中间的一组语句
调用一个函数会暂停当前函数的执行,传递控制权和参数给新函数。除了声明时定义的形式参数,每个函数还接收两个附加的参数: this 和 arguments 。
当一个函数对象被创建时, Function 构造器产生的函数对象会运行类似这样的一些代码:
this.prototype = {constructor: this};
而对于 arguments ,举例如下:
function add(a, b, c)
{
console.log(arguments);
var sum = a + b + c;
console.log(sum);
}
add(1, 2, 3, 4);
add(1, 2);
打印结果:
[Arguments] { '0': 1, '1': 2, '2': 3, '3': 4 }
6
NaN
因为这里我们只用到了arguments的前三个变量,没毛病。这也和C风格完全不同。
而如果实际参数值过少,则缺失的值会被替换为undefined。对参数值不会进行类型检查:任何类型的值都可以被传递给任何参数。
因为语言的一个设计错误, arguments 井不是一个真正的数组。它只是一个“类似数组 (array-like)" 的对象。 arguments 拥有一个 length 属性,但它没有任何数组的方法。
调用
参数 this 在面向对象编程中非常重要,它的值取决于调用的模式。在 JavaScript 中一共有 种调用模式:方法调用模式、函数调用模式、构造器调用模式和 apply 调用模式。这些模式在如何初始化关键参数 this 上存在差异。
方法调用模式
当一个函数被保存为对象的一个属性时,我们称它为一个方法。当一个方法被调用时, this 被绑定到该对象。没啥好说的,上代码:
var myObject = {
value: 0,
increment: function (inc) {
this.value += typeof inc === 'number' ? inc : 1;
}
};
myObject.increment( );
document.writeln(myObject.value); // 1
如果调用表达式包含一个提取属性的动作(即包含一个.点表达式或 [subscript] 下标表达式),那么它就是被当做一个方法来调用。
函数调用模式
当一个函数并非一个对象的属性时,那么它就是被当做一个函数来调用的:
var sum = add(3, 4); // sum is 7
以此模式调用函数时,this 被绑定到全局对象。这是语言设计上的一个错误。
构造器调用模式
JavaScript 是一门基千原型继承的语言。这意味着对象可以直接从其他对象继承属性。该语言是无类型的。
如果在一个函数前面带上 new 来调用,那么背地里将会创建一个连接到该函数的 prototype 成员的新对象,同时 this 会被绑定到那个新对象上。new 前缀也会改变 return 语句的行为。
// 创建一个名为 Quo 的构造函数
// 它构造一个带有 status 属性的对象
var Quo = function (string) {
this.status = string;
};
// 给 Quo 的所有实例提供一个名为 get_status 的公共方法
Quo.prototype.get_status = function ( ) {
return this.status;
};
// 构造一个 Quo 实例
var myQuo = new Quo("confused");
document.writeln(myQuo.get_status( )); // 打印显示“confused”
Apply 调用模式
因为 JavaScript 是一门函数式的面向对象编程语言,所以函数可以拥有方法。
// 构造一个包含两个数字的数组,并将它们相加。
var array = [3, 4];
var sum = add.apply(null, array); // sum 值为 7
// 构造一个包含 status 成员的对象。
var statusObject = {
status:'A-OK'
} ;
// statusObject 并没有继承自 Quo.prototype, 但我们可以在 statusObject 上调
// 用 get_status 方法,尽管 statusObject 并没有一个名为 get_status 的方法。
var status= Quo.prototype.get_status.apply(statusObject);
// status 值为 'A-OK
异常
try、catch、throw:
var add = function (a, b) {
if (typeof a !== 'number' || typeof b !== 'number') {
throw {
name: 'TypeError',
message: 'add needs numbers'
};
}
return a + b;
}
var try_it = function ( ) {
try {
add("seven");
} catch (e) {
console.log(e.name + ': ' + e.message);
}
}
try_it( );
输出结果:
TypeError: add needs numbers
扩充类型的功能
JavaScript 允许给语言的基本类型扩充功能。
举例来说,我们可以通过给 Function.prototype 增加方法来使得该方法对所有函数
可用:
Function.prototype.method = function (name, func) {
this.prototype[name] = func;
return this;
};
递归
Recursion
汉诺塔例子:
var hanoi = function hanoi(disc, src, aux, dst) {
if (disc > 0) {
hanoi(disc − 1, src, dst, aux);
document.writeln('Move disc ' + disc +
' from ' + src + ' to ' + dst);
hanoi(disc − 1, aux, src, dst);
}
};
hanoi(3, 'Src', 'Aux', 'Dst');
递归函数可以非常高效地操作树形结构,比如浏览器端的文档对象模型 (DOM) 。每次递归调用时处理指定的树的一小段。
一些语言提供了尾递归优化(尾递归 (tail recursion tail-end recursion) 是一种在函数的最后执行递归调用语句的特殊形式的递归),这意味着如果一个函数返回自身递归调用的结果,那么调用的过程会被替换为一个循环,它可以显著提高速度。遗憾的是, JavaScript 当前并没有提供尾递归优化。深度递归的函数可能会因为堆栈溢出而运行失败。
闭包
Closure
函数字面量可以出现在任何允许表达式出现的地方。函数也可以被定义在其他函数中。一个内部函数除了可以访问自己的参数和变最,同时它也能自由访问把它嵌套在其中的父函数的参数与变量。通过函数字面量创建的函数对象包含一个连到外部上下文的连接。这被称为闭包 (closure) 。它是 JavaScript 强大表现力的来源。
例子:
// Create a maker function called quo. It makes an
// object with a get_status method and a private
// status property.
var quo = function (status) {
return {
get_status: function ( ) {
return status;
}
};
};
// Make an instance of quo.
var myQuo = quo("amazed");
document.writeln(myQuo.get_status( ));
回调函数
就是把函数的定义当作参数传递给另一个函数。
例子:
function eat(food, callback)
{
callback(food);
}
eat('薯片', function(food){
console.log("hbh 悲伤地吃 " + food);
})
eat('辣条', function(food){
console.log("hbh 开心地吃 " + food);
})
模块
我们可以使用函数和闭包来构造模块。模块是一个提供接口却隐藏状态与实现的函数或对
象。通过使用函数产生模块,我们几乎可以完全摒弃全局变扯的使用,从而缓解这个
JavaScript 的最为糟糕的特性之一所带来的影响。
模块模式通常结合单例模式(Singleton Pattern) 使用。JavaScript 的单例就是用对象字面量表示法创建的对象,对象的属性值可以是数值或函数,并且属性值在该对象的生命周期中不会发生变化。
级联
Cascade
有一些方法没有返回值。例如,一些设置或修改对象的某个状态却不返回任何值的方法就是典型的例子。如果我们让这些方法返回 this 而不是 undefined, 就可以启用级联。
最简单的例子就是我们一定见过的:
getElement('myBoxDiv')
.move(350, 150)
.width(100)
.height(100)
.color('red')
.border('10px outset')
.padding('4px')
.appendText("Please stand by")
.on('mousedown', function (m) {
this.startDrag(m, this.getNinth(m));
}).
.on('mousemove', 'drag')
.on('mouseup', 'stopDrag')
.later(2000, function ( ) {
this
.color('yellow')
.setHTML("What hath God wraught?")
.slide(400, 40, 200, 200);
})
.tip("This box is resizeable");
在这个例子中, getElement 函数产生一个对应千 id=“myBoxDiv” DOM 元素且给其注入了其他功能的对象。其中每一个.xxx的方法都返回该对象,以给下一次调用。
柯里化
Curry
函数也是值,从而我们可以用有趣的方式去操作函数值。柯里化允许我们把函数与传递给它的参数相结合,产生出一个新的函数。
参考这个回答:https://www.zhihu.com/question/30097211/answer/46785556
记忆
Memoization
函数可以将先前操作的结果记录在某个对象里,从而避免无谓的重复运算。。这种优化被称为记忆。
第五章:继承
JavaScript 是一门基于原型的语言,这意味着对象直接从其他对象继承。
第三章我们介绍过原型,并且我们当时给 Object 增加一个 create 方法。这个方法创建一个使用原对象作为其原型的新对象:
if (typeof Object.create !== 'function') {
Object.create = function (o) {
var F = function () {};
F.prototype = o;
return new F();
};
}
var another_stooge = Object.create(stooge);
按照我自己的理解,继承根本上就是连接原型而已,我们可以用书中的方法写一个“伪类”(Pseudoclassical)的方法去完成,通过Function.method('new', function () { ... });去添加new方法,并通过:
Function.method('inherits', function (Parent) {
this.prototype = new Parent( );
return this;
});
去添加inherits模拟继承,连接原型prototype。
当然也可以直接用我们写过的Object.create去构造达成差异化继承((differential inheritance)。
而对于private这样表示可见性的关键字,则可以通过应用模块模式去模拟,一个模板如下(加粗表示强调):

第六章:数组
实际上 JavaScript 没有像数组一样的数据结构,有的只是有一些类数组 (array-like)特性的对象。它把数组的下标转变成字符串,用其作为属性。它明显地比一个真正的数组慢,但它使用起来更方便。
var empty = [];
var numbers = [
'zero', 'one', 'two', 'three', 'four',
'five', 'six', 'seven', 'eight', 'nine'
];
empty[1] // undefined
numbers[1] // 'one'
empty.length // 0
numbers.length // 10
第三章我们说过,所有通过对象字面量创建的对象都连接到 Object.prototype, 它是 JavaScript 中的标配对象。而对于数组字面量,则是继承自 Array.prototype。和 Object.prototype 一样, Array.prototype 也可以被扩充,如扩充一个reduce函数:
Array.method('reduce', function (f, value) {
var i;
for (i = 0; i < this.length; i += 1) {
value = f(this[i], value);
}
return value;
});
[]后置下标运算符把它所含的表达式转换成一个字符串,如果该表达式有 toString 方法,就使用该方法的值。这个字符串将被用做属性名。
JavaScript 的数组通常不会预置值。如果你用[]得到一个新数组,它将是空的。如果你访问一个不存在的元素,得到的值则是 undefined 。
JavaScript 数组的 length 是没有上界的,并且 length 属性的值是这个数组的最大整数属性名加上 1,它不一定等于数组里的属性的个数,可是我实际验证的时候似乎有出入?
var myArray = [];
myArray[1000000] = true;
console.log(myArray.length); // 1000001
// myArray 只包含一个属性?
myArray.push('hbh');
console.log(myArray);
// 打印结果:[ <1000000 empty items>, true, 'hbh' ]
myArray.length = 1;
console.log(myArray);
// 打印结果:[ <1 empty item> ]
你可以直接设置 length 的值。设置更大的 leng吐不会给数组分配更多的空间。而把 length 设小将导致所有下标大于等于新 length 的属性被删除。
删除
splice:
var test = [1, 2, 3, 4, 5];
test.splice(1, 3); // 第一个参数为位置,第二个参数为删除个数
console.log(test); // [ 1, 5 ]
遍历
for in 无法保证属性的顺序,而大多数要遍历数组的场合都期望按照阿拉伯数字顺序来产生元素。此外,可能从原型链中得到意外属性的问题依旧存在。
我们只能用普通的for循环挨个遍历:
var i;
for (i = 0; i < myArray.length; i += 1) {
document.writeln(myArray[i]);
}
第七章:正则表达式
JavaScript 的正则表达式难以分段阅读,因为它们不支持注释和空白。在 JavaScript 程序中,正则表达式必须写在一行中。
可处理正则表达式的方法有 regexp.exec, regexp.test, string.match, string.replace, string.search, and string.split
第八章:方法
第九章:代码风格
第十章:优美的特性
糟粕
全局变量
共有3 种方式定义全局变量。
第1 种是在任何函数之外放置一个var 语句:
var foo = value;
第2种是直接给全局对象添加一个属性。全局对象是所有全局变量的容器。在Web 浏览器
里,全局对象名为window:
window.foo = value;
第3 种是直接使用未经声明的变量,这被称为隐式的全局变量:
foo = value;
自动插入分号
JavaScript 有一个自动修复机制,它试图通过自动插入分号来修正有缺损的程序。但是,千
万不要指望它,它可能会掩盖更为严重的错误。
typeof
typeof 运算符返回一个用于识别其运算数类型的字符串。
所以typeof 98.6返回’number’;而typeof null返回的是’object’,这很糟糕。
由于typeof 不能辨别出null 与对象,但你可以像下面这样做,因为null 值为假,而所有对象值为真:
if (my_value && typeof my_value ==='object') {
// my_value 是一个对象或数组!
}
在对正则表达式的类型识别上,各种JavaScript 的实现不太一致。对千下面的代码:
typeof /a/
一些实现会返回’object’ ,而其他的返回’function’ 。如果返回’regexp’ 可能会更有用些,但标准不允许那么做。
编译原理
回顾
这部分主要来自于《程序员的自我修养》。
编译过程一般可分为六步:扫描、语法分析、语义分析、源代码优化、代码生成和目标代码优化。
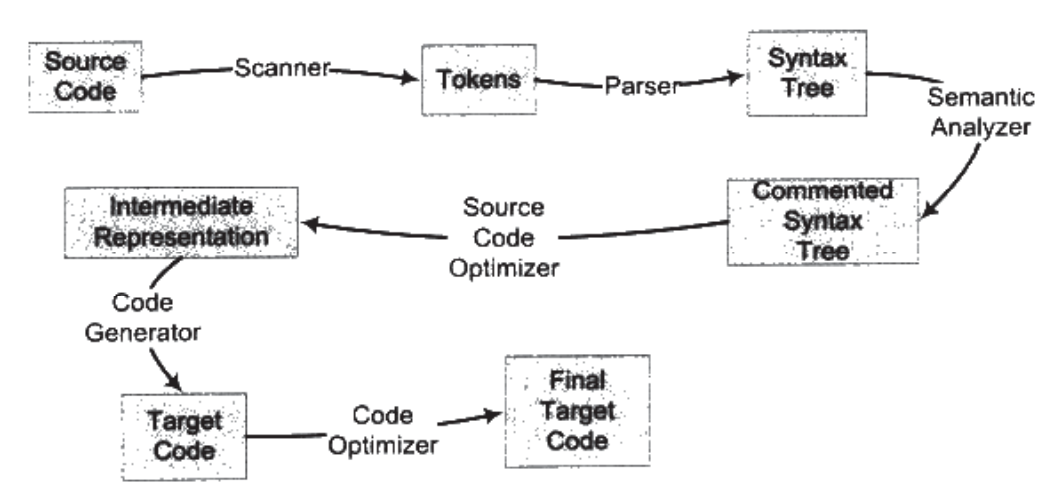
源代码
这里以一段C语言的代码为例,来自书籍《程序员的自我修养——链接、装载与库》:
array[index] = (index + 4) * (2 + 6);
词法分析
源代码程序输入到扫描器(Scanner),然后用有限状态机(Finite State Machine)去简单进行词法分析,分割成一系列Token。
| 记号 | 类型 |
|---|---|
| array | 标识符 |
| [ | 左方括号 |
| index | 标识符 |
| ] | 右方括号 |
| = | 赋值 |
| ( | 左圆括号 |
| index | 标识符 |
| + | 加号 |
| 4 | 数字 |
| ) | 右圆括号 |
| * | 乘号 |
| ( | 左圆括号 |
| 2 | 数字 |
| + | 加号 |
| 6 | 数字 |
| ) | 右圆括号 |
语法分析
接下来语法分析器(Grammar Parser)采用上下文无关语法(Context-free Grammar)之类的分析手段,将这些Token进行语法分析,产生语法树(Syntax Tree)。
简单的说,由语法分析器产生的语法树就是以表达式(Expression)为节点的树。
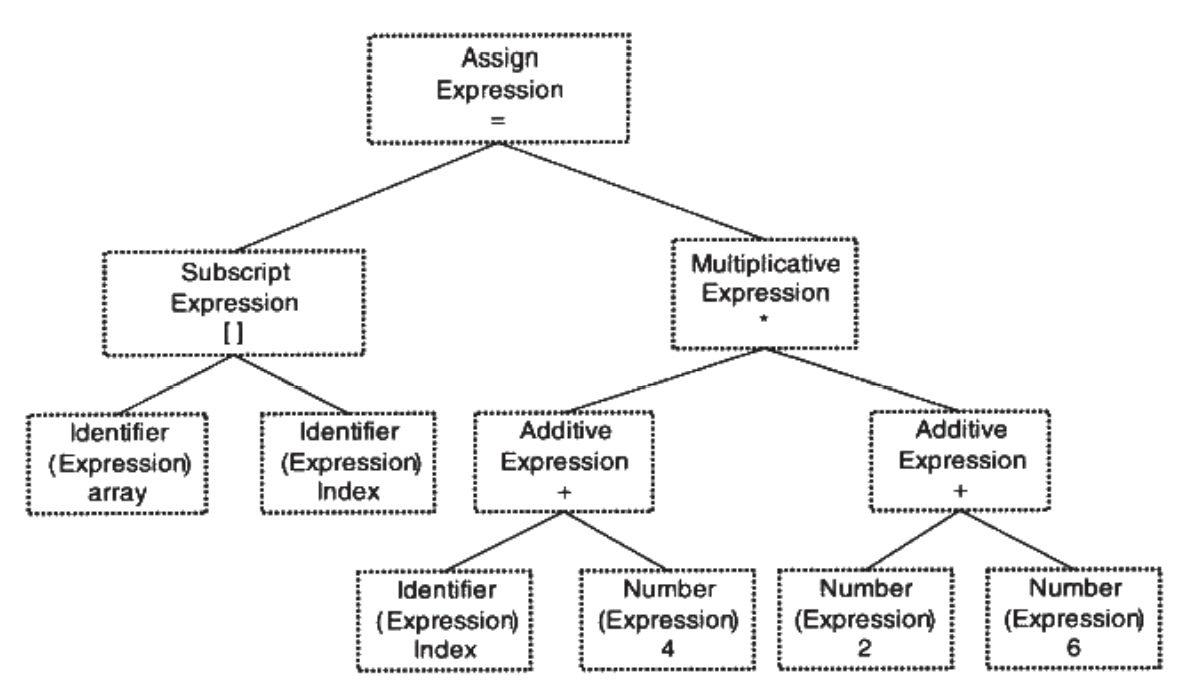
语义分析
接着语义分析器(Semantic Analyzer)完成对表达式的语法层面的分析,但它并不了解这个语句是否有意义(如两个指针相乘无意义,但是这一步检测不出)。
编译器所能分析的语义是静态语义(Static Semantic),即在编译期可以确定的语义,通常包括声明和类型的匹配、类型的转换。如C风格的隐式转换这一步都要做好。而像除以0这样的错误则属于动态语义(Dynamic Semantic),在运行期才能确定。
经过语义分析后,整个语法树的表达式都被标识了类型,对于那些隐式转换的类型也将会在这一步被插入相应的转换节点:
中间语言生成
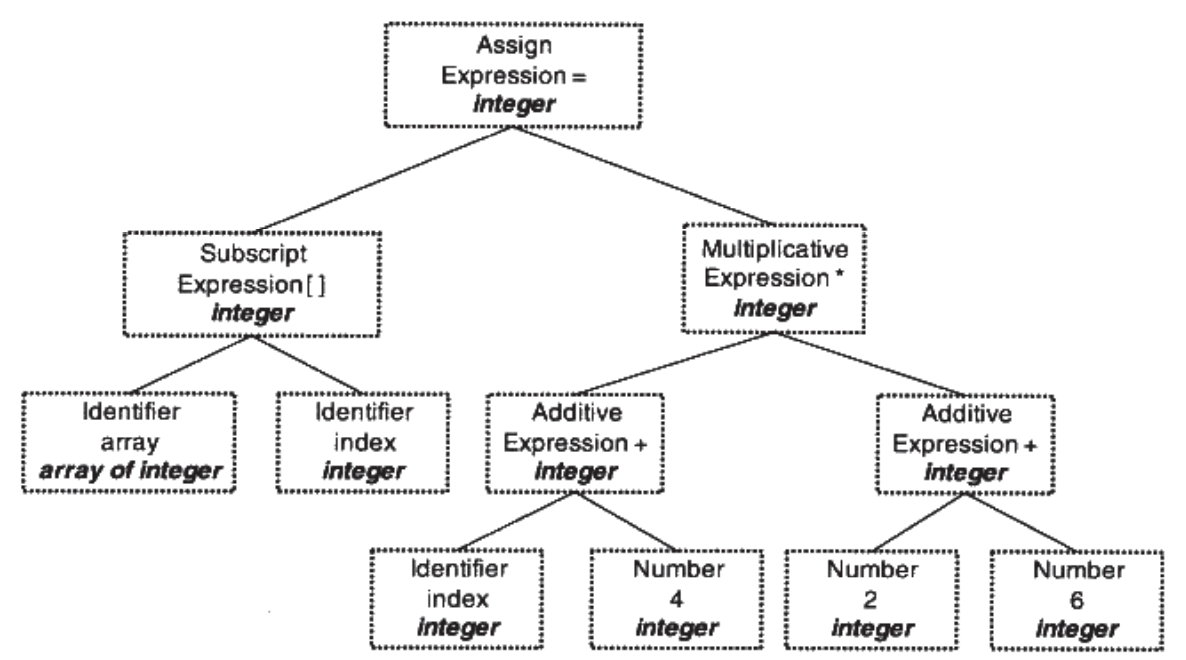
源码级优化器(Source Code Optimizer)会在源代码级别进行优化,其在不同编译器中可能会有不同的定义或一些其他的差异。
比如这个例子中2 + 6可以在编译期就被直接优化为8,类似的还有很多其他复杂的优化过程,经过优化后的语法树如下图:

而像如(2 + 6)直接优化为8,其实在语法树上优化比较困难,所以源代码优化器往往将整个语法树转换为中间代码(Intermediate Code),它是语法树的顺序表示,已经非常接近目标代码了。
中间代码有很多类型,在不同编译器有不同的形式,最常见的如三地址码(Three-address Code)、P-代码(P-Code)。
以三地址码(x = y op z,即将变量y和z进行op操作后赋值给x)举例,例子中的语法树被翻译为:
t1 = 2 + 6
t2 = index + 4
t3 = t2 * t1
array[index] = t3
在三地址码的基础上进行优化后如下:
t2 = index + 4
t2 = t2 * 8
array[index] = t2
中间代码使得编译器可以被分为前端和后端。编译器前端负责产生机器无关的中间代码,编译器后端将中间代码转换为目标机器代码。这样对于一些可以跨平台的编译器而言,它们可以针对不同的平台使用同一个前端和针对不同机器平台的数个后端。
目标代码生成与优化
源代码级优化器产生中间代码标志着接下来的过程都属于编译器后端。
编译器后端主要包括代码生成器(Code Generator)和目标代码优化器(Target Code Optimizer)。
代码生成器将中间代码转换成目标机器代码,这个过程十分依赖于目标机器,因为不同的机器有着不同的字长、寄存器、整数数据类型和浮点数数据类型等。经过这一步,刚刚的中间代码有可能生成如下的代码序列(x86的汇编语言来表示):

最后目标代码优化器对上述的目标代码进行优化,比如选择合适的寻址方式、使用位移来代替乘法运算、删除多余的指令等,这里我们把乘法优化为基址比例变址寻址(Base Index Scale Addressing)的lea指令完成,随后由一条mov指令完成最后的赋值操作:

JavaScript编译原理
参考了这位大佬的回答:
https://www.zhihu.com/question/265364484/answer/2218372163
以及喵喵老师的视频(虽然不是js,但是很有帮助):
https://www.bilibili.com/video/BV1L7411C7K1?p=3

同时想更深入了解JavaScript,推荐这个大佬的一些文章:https://zhuanlan.zhihu.com/p/55430043,不过我不是做前端的,只是粗略了解一二,没有深入了。
有一个网站:https://esprima.org/demo/parse.html,可以在这个上面调试验证抽象语法树的创建。
在第二章语句我们曾讲过:
一个编译单元包含一组可执行的语句。在 Web 浏览器中,每个<script>标签提供一个被编译且立即执行的编译单元。因为缺少链接器, JavaScript 把它们一起抛到一个公共的全局名字空间中。
拿一段代码举例:
var a = 8;
source => tokens
扫描后生成Tokens:
| 记号 | 类型 |
|---|---|
| var | Keyword |
| a | Identifier |
| = | Punctuator |
| 8 | Numeric |
| ; | Punctuator |
举个例子,我们解析的时候可以逐行解析,看到一个字母就去找一个最长的字符串并进行匹配,一般token的种类比较少。
tokens => abstract syntax tree
token stream => statement sequence,其实就是abstract syntax tree(AST)
可以采用递归下降解释器(recursive descent parser),以喵喵老师写的程序为例,虽然是老师自造的编程语言,但是原理是通的:
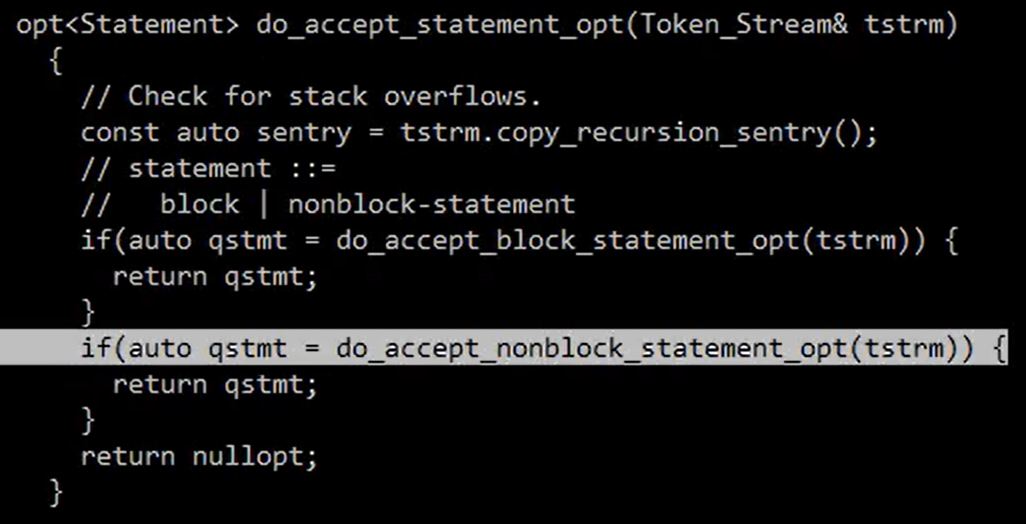
对于一个语句,带花括号{}的称作block statement(这里貌似就与js不一样,js在es6前是没有块级作用域的,并且对于if、while、do或for语句还有Block-less Statements语法,像C++一样在if后不写大括号,表示允许的下一条的那个表达式)。
通过这个函数去分析Token,如果读到左花括号就认为是block statement,如果不是block就尝试非块的语句分析:

具体是啥statement简单分析就好了。比如遇到一个token是break那就是break statement
解析后生成抽象语法树(AST)

最后进行代码生成,将抽象语法树转换成最终可执行的代码。
继续以喵喵老师讲的为例:
abstract syntax tree => high-level intermediate representation
这样变换有一个原因是,比如循环有 for循环、while循环、do while循环,可以先变成一种形式。还有就是之前说的中间代码生成(当然这里是高级别的IR),方便优化。
这部分也是所谓的 code generation
对每个语句调用 generate_code:

如果是表达式,就接着去分析,以此类推。
execute
转换成IR之后就可以对IR进行解释执行了,当然还有其他的优化手段。
作用域
ES6以前,JavaScript是没有块级作用域的。其只有全局作用域和函数作用域。
因此如下的代码:
if (true)
{
var a = 10;
}
console.log(a);
可以很好地输出10,因为if不是函数。而如果把true该换为false,由于这里的a属于全局变量,在代码的分词阶段和解析阶段系统就已经默认给了它一个undefined,而由于是false没有运行赋值语句,故会打印出undefined。
和C一样,作用域是分层的,内层作用域可以访问外层作用域的变量,反之则不行。因此内层作用域找不到的一个变量就会上升到外层作用域去寻找。
ES6以后引入的let/const
这部分我参考了:https://zhuanlan.zhihu.com/p/140263205
其实就是通过const和let来实现一个块级作用域,被他俩标记的变量会进入词法环境,形成一个栈来做到块级作用域,从而达到类似C的风格。
编译器和解释器
推荐大神的回答:https://www.zhihu.com/question/19608553/answer/18628779
编译器把一种语言的程序翻译成另一种语言,比如g++把C++代码预处理得到的 .i 到汇编语言 .s 的过程叫做编译;也把C语言到机器语言的过程叫做编译。而机器语言依然要由操作系统去解释执行。
而对于C#和JAVA,它们则是运行在虚拟机上,这意味着代码首先被编译成一种中间语言,当在目标平台运行应用程序时,虚拟机在程序运行时再转换成机器码。
实际上很多解释器内部是以“编译器+虚拟机”的方式来实现的,先通过编译器将源码转换为AST或者字节码,然后由虚拟机去完成实际的执行。
解释器中的编译器的输出可能是AST,也可能是字节码之类的指令序列;一般会把执行后者的程序称为VM,而执行前者的还是笼统称为解释器或者树遍历式解释器(tree-walking interpreter)。这只是种习惯而已,并没有多少确凿的依据。只不过线性(相对于树形)的指令序列看起来更像一般真正机器会执行的指令序列而已。
所以编译器是把一种语言翻译成另一种语言,而解释器要承担编译器的全部责任,同时还要把编译出来的东西去执行。因此解释器 = 编译 + 执行,而编译器只负责其中编译的部分。因此如果实现出解释器再把它变成编译器是没有问题的,反过来则不行。















 8459
8459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









