







回归任务之慈善机构评分预测
摘要:回归模型是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。这种技术通常用于预测分析,时间序列模型以及发现变量之间的因果关系。回归模型重要的基础或者方法就是回归分析,回归分析是研究一个变量(被解释变量)关于另一个(些)变量(解释变量)的具体依赖关系的计算方法和理论,是建模和分析数据的重要工具。常用的回归模型有线性回归、岭回归、逐步回归、多项式回归等。使用回归分析有很多好处,比如它表明自变量和因变量之间的显著关系;它表明多个自变量对一个因变量的影响强度。而本实验将采用几种回归模型进行慈善机构的评分预测,通过训练出来的数据和均方误差来评估性能好坏。
关键词:回归 预测 线性回归 均方误差
一、问题介绍
在训练集中共有7400个样本,每个样本有23个特征,利用ascore,category,description,……,program_exp,fund_exp,admin_exp等23个特征,预测出score值。
特征具体介绍如下:
ascore:问责制和透明度得分(满分 100)。
category:机构类别,包含艺术,文化,人文,宗教和教育等等类别。
description:机构介绍,即机构简介。
ein:机构编号,每个机构编号唯一。
tot_exp:总费用(以美元计)(由计划 + 资金 + 行政这三部分组成)。
admin_exp_p:行政费用百分比(占总费用)。
fund_eff:以美元为单位的资金效率(筹集 1 美元捐款所花费的金额)。
fund_exp_p:资金费用百分比(总费用)。
program_exp_p:计划费用百分比(总费用)。
fscore:财务评分(满分 100)。
leader:机构领导者姓名。
leader_comp:机构领导者的薪酬(美元)。
leader_comp_p:领导百分比薪酬(即领导的薪酬占总薪酬的百分比)。
motto:标语,每个机构的宣传标语。
name:慈善机构名称。
tot_rev:该机构的总收入(美元)。
score:该机构所得的总分(满分 100)。
state:该机构的目前状态。
subcategory:子类,即该慈善机构还负责其他类型的活动。
size:慈善规模,有big,small,mid三种。
program_exp:以美元计的计划费用,即该机构在其提供的计划和服务上花费的金额。
fund_exp:以美元计的资金费用,即该机构筹集资金的金额。
admin_exp:行政费用(美元),即该机构管理费用、员工、会议费用。
测试集中共有1000个样本,每个样本有22个特征,没有训练集中的score这一项特征。
要求说明:
1.训练集与测试集中均有部分特征的值缺失,需要对缺失特征值做相应的处理。
2.有许多特征是文本特征,如需要利用这些特征,则需要进行预处理。
3.将用结果的均方根误差(RMSE)来评价模型的好坏。
二、算法概述
梯度树提升 Gradient Tree Boosting
Boosting是一类将弱学习器提升为强学习器的算法。这类算法的工作机制类似:先从初始训练集中训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注。
然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器的数目达到事先指定的值T,最终将这T个基学习器进行加权结合。
梯度提升(gradient boosting)属于Boost算法的一种,也可以说是Boost算法的一种改进,它与传统的Boost有着很大的区别,它的每一次计算都是为了减少上一次的残差(residual),而为了减少这些残差,可以在残差减少的梯度(Gradient)方向上建立一个新模型。所以说,在Gradient Boost中,每个新模型的建立是为了使得先前模型残差往梯度方向减少,
与传统的Boost算法对正确、错误的样本进行加权有着极大的区别。
GBRT的优势有:
(1)自然而然地处理混合类型的数据
(2)预测能力强
(3)在输出空间对于异常值的鲁棒性强(通过强大的损失函数)
然而,GBRT也有劣势:
可扩展性方面,由于提升的时序性,不能进行并行处理
梯度树提升算法步骤:
对于给定的输入:训练数据集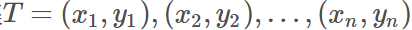
损失函数: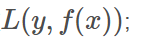
输出结果:一棵回归树f(x)
(1)首先初始化
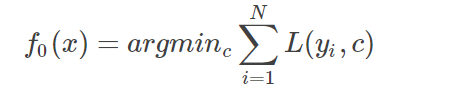
估计一个使损失函数极小化的常数值,此时它只有一个节点的树;
(2)迭代的建立M棵提升树
for m=1 to M:(第一层循环)
for i=1 to N:(第二层循环) 计算损失函数的负梯度在当前模型的值,并将它作为残差的估计值。
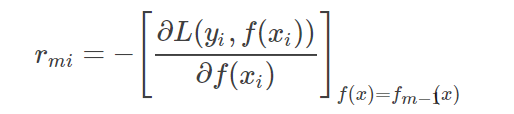
对于rmi拟合一棵回归树,得到第m棵树的叶节点区域Rmj,j=1,2,…,J
for j=1 to J:(第二层循环),计算:
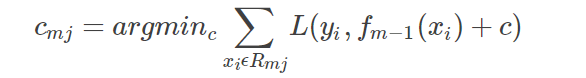
利用线性搜索估计叶节点区域的值,使损失函数极小化;然后,更新
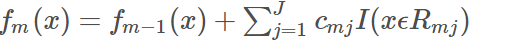
(3)最后得到的fm(x)就是我们最终的模型
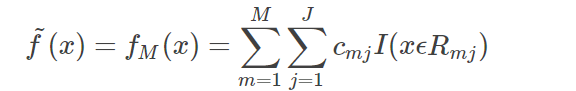
梯度提升决策树是监督学习中最强大也最常用的模型之一。其主要缺点是需要仔细调参,而且训练时间可能会比较长。与其他基于树的模型类似,这一算法不需要对数据进行缩放就可以表现的很好,而且也适用于二元特征与连续特征同时存在的数据集。与其他基于树的模型相同,它也通常不适用于高维稀疏矩阵。
三、具体步骤
3.1导入项目所需要的包:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import metrics # 计算均方误差
3.2读取训练集数据,共有7400个样本:
# 1.读取数据
train_data = pd.read_csv('train.csv')
train_data = train_data.iloc[:, :23] # 截取,去除空列
train_data = train_data.drop(
columns=['category', 'description', 'ein', 'leader', 'motto', 'name', 'state', 'subcategory', 'size']) # 去除字符特征
# print(train_data)
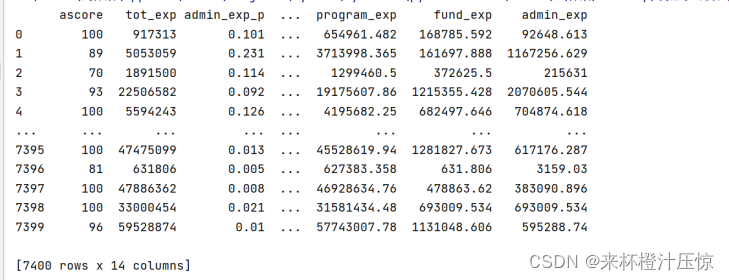
在CSV文件中可以看到有9列特征是字符特征,所以也要去掉,最后保留14个数字特征,效果如上图所示
3.3去除异常数据:
# 2.1去除异常数据
pd.set_option('display.width', None) # 设置数据展示宽度
cols = train_data.columns
train_data = train_data[cols].apply(pd.to_numeric, errors='coerce')
train_data = train_data.dropna()
print(train_data)
for i in range(len(train_data)):
x=np.delete(train_data,axis=0) #删除样本异常数据值
train_data=train_data.dropna()
print(train_data)
可以看到经过处理得到真正有用的数据有7004行
3.4提取csv文件中目标值score:
# 2.2将文件中score值单独提取出来
score = train_data.iloc[:, 10:11]
y_data = np.array(score)
train_data = train_data.drop(columns=['score']) # 从原数据帧中删除score列
print(y_data)
3.5提取特征,绘制特征与score值相关的散点图,查看相关性:
# 2.3提取特征,绘制散点图
feature_np = train_data.columns
feature_np = np.array(feature_np)
# print(feature_name)
# 提取各特征数值
from sklearn.preprocessing import StandardScaler
scalar = StandardScaler()
train_data = np.array(train_data)
ax = scalar.fit_transform 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6209
6209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











