






 本文介绍发表于NeurIPS的论文PointCNN,作者为解决点云数据不规则无序难以卷积的问题,提出可学习的X-transformer矩阵。阐述了PointCNN的层次化卷积结构、X-Conv算子等,还进行了实验,验证其性能,不过对X -Conv的严格理解仍是待解决问题。
本文介绍发表于NeurIPS的论文PointCNN,作者为解决点云数据不规则无序难以卷积的问题,提出可学习的X-transformer矩阵。阐述了PointCNN的层次化卷积结构、X-Conv算子等,还进行了实验,验证其性能,不过对X -Conv的严格理解仍是待解决问题。
收录期刊会议:NeurIPS(CCF-A)
日期:2018年
作者:Yangyan Li
单位:山东大学
论文链接:PointCNN: Convolution On X -Transformed Points
一、Abstract
出发点:作者想在Point cloud数据集中运用卷积操作。
难点:点云数据是不规则和无序的,直接对点云特征进行卷积操作会导致形状信息的丢失和点之间排序的变化。
解决方案:提出一个可学习的X-transformer矩阵,其可以同时提升两个原因:
- 第一种是对与点相关的输入特征进行加权。
- 第二种是将点排列成潜在的、可能是典型的顺序。换句话说其可以对输入点云的顺序进行处理,使输入点云的顺序不会影响模型的输出结果。
二、Introduction

图中i表示的使规则的输入数据的卷积情况,但是点云的排序可能是任意的,如图ii-iv所示。如果直接对其进行卷积操作(公式(1a)),其结果是放弃了形状信息(即 fii ≡ fiii),而保留了排序的方差(即 fiii != fiv)。但是对于点云来说ii和iii虽然特征相同,但是其位置分布不一样(即形状不一样),卷积过后的值应当不同。而iii和iv虽然输入的点云顺序不一样,但是其本质上是同一点云集合,卷积过后的值应该一致。为此作者提出通过一个多层感知机(MLP)为K个输入点学习一个K*K的X-transformation矩阵。该矩阵能够将点云集的形状考虑在内,同时对点云的顺序进行置换(排序)。
三、Relate Work
3.1 Feature Learning from Regular Domains.
CNN的成功的关键是有效的利用了图像空间的局部相关性,但是卷积带来了高计算量和存储量的问题,基于此许多方法被提出以解决该问题,主要的方式是通过稀疏卷积来实现。在本文提出的PointCNN在输入和卷积核上都是稀疏的。
3.2 Feature Learning from Irregular Domains
PointNet和PointNet++等一系列通过对称池来解决点云输入顺序的问题都会导致一定的信息丢失。另一些方法是将点云“内插或投射”到预定义的规则区域,在这规则区域经典的CNN就可以被使用。规则区域是潜在在我们的方法内的。有的方法是将CNN 内核被表示为邻域点位置的参数函数,从而将 CNN 广义用于点云。在这些方法中,与每个点相关的核都是单独参数化的,而我们方法中的 X-Transformation是从每个邻域学习的,因此可能对局部结构更具适应性。
3.3 Invariance vs. Equivariance.不变性与等方差
解决在实现不变性时汇集的信息丢失问题,在PointCNN中,X-Transformation被假定为既用于加权又用于置换,因此成为模型的通用矩阵。
四、PointCNN
4.1层次化卷积结构
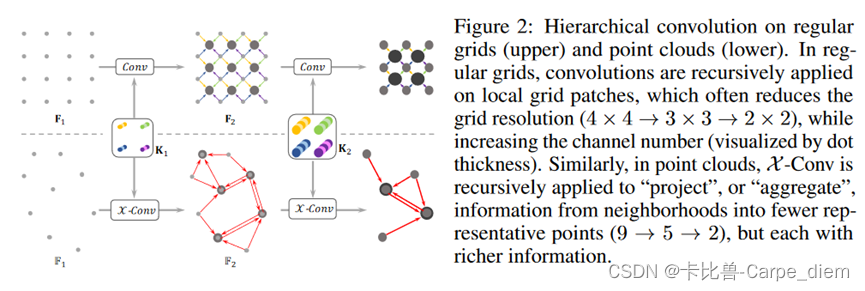
上半部分是常规的规则网格的层次化卷积操作,下半部分是点云中使用X-Conv卷积核对点云数据进行卷积,每次卷积将周围的点“投影或聚集”到代表点,随着层次卷积的深入,代表点的数量越来越少,但是特征数量越来越多,图中用圆点的大小表示特征数的多少。
PointCNN的输入:
{
p
1
,
i
,
f
1
,
i
:
i
=
1
,
2
,
.
.
.
,
N
1
}
\{{{p}_{1,i}},{{f}_{1,i}}:i=1,2,...,{{N}_{1}}\}
{p1,i,f1,i:i=1,2,...,N1} ,f的特征维度为C1,经过X-Conv后为
{
p
2
,
i
,
f
2
,
i
:
i
=
1
,
2
,
.
.
.
,
N
2
}
\{{{p}_{2,i}},{{f}_{2,i}}:i=1,2,...,{{N}_{2}}\}
{p2,i,f2,i:i=1,2,...,N2} ,f的特征维度为C2,C2>C1,N2<N1。在递归使用X-Conv时,代表点的数量是递减的,但是每个代表点都包含越来越丰富的特征。
4.2 X-Conv 算子

算子公式: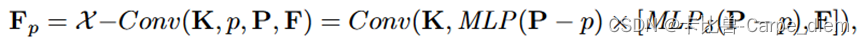
因为算子内所有的函数都是可微的,所以算子也可微。像基于PointNet的方法一样,将坐标提升到特征的方法是通过逐点MLP实现的。但是,对点云的无序处理的方法不是通过对称函数实现的,取而代之的是,与相关联的特征一起,它们被所有邻域共同学习的X-Transformation加权和置换得到的。
得到的X取决于点的顺序,这正是所期望的,因为X应该通过输入的点来变换F*,因此必须知道具体的输入顺序。对于没有任何附加特征(即只包含坐标特征)的输入点云,即F为空,第一个X-Conv图层仅使用Fδ。PointCNN因此可以通过一种鲁棒性强的同一的方式处理有或没有附加特征的点云数据。
4.3 PointCNN结构
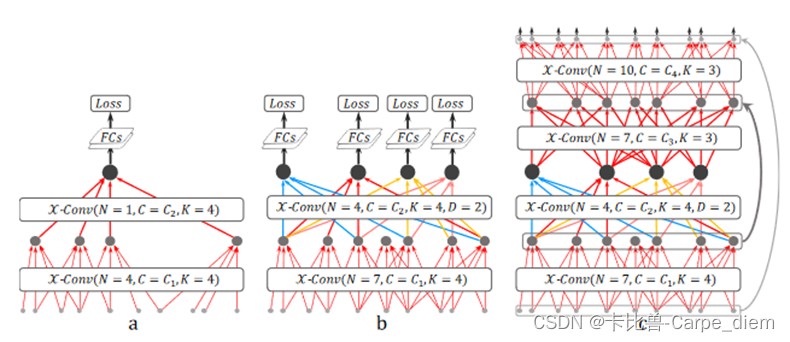
图a是一个PointCNN的经典结构,其中N和C表示输出代表点的数量和特征维度,K表示邻域点数。在 PointCNN 中,我们可以将每个代表点的感受野大致定义为 K/N 的比率。
因为图a的下降速度过快,使得训练不彻底,为此,图b使用了密集连接,更多的代表点被保留,这样越深的点就能看到整个形状中越大的部分。为实现这个效果,作者借鉴CNN网络中空洞卷积(dilated convolution)的思想,将K大小邻域替换成KD大小邻域,D为扩张率(dilation rate)。这种情况下,感受野就由K/N扩大为(KD)/N。分类结果的输出会在SoftMax之前讲多个输出结果求平均值。
图c为PointCNN在分割任务中的神经网络,其采用了类似U-Net的Conv-DeConv结构。DeConv与Conv相比,输出点更多,但特征通道更少。
4.4 数据增强
为了训练 X -Conv 中的参数,对于一个特定的代表点,以相同的顺序不断使用同一组邻近点显然是无益的。为了提高泛化能力,我们对输入点进行随机抽样和打乱。同时对于每个输入点云N的取值,我们在(N/8)^2的子集内取,N表示高斯分布。这样做的目的是为了丰富训练数据,以提高模型的鲁棒性。
五、实验
5.1数据集:
分类:ModelNet40、ScanNet、TU-Berlin、Quick Draw、MNIST、CIFAR10
分割:ShapeNet Parts、S3DIS、ScanNet
分类实验的输入点云数为1024,分割实验的输入点云数为2048。
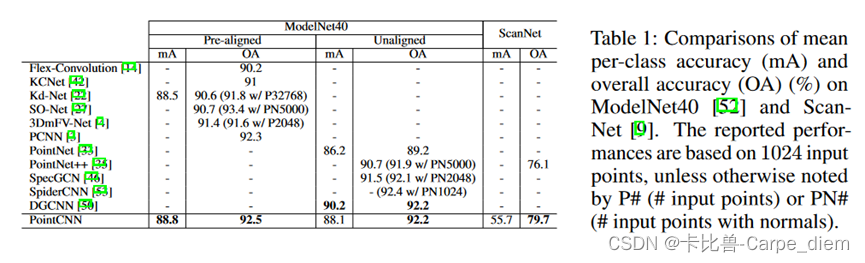
5.2分类结果:
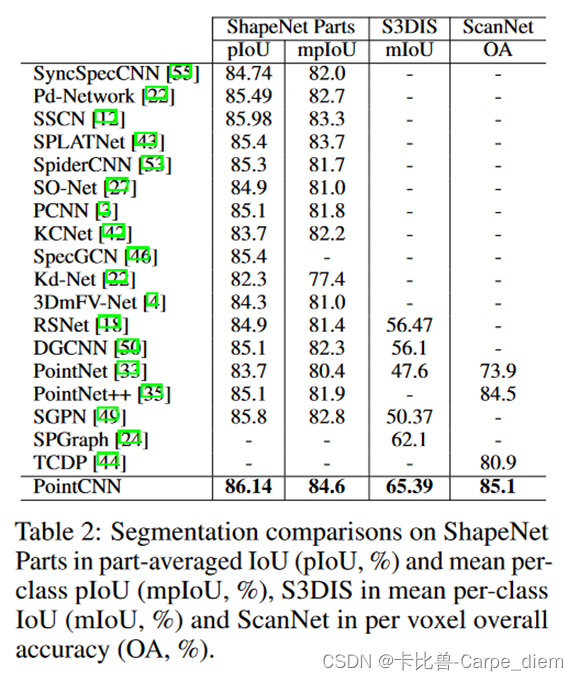
5.3 Conv与X-Conv的性能比较
由于 X-Conv 是 Conv 的泛化,如果基础数据相同,只是表示方法不同,理想情况下,PointCNN 的性能应与 CNN 相当。MNIST和CIFAR10数据集验证这一点。在CIFAR10数据集中,PointCNN由于缺少形状信息,所以只能从RGB的分布中学习空间局部信息,这导致性能与CNN有较大差距。对于PointNet++的低精度问题,作者给出的解释是:缺少形状信息,加上RGB特征在经过最大池化处理后变得无法区分。
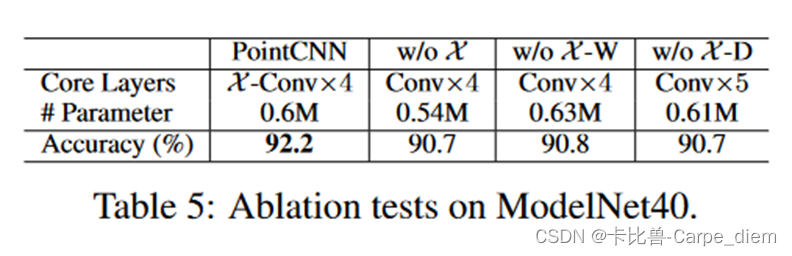
5.4 X-Conv的消融实验
消融实验证明了X-transformation矩阵在对特征划分有积极作用。

六、遗留问题
虽然经验证明 X -Conv 在实践中是有效的,但对它的严格理解,尤其是在合成到深度神经网络中时,仍然是未来工作的一个开放性问题


















 1679
1679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











