






之前一直对反向传播机制一知半解,最近花了点时间把这个问题想了想,记录于此。
反向传播时神经网络学习能力的具体体现,他表示损失函数对参数的梯度反向流动,以此来更新网络中的参数值。在这期间需要注意的是,网络的可学习参数值是自变量,输入为可学习参数的权重,损失函数是因变量。其核心思想时链式求导法则。
一个反向传播的全过程包括误差传播,可学习参数的更新。
以全连接神经网络为例,一个完整的正向传播如下图所示:
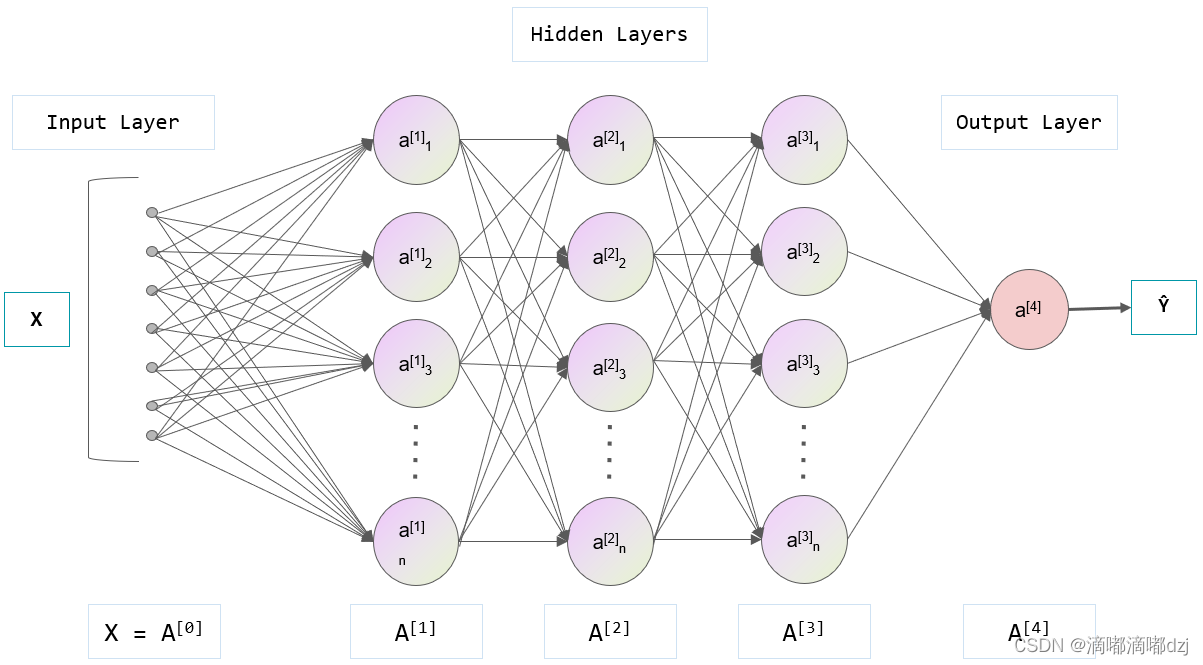
这是一个二分类的网络前向传播图,每个节点表示一个神经元,其包含可学习参数W和b。
对上图进行简单化和抽象化,我们形成了下图每层一个神经元的神经网络:

前一个神经元激活函数的输出会作为下一个神经元的输入。
1、前向传播
由此我们可以得到一个中间层神经元的前向传播的计算公式:
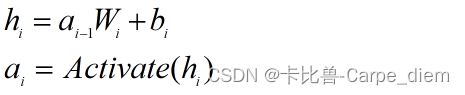
2、反向传播
2.1每个隐藏层只含单神经元
根据上图给的单神经元的全连接网络的前向传播图,我们可以推出损失函数对图中对hi和ai的偏导数为:

2.2每个隐藏层含多个神经元
对于一层中存在多个神经元的情况,在求hij的偏导数时只需将同一层个神经元对应的偏导数相加即可,如下公式:
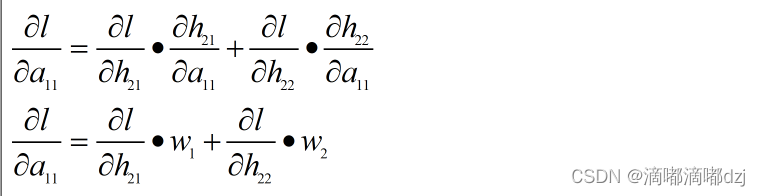
2.3对可学习参数W,b的偏导数
通过上述公式可以很容易得到W和b的偏导数,具体公式如下所示:
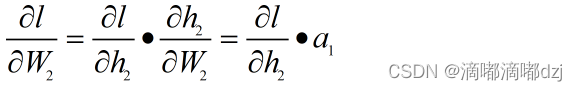
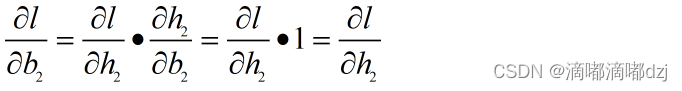
3、反向传播代码实现
from torch.nn import Sigmoid, Tanh, ReLU, Softmax
class Layer():
def __init__(self) -> None:
self.W #(input_dim, out_dim)
self.b #(1, out_dim)
self.activate = Sigmoid()
def forward(self, input_data):
h = input_data @ self.W + self.b
a = self.activate(h)
return a
def backward(self, input_grad):
h_grad = input_grad * self.activate.grad(a)
b_grad = h_grad
W_grad = (input_data.T) @ h_grad
self.b -= learning_rate * b_grad
self.W -= learning_rate * W_grad
return h_grad @ (self.W).T
4、softmax的反向传播公式
上述代码为反向传播机制的伪代码,上面介绍的反向传播的输出层用到的都是sigmoid函数,该激活函数h与a是一一对应的,如果用到的激活函数为softmax函数h与a是多对多的关系,则下式中逐元素相乘是失效的:
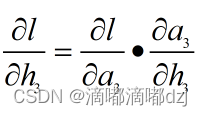
但最后上式会转化成a-y,a为激活函数,y为one-hot编码的向量
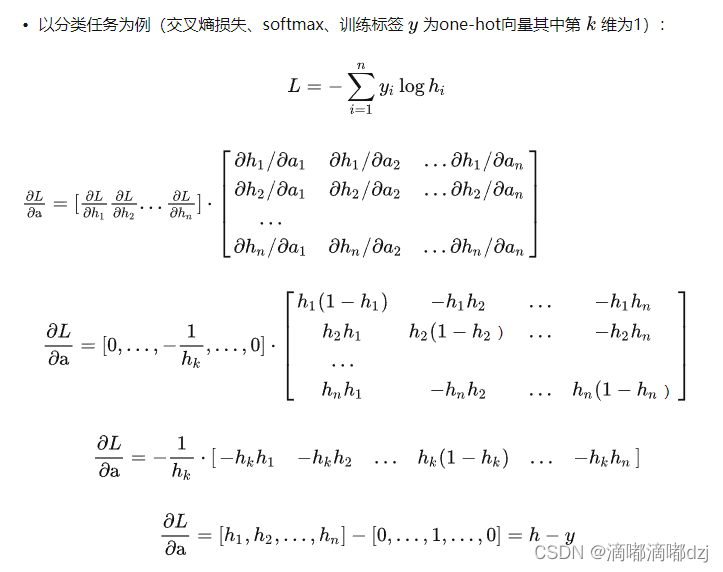

上述推导公式的隐藏层和激活函数输出分别为a和h。
python伪代码如下:
# * 表示element-wise乘积,· 表示矩阵乘积
class Output_layer(Layer):
'''属性和forward方法继承Layer类'''
def backward(input_grad):
'''输出层backward方法'''
'''单个样本的反向传播'''
a_grad = input_grad # (1, output_dim)
b_grad = a_grad # (1, output_dim)
W_grad = (input_data.T) @ a_grad # (input_dim, output_dim)
self.b -= learning_rate * b_grad
self.W -= learning_rate * W_grad
return a_grad @ (self.W).T # (1, input_dim)
5、批量计算的反向传播
python伪代码如下所示:
# * 表示element-wise乘积,· 表示矩阵乘积
class Layer:
'''中间层类'''
def forward(self, input_data): # input_data: (batch_size, input_dim)
'''batch_size个样本的前向传播'''
input_data @ self.W + self.b = a # a: (1, output_dim)
h = self.activate(a) # h: (1, output_dim)
return h
def backward(input_grad): # input_grad: (batch_size, output_dim)
'''batch_size个样本的反向传播'''
a_grad = input_grad * activate’(a) # (batch_size, output_dim)
b_grad = a_grad.mean(axis=0) # (1, output_dim)
W_grad = (input_data.reshape(batch_size,input_dim,1)
@ a_grad.reshape(batch_size,1,output_dim)).mean(axis=0)
# (input_dim, output_dim)
self.b -= lr * b_grad
self.W -= lr * W_grad
return a_grad @ (self.W).T # output_grad: (batch_size, input_dim)
class Output_layer(Layer):
'''输出层类:属性和forward方法继承Layer类'''
def backward(input_grad): # input_grad: (batch_size, output_dim)
'''输出层backward方法'''
'''batch_size个样本的反向传播'''
a_grad = input_grad # (batch_size, output_dim)
b_grad = a_grad.mean(axis=0) # (1, output_dim)
W_grad = (input_data.reshape(batch_size,input_dim,1)
@ a_grad.reshape(batch_size,1,output_dim)).mean(axis=0)
# (input_dim, output_dim)
self.b -= learning_rate * b_grad
self.W -= learning_rate * W_grad
return a_grad @ (self.W).T # output_grad: (batch_size, input_dim)
参考链接:
知乎–反向传播详解















 8531
8531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











