







1. 数据操作
入门
1、导入pytorch
2、通过x = torch.arange()创建tensor,通过.shape或者.size()访问tensor形状。.reshape()可以将tensor转化为我们需要的形状,可以是2维也可以是多维的。
3、torch.zeros((x,y,z))可以创建形状是(x,y,z)的全0元素张量,torch.ones((x,y,z))创建全1元素张量,torch.randn()创建目标形状的正态分布张量。
4、torch.tensor([])能够直接给元素赋予特定值,torch.tensor([[],[],[]])能够嵌套列表。
运算
1、加减乘除的操作,+,-,*,/ 。幂的操作:**。
2、torch.exp(x)能够求e的指数。
3、torch.cat((X, Y), dim=0)按列将两个张量元素重排,torch.cat((X, Y), dim=1)按行将两个张量元素重排。
4、X == Y可以直接判断两个张量有哪些元素一致,返回布尔值。
5、.sum()能够返回元素的和。
广播机制
举例说明,有两个张量a,b,我们要求a+b。
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
a + b
结果:
tensor([[0, 1],
[1, 2],
[2, 3]])
索引和切片
与python一致,
X[-1]#返回最后一个元素
X[1:3]#返回第二和第三个元素,左闭右开区间
X[0:2, :] = 12
#对tensorX的第一行,第二行,全部赋值12
节省内存
这个有空补充吧,问题不大。
转换为其他Python 对象
a = torch.tensor(A)
a.item(), float(a), int(a)#都可以完成,int(a)会取整。
2. 数据预处理
读取数据集
目录指定
import os
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
#os.path.join能够生成一个目录地址并加载到环境变量中,makedirs能够创建这个地址对应的目标目录
文件写入
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每⾏表⽰⼀个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
以上操作创建了一个csv文件,包含指定写入内容。
import pandas as pd
data = pd.read_csv(data_file)
#python一般用pandas,read_csv读取文件
处理缺失值
刚刚保存的csv文件有缺失值,这些缺失值需要处理,一般的处理方式是插值或者删除。
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean())
#inputs.mean()会用整列的均值补全
print(inputs)
NumRooms Alley
0 3.0 Pave
1 2.0 NaN
2 4.0 NaN
3 3.0 NaN
#均值补全
因为Alley列只有两个类别,Pave以及NaN,所以可以采取ont-hot编码。
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)
#get_dummies能够进行one-hot编码,dummy_na能够对NaN缺失值数据也编码。
转换为张量格式
import torch
X, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
#因为初始的数据格式是pandas格式的,需要先使用.values转成array格式再转换成tensor
练习
需要去删除含有最多缺失值的列
常见的思路是知道每一列的缺失值,得到这一列的Index,依据Index删除这一列。
def drop_max_nan_col(data):
nanmaxid = data.isna().sum(axis = 0).idxmax()
#这里的isna()用来寻找缺失值,和isnull()没有任何区别,.sum()函数用来统计NaN的数量,idxmax()返回最大值的索引
ndata = data#为了不改变原数据,所以新建ndata
ndata = ndata.drop(nanmaxid, axis = 1)
inputs, output = ndata.iloc[:,0:-1], ndata.iloc[:,-1]
inputs = inputs.fillna(inputs.mean())
inputs = pd.get_dummies(inputs, dummy_na = True)
X, y = torch.tensor(inputs.values), torch.tensor(output.values)
return X, y
3. 线性代数
标量
标量由只有⼀个元素的张量表示。
x = torch.tensor([3.0])
向量
可以将向量视为标量值组成的列表
x = torch.arange(4)
可以通过索引来访问任意张量,len()可以访问张量长度。
矩阵
通过reshape即可创建矩阵
A = torch.arange(20).reshape(5, 4)
A.T #通过A.T来访问A的转置
张量
向量可以被认为是⼀阶张量,矩阵是⼆阶张量,可以通过reshape构建高阶张量。
X = torch.arange(24).reshape(2, 3, 4)
张量算法的基本性质
1、两个相同矩阵相加
2、两个矩阵的按元素乘法称为哈达玛积(Hadamard product)(数学符号⊙),对应位置的元素相乘。
3、将张量乘以或加上⼀个标量不会改变张量的形状,其中张量的每个元素都将与标量相加或相乘。
降维
这里讲的都是均值降维或者和降维,实际意义不大。
点积(Dot Product)
torch.dot(x, y)
#等同于矩阵乘法再相加
torch.sum(x * y)
矩阵向量积
torch.mv(A, x)
矩阵积(矩阵乘法)
torch.mm(A, B)
范数
L2范数:
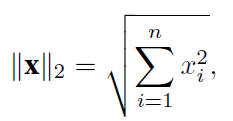
u = torch.tensor([3.0, -4.0])
torch.norm(u)
L1范数
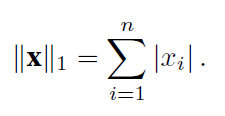
torch.abs(u).sum()
4. 微分
导数和微分
以下是函数f的导数的定义:
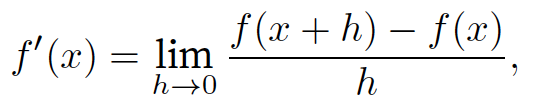
如果f′(a)存在,则称在a处可微。
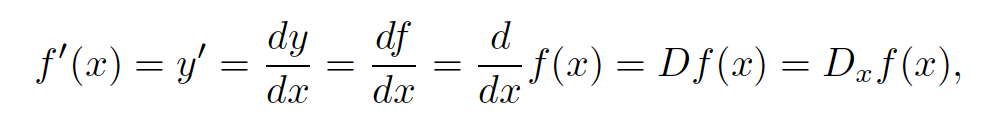
原文中有一个绘制曲线以及在某点切线点例子,可以参考。
偏导数
y = f(x1, x2, . . . . , xn)是⼀个具有n个变量的函数。y关于第i个参数xi的偏导数.
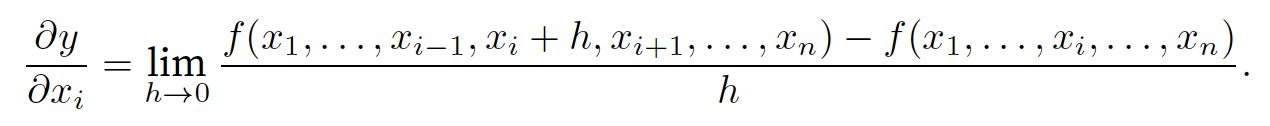
梯度
可以连结⼀个多元函数对其所有变量的偏导数,以得到该函数的梯度(gradient)向量,函数f(x)相对于x的梯度是⼀个包含n个偏导数的向量。
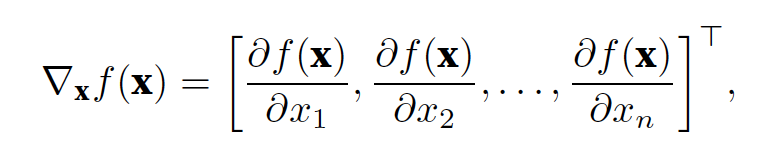


链式法则
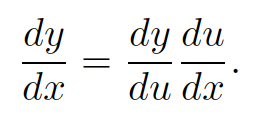
小结
本章节对一些基本概念进行了总结,梯度的部分值得反复阅读思考。
5. 自动求导
简单例子

⾮标量变量的反向传播

分离计算
分离了变量y,看作常数计算

Python控制流的梯度计算
即使构建函数的计算图需要通过Python控制流(例如,条件、循环或任意函数调⽤),我们仍然可以计算得到的变量的梯度。
小结
深度学习框架可以⾃动计算导数。为了使⽤它,我们⾸先将梯度附加到想要对其计算偏导数的变量上。然后我们记录⽬标值的计算,执⾏它的反向传播函数,并访问得到的梯度。
6. 概率
基本概率论
概率论公理

处理多个随机变量
联合概率
条件概率
⻉叶斯定理
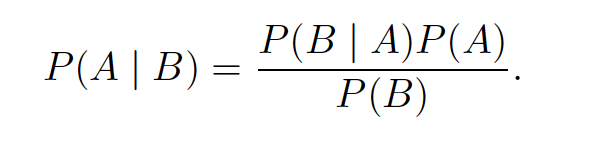
边际化
独立性
期望和差异
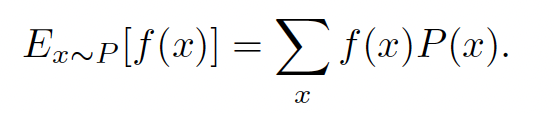
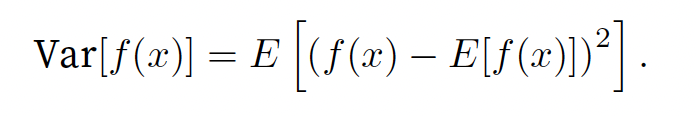















 4038
4038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









