






MADDPG(Multi-agent Deep Deterministic Policy Gradient)由以下三部分演变而来:确定性策略梯度算法DPG(Deterministic Policy Gradient),深度确定性策略梯度算法DDPG(Deep Deterministic Policy Gradient)和多智能体深度确定性策略梯度算法MADDPG(Multi-agent Deeep Deterministic Policy Gradient),也就是说,整个算法的基础是DPG,并采用深度神经网络来解决控制空间不连续的问题,最后加入多个智能体,成为MADDPG。
因此,MADDPG主要解决的是连续状态空间及连续控制空间的问题。
首先,用一张图来表示DDPG的整体结构,其中,S表示智能体状态,A表示智能体的动作,Q值为从任务开始到结束智能体状态的总奖励值。而Actor-Critic网络则用来寻找最大的Q值。可以理解为Actor是演员,Critic是评论家。
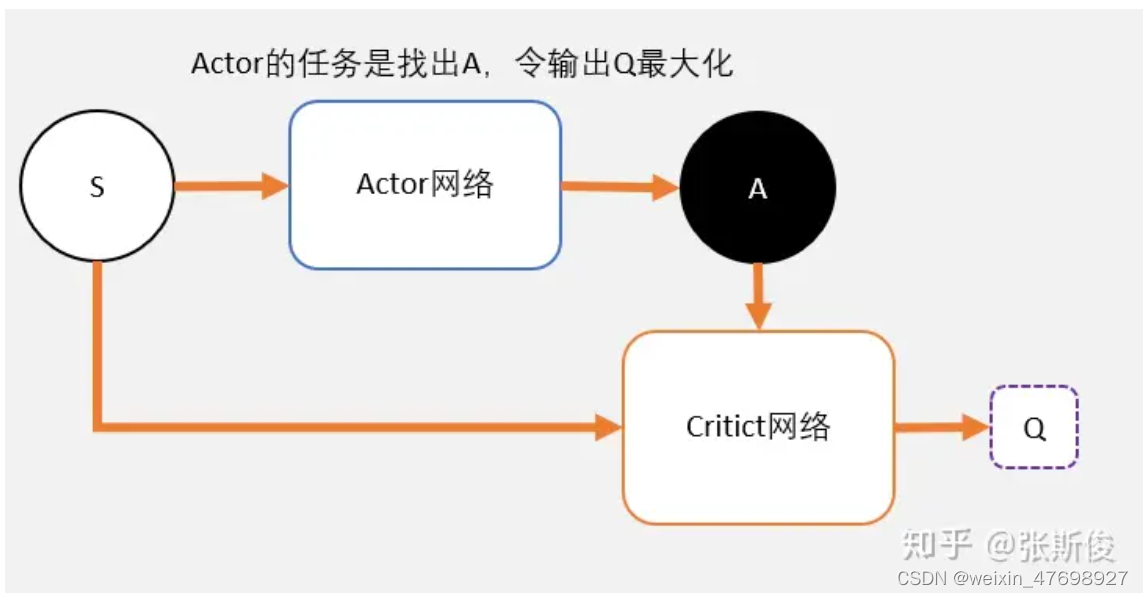
Actor在进行表演,Critic根据Actor的表演打分。Actor通过Critic给出的分数去学习和优化:如果Critic给的分数高,那么Actor会增加这个动作的输出概率;相反,如果Critic给的分数低,那么就减少这个动作输出的概率。那么Actor和Critic网络具体是怎么实现的呢?在这里要首先提到DQN。
DQN是更新的动作的q值:

在这里,由于maxQ(s',a')函数只能处理离散型的Q值,因此DQN不能用于连续控制问题原因。而DQN用神经网络解决了Qlearning不能解决的连续状态空间问题,因此同样的DDPG就是用神经网络解决DQN不能解决的连续控制型问题。我们把这里的神经网络用一个magic函数进行表示。也就是说,用一个magic函数,直接替代maxQ(s',a')的功能。
也就是说,我们期待我们输入状态s,magic函数返回我们动作action的取值,这个取值能够让Q值最大。这就是DDPG中的Actor的功能。
DQN的深度网络,就像用一张布去覆盖离散的Q值分布。这也是DDPG中Critic的功能。在这里,可以认为这个连续的Q值就是上面离散Q值的一个插值和拟合,请看下图:

如上图中的红色曲线,这条曲线指的是在某个状态下,选择某个动作值的时候,能获得的Q值。当我们把某个state输入到DDPG的Actor中的时候,相当于在这块布上做沿着state所在的位置剪开,这个时候大家会看到这个边缘是一条曲线。Actor的任务就是在寻找这个曲线的最高点,然后返回能获得这个最高点,也是最大Q值的动作,是一种梯度上升的更新过程。
好了,现在我们回到最初的DDPG。在实际进行优化更新的时候,更新的时候如果更新目标在不断变动,会造成更新困难。所以DDPG采用了固定网络(fix network)技术,就是先冻结住用来求target的网络。在更新之后,再把参数赋值到target网络。所以在实做的时候,我们需要4个网络。actor, critic, Actor_target, cirtic_target。

接下来,我们对图中的TD-error进行分析。
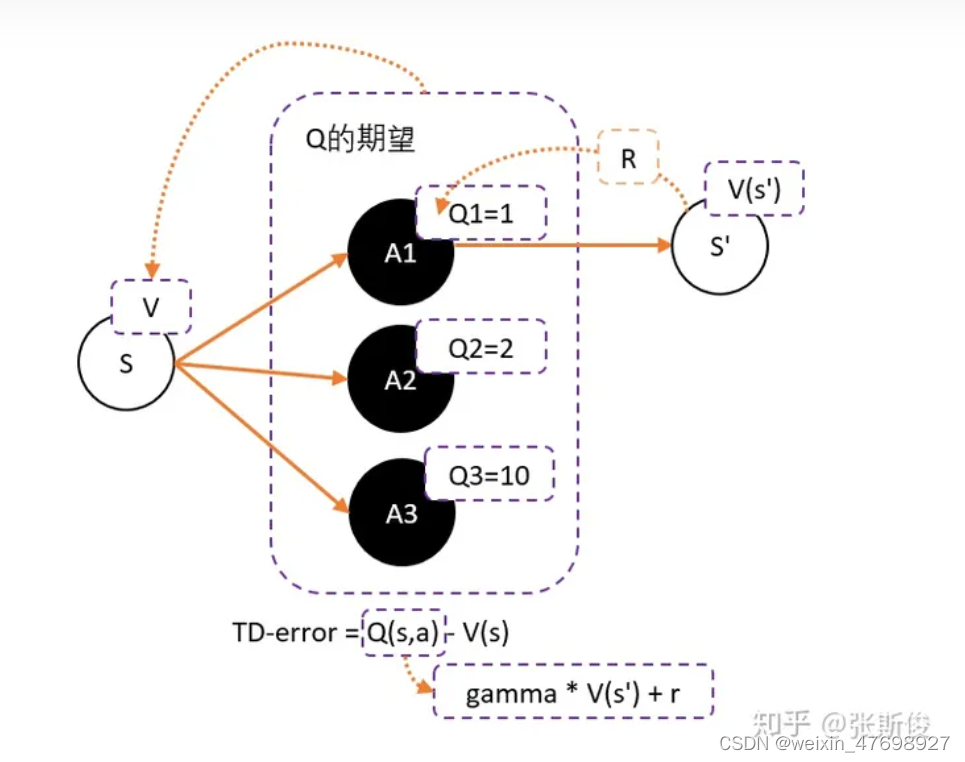
为了避免正数陷阱,我们希望Actor的更新权重有正有负。因此,我们把Q值减去他们的均值V。有:Q(s,a)-V(s),所以我们可以得到更新的权重:Q(s,a)-V(s)
马尔科夫告诉我们,很多时候,V和Q是可以互相换算的。Q(s,a)用gamma * V(s') + r 来代替,于是整理后就可以得到:
gamma * V(s') + r - V(s) —— 我们把这个差,叫做TD-error
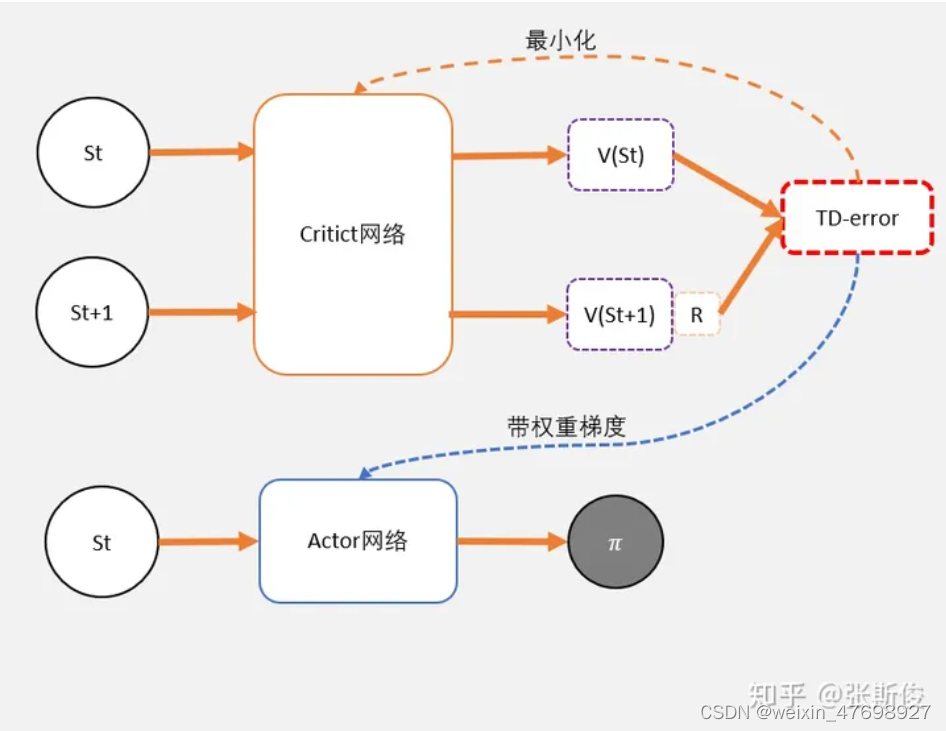
这个和之前DQN的更新公式非常像,只不过DQN的更新用了Q,而TD-error用的是V。Critic的任务就是让TD-error尽量小。然后TD-error给Actor做更新。TD-error就是Actor更新策略时候,带权重更新中的权重值。
算法流程
- 定义两个network:Actor 和 Critic
- j进行N次更新。
- 从状态s开始,执行动作a,得到奖励r,进入状态s'
- 记录Q的数据。
- 把Q输入到Critic,根据公式: TD-error = gamma * V(s') + r - V(s) 求 TD-error,并缩小TD-error
- 把TD-error输入到Actor,计算策略分布 。
注:文中内容,图片部分来源于知乎@张斯俊














 9519
9519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









