







MADDPG的架构
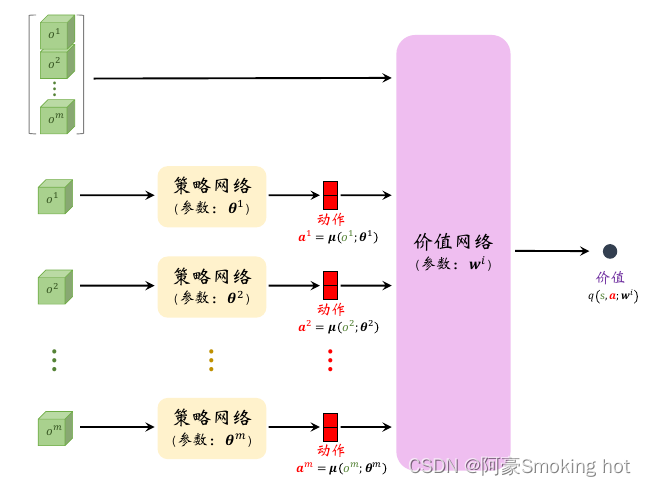
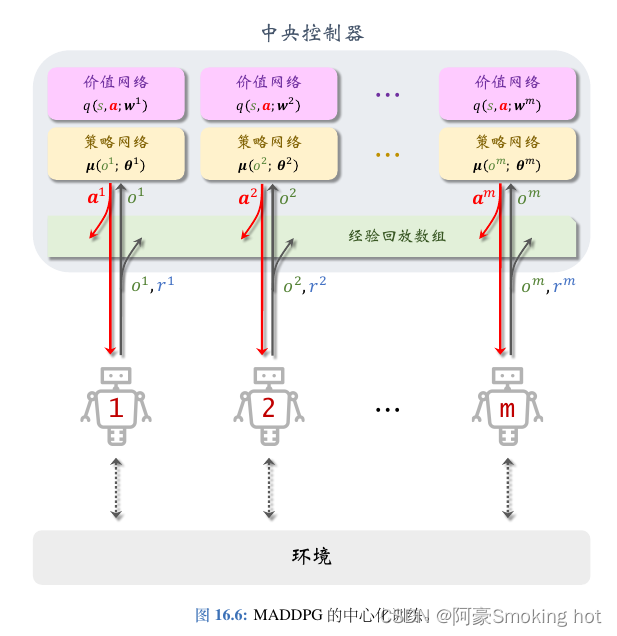
MADDPG采用的是“中心化训练+去中心化决策”的架构,是一种Actor-Critic方法。其中每个智能体都有一个价值网络和策略网络。
价值网络和策略网络
-
第i号价值网络(Critic)
输入:全局状态s、所有智能体的动作a(因为需要结合队友、对手的观测及动作才知道自身当前的动作好不好)
输出:一个实数(表示基于全局状态s,第i号智能体执行动作ai的好坏程度,可以指导第i号策略网络作出改进)
训练方式:TD算法
训练第i号价值网络需要用四元组<st、at、rt、st+1>,具体来说用到了下一时刻的全局状态St+1,所有智能体的策略网络,t时刻的奖励以及第i号智能体的价值网络. -
第i号策略网络(Actor)
输入:第i号智能体的观测oi
输出:第i号智能体的动作ai
训练方式:DPG
训练第i号策略网络需要用四元组<st、at、rt、st+1>,具体来说用到了全局状态St,所有智能体的策略网络以及第i号价值网络.














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









