






AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
摘要
虽然 Transformer 架构已成为自然语言处理任务的事实标准,但其在计算机视觉中的应用仍然有限。在视觉中,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变。我们表明,这种对 CNN 的依赖是不必要的,直接应用于图像块序列(image patch)的纯Transformer可以很好地执行图像分类任务。当对大量数据进行预训练并转移到多个中小型图像识别基准(ImageNet、CIFAR-100、VTAB 等)时,Vision Transformer (ViT) 与 效果最好的卷积网络相比,同时需要更少的计算资源来训练。
Transformer应用到视觉的难处
如何把一个2D的图片变成一个1D的集合。其中一个想法就是将2D图片中的每一个像素看成是一个NLP中的单个元素(词),然后将2D的图片拉直,将它放入transformer中训练。但是该想法实现起来复杂度太高。例如一张224224大小的图片如果采用上述方法进行拉直,会产生一个(224224)50176个元素,复杂度相当大了。
VIT之前,Transformer在视觉中的应用
“Non-local neural networks”这篇论文的作者将自注意力机制应用到卷积神经网络的特征图中,特征图的尺寸比原图像小得多,作者将特征图拉直作为transformer输入元素的个数在一定程度上解决了复杂度过大的问题。
“Stand-alone self-attention in vision models”这篇论文的作者用一个小窗口,在小窗口里面使用自注意力机制。
“Axial-deeplab: Stand-alone axial-attention for panoptic segmentation”这篇论文的作者采用轴自注意力机制,将一个2D的图像分别在长和宽方向使用自注意力机制,相当于转化成了两个1D的自注意力机制。
虽然前面的工作理论上是高效的,但是因为使用特殊的注意力部分,它们并不能使用硬件加速导致不高效。
受 NLP 中 Transformer 可扩展性的启发,ViT作者尝试将标准 Transformer 直接应用于图像,尽可能少地修改。
实现思路
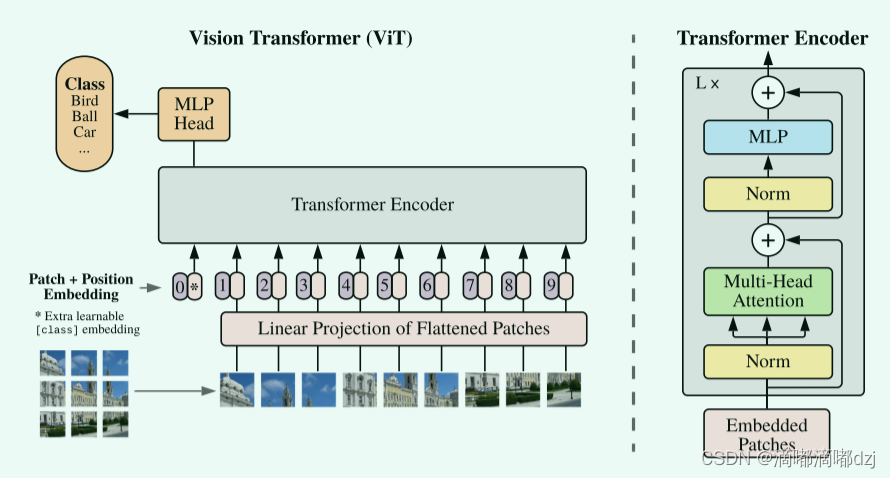
作者将一个图片分成了一个个的patches,然后提供一个线性嵌入序列,作为transformer的输入。这一个个patch被当作NLP应用中的tokens或者说是words。例如,本文作者使用的patch大小为1616,那么一张224224的图片就被转化为14*14=196个patch了。然后作者再将这196个patch作为transformer的输入。















 5073
5073











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











